(この記事は「Salesforceからエンジニアになった人が学ぶWebシステムの基礎」シリーズの第1回目の記事です。よろしければ最初に序章を御覧ください)
はじめに
Salesforceというデータベース
Salesforceは言うまでもなくSFA/CRMをコアアプリケーションとするSaaS形式のサービスであるのですが、実際には業務に関連するデータを格納するための汎用データベースとしての側面があり、これによってそのユースケースを単なるSFA/CRMの領域を超えたものにしています。
いわゆる「データベース」というと、エンジニアの中にはMySQL/PostgreSQL、あるいはOracle/MS SQLServerなどの名前が出てくる人もいるかも知れません。これらはすべてデータベース管理システム(DBMS)というソフトウェアですが、その中でもリレーショナル・データベース(RDBMS)という現在主流のデータベースの種類のうちの1つです。RDBMSは長年に渡って様々な業務システムにおいて実用的な性能を提供しつづけており、そのエンジニアリングは1つの確固たる分野になります。
Salesforceのデータベースというのは、このような一般的なDBMS/RDBMSとは異なる独自のものになっていますが、いくつかの仕組みや性質をこれらのDBMSから引き継いでいます。
データベースのインデックスとその目的
Salesforceが一般的なDBMSから引き継いでいる仕組みのうちの、今回取り上げたいのはインデックスというものです。
このインデックスですが、Salesforceの世界ではあまり最初は表立って出てくることはないにも関わらず、とある瞬間から急に出現していきなり重要な位置を占めてきます。
英語の「index」という単語が通常「索引」と日本語に訳されるように、これは辞書などにある索引と同じ役割と考えてもらってもよいでしょう。つまり、索引は辞書の中にある言葉を検索するためにあらかじめ作成されている見出し・目次のようなものですが、これと同じ役割のものがデータベースにも存在しています。それがインデックスです。
もしデータベースにインデックスがない場合ーーーそれは辞書を毎回頭からページをめくって言葉を探すようなものです。効率がよいとは言えません。もちろん辞書のページ数が100ページくらいのものであれば頑張って探せなくもないでしょうが、日本国語大辞典(全13巻)を相手にするのであればそのような人生は一度考え直したほうがよいでしょう。
つまりインデックスは、大量のデータがデータベースにあるときに、効率よくデータベースからデータを検索するために必要とされるものです。そのため、Salesforceの世界でこの存在を意識するには、まず対象の業務データがインデックスを必要とするくらいに大量になっている必要があります1。
事前準備:用語の整理
Salesforceで使われている用語は、通常のDBMS/RDBMSで一般的に用いられている用語とは異なるためそのまま説明すると混乱することがありえます。ここではSalesforceをデータベースの1つとして見る時、一般的なRDBMSとはどのように名前が違うのかあらかじめ書いておきます
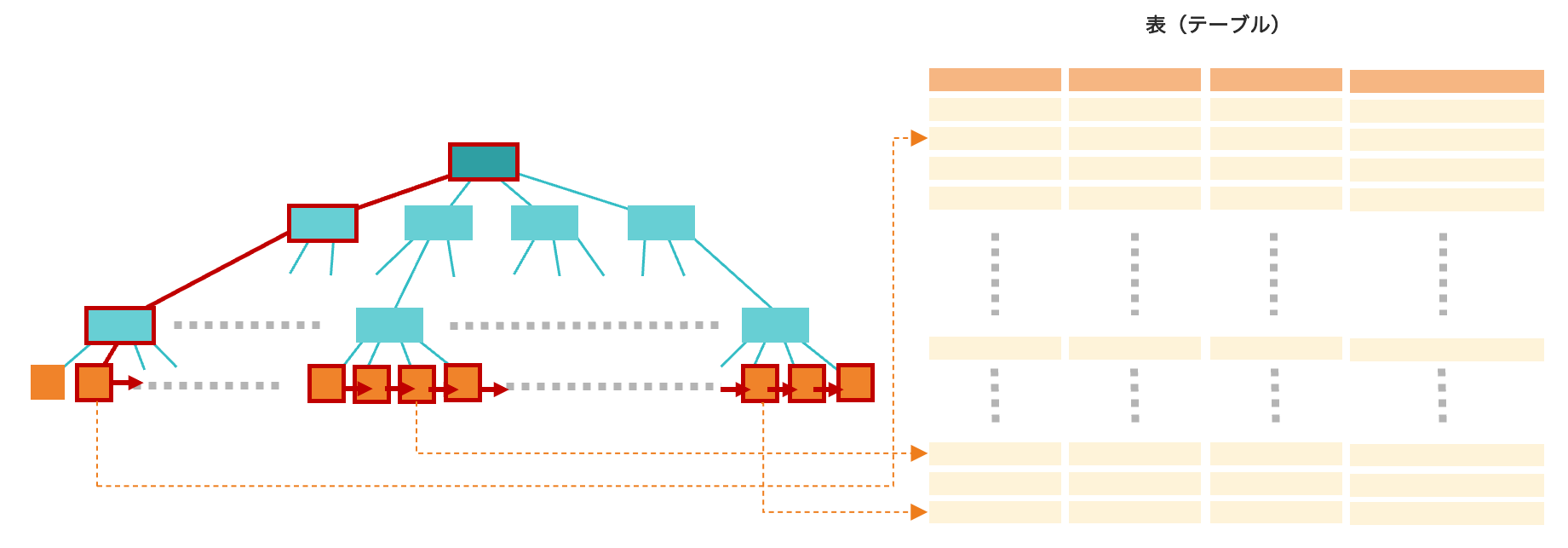
| Salesforceでの名前 | RDBMSでの名前 | |
|---|---|---|
| データの入れ物 | オブジェクト | 表(テーブル) |
| データの属性 | 項目 | 列(カラム)、属性 |
| 1件1件のデータ | レコード | 行、レコード |
インデックスの詳細解説
インデックスの役割
たとえば漢字辞典において「『氵』を部首とする漢字をしらべたい」という時に「部首」という属性で索引を持っていると便利なように、検索対象となる属性の値をもとにインデックスは通常作られます。そして、漢字辞典で「部首」の索引と「よみ」の索引が別々にあるように、インデックスは通常その属性ごとに作成されます。
このような辞書的な索引のインデックスは属性値が何かの値に一致するデータを検索するためのものでしたが、それ以外にもたとえば数値や日付時刻属性をもつデータに対してある範囲内の属性値をもつデータを取得したい、というような場合にもインデックスは使われます。
さらに、インデックスは、ある属性の値でデータを並び替えしたい、というような場合にも利用できます。後で述べますが、インデックスという仕組みはあらかじめその属性の値でデータを並べておくようなものなのです。インデックスがその属性に対して作ってあると、データの並び替えを毎回することなくデータを検索することができますので、効率がよくなります。
インデックスの構造
あまり概念的だとかえって分かりにくくなる可能性もあるので、実際のインデックスの構造の話も少ししましょう。
インデックスは通常ツリー型の構造を作ります。これはツリーの構造であると少ないアクセス数で目的のデータに辿れるという性質を利用したものです2。

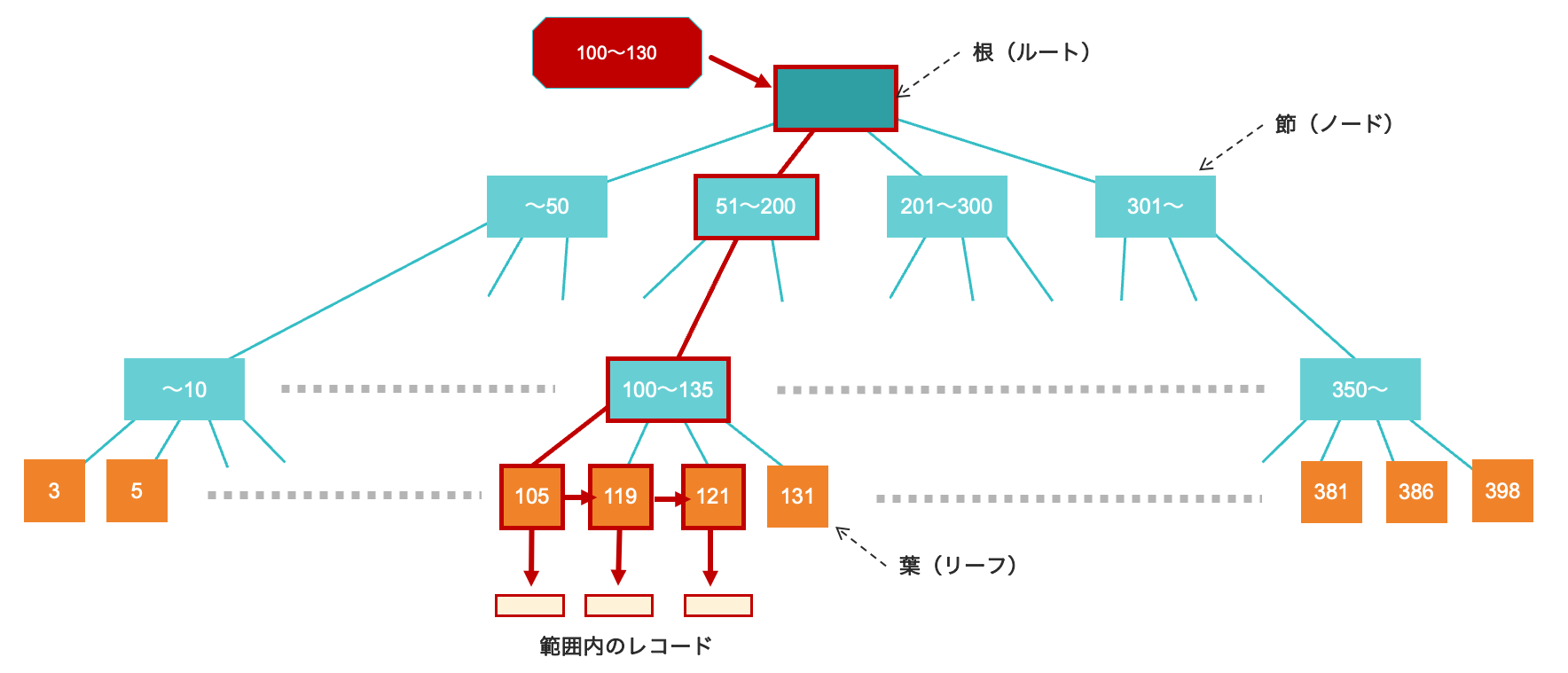
最初は根(ルート)の部分から出発し、節(ノード)の枝分かれの際に値の比較を行い、検索する値を含むノードを選んで辿っていきます。このようにして最後に葉先(リーフ)に到達するまで行います。
葉先には実際のレコードの所在地(辞書で言うならページ番号のようなもの)が書いてあるので、簡単にレコードにアクセスできるというわけです。
このツリーは値の大小関係で枝別れをしているため、結果として葉先のデータはその値の順序どおりに並び替え済みの状態になっています。ツリーの葉は隣の葉をたどることもできるようになっており、これにより順序をたどったアクセスが大変高速になります。

インデックスのデメリット
インデックスがついている属性による検索が高速になったり並び替えの効率が良くなるのであれば、あらかじめすべての属性にインデックスを付けたらよいのでは、と思う人もいるかも知れません。
しかしながらインデックスには検索が高速になるというメリット以外に、データの追加や更新が遅くなるというデメリットがあります。実際に先のようなツリーの構造を毎回データが追加更新されるたびに作ったり再構成したりするわけなので、無闇矢鱈とインデックスを付けていては性能に問題が出る可能性があります。なのでインデックスは検索に必要な属性に対して最低限のものを用意するのが通常です。
インデックスの使われ方
ほとんどのデータベース管理システムにおいて、インデックスは通常はユーザが直接使うようなものではありません。データの検索の際に必要があればデータベースが適切に使ってくれるものです。なので、逆にどのような時に使われるのかを知っておかないと、パフォーマンスがうまく出ないなどの状況に対処できません。
ここではデータベースがどのようなときにインデックスを使ってくれるのか、そしてその際にインデックスはどのような働きをするのか、その例を示します。
一致検索
まず、ある属性の値が一致するデータをデータベースから検索しようとするとき、その属性のインデックスが作られていると、そのインデックスが使われる可能性があります。

もしインデックスを使わない場合は、データの先頭から最後までその属性に一致しているかどうかを見ていく必要があります。もし1件しかないとわかっている場合は見つかった時点で打ち切ることもできますが、件数が指定されていない場合は本当の最後までみていかなければいけません。
インデックスがあれば、ツリーの節(ノード)をたどるだけで目的のデータにたどり着くことができますし、もしそのデータが1件以上あるのならツリーの葉(リーフ)を横方向に辿っていけばよいので、とても効率的です。
複数の値に対する一致検索
複数の値に一致する検索(〇〇、△△、および✗✗のうちのいずれかに一致する)の場合、単にインデックスを使ってその検索する値のパターン数分同じ一致検索を行うだけです。インデックスがあれば全部のデータを先頭から最後まで調べるようなことはしないでOKです。
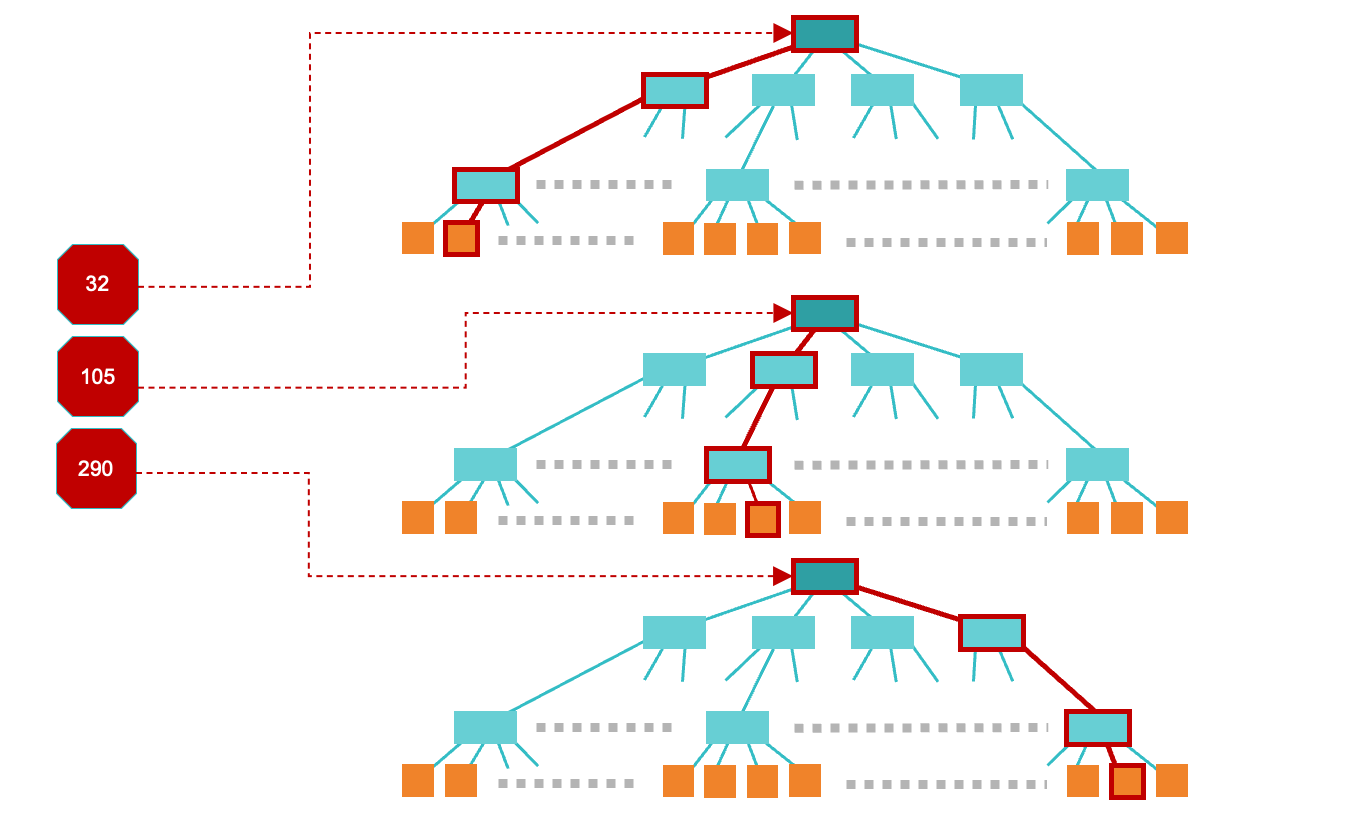
範囲検索
ある属性の値が一定の範囲内にあるようなデータをデータベースから検索しようとするときもインデックスが使われる可能性があります。
範囲検索の場合は、まず、下限3の値を元にデータの一致検索とおなじように検索値の比較を行い、葉(リーフ)にたどり着きます。その後、右方向にリーフを移動し、リーフの指し示すデータを取得していきます。インデックスのツリーのリーフはあらかじめその属性値の順番に並べられた状態になっているはずなので、最終的に上限の値を超えるまでリーフの移動を続ければ、それはその範囲内のすべてのデータになるはずです。
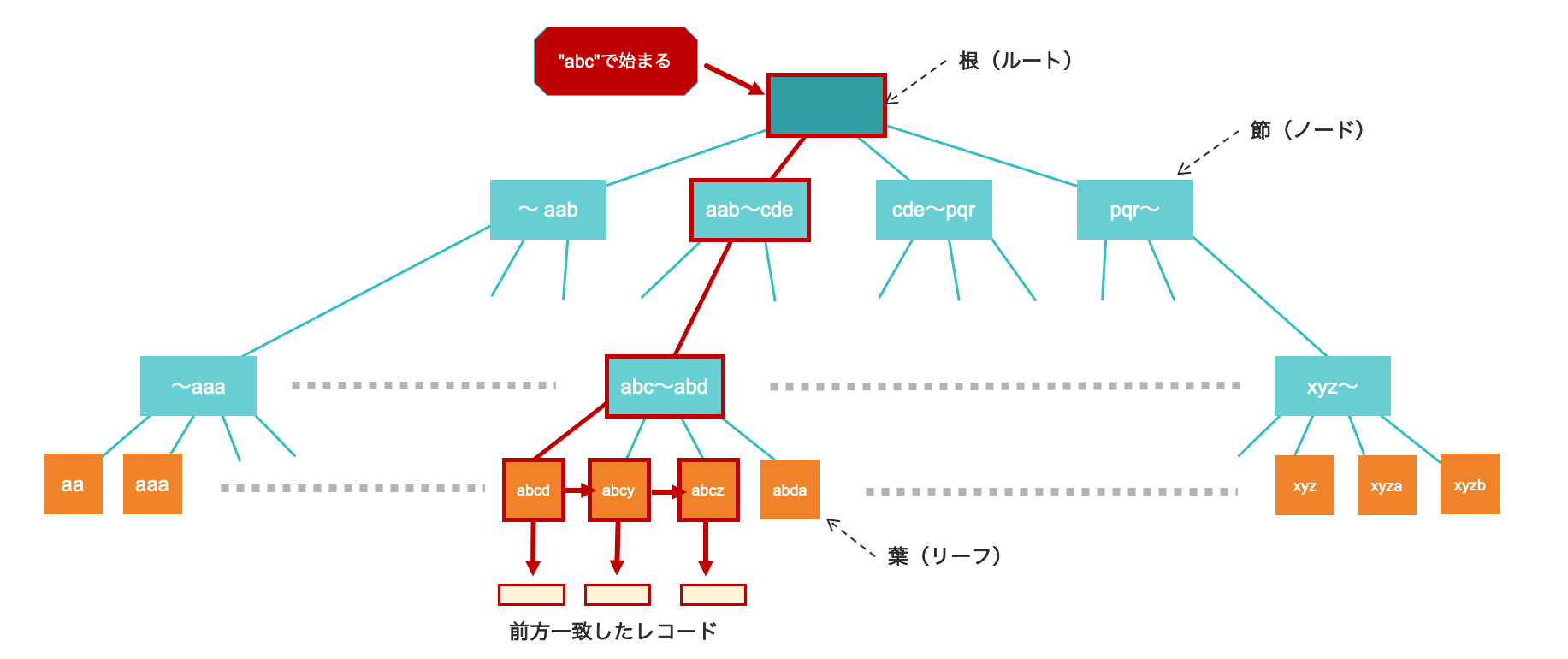
テキストの前方一致検索
時々、テキスト属性に対して文字列の前方一致(〜で始まる)を条件としてデータの検索をすることがありますが、このような場合にもインデックスが使われる可能性があります。
しかしながら、部分一致(〜を含む)や後方一致(〜で終わる)の条件での検索に対してはインデックスを使うことはできません。その理由は、前方一致検索は文字列を辞書順で並べて大小の比較をしたときに範囲検索として取り扱えるからです。
例えば、名前が文字列"abc"で始まるデータの検索を行う場合は
文字列 "abc" で始まる
⇒
辞書順で言葉を並べた時に "abc" 以降かつ "abd" より前に出現する
と検索条件を置き換えることができます。
部分一致や後方一致の場合にはこのような解釈はできませんので、インデックスを使うことはできません。
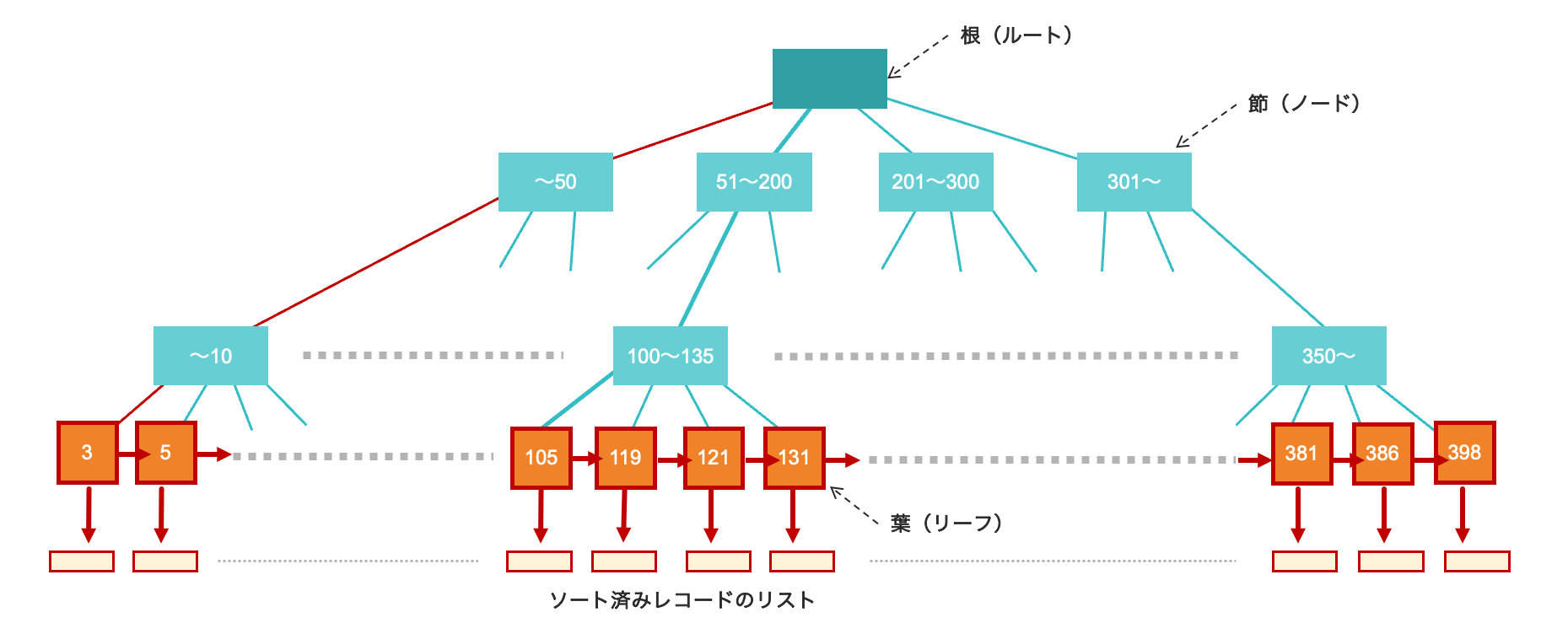
並べ替え
ある属性の値を基準としてデータを並べ替えて取得したい時、その属性にインデックスが張られていれば、インデックスが使われる可能性があります。これはインデックスがツリーによってデータをその属性の値の順番であらかじめ並べた状態にしていることを考えれば自然なことです。
一意制約
最後に、これは検索用途ではないけれども重要なインデックスの利用例です。
DBMSにおいては、ある属性の値が必ずそのデータの中で1つしかないような制約を設けたいケースがよくあります。このような制約を一意制約と呼びますが、これを実現するのにも実はインデックスが使われています。
このインデックスは検索するときではなくデータをデータベース内に挿入する時に利用されます。挿入する前にあらかじめ新しく挿入するデータの属性値でインデックスを検索し、もしインデックスからその値が見つかれば、それはすでに登録されているデータがあるということになり、一意制約に違反するとしてデータベースが挿入を却下します。
インデックスと実行計画
一番効率的な検索方法は?
さて、インデックスはデータベースでの大量のデータを効率的に検索するのに有効であるという話をしました。しかし本当にいつも効率的になるのでしょうか?例えば『金額が10,000円以上かつ商談名に「ライセンス」という文字列を含む商談』を商談テーブルから検索する場合を考えましょう。
ここで「金額」属性にはインデックスが付けられているとします。また商談には10,000円以上の金額である商談データが全体件数のうち95%くらい入っているとします。
もしこのような検索を「金額」属性のインデックスを利用して行った場合のことを考えてみましょう。インデックスの走査は最初に左から5%のリーフに到着した後、横方向にリーフを辿っていきます。リーフをたどるごとにデータの所在地を確認して参照し、そのデータが残りの条件(「商談名」に「ライセンス」文字列が含まれるか)にマッチするかを確認しながら、右端のリーフに到着するまで繰り返します。
10,000円以上のデータは全体の件数の95%くらいありましたため、結局ほぼすべての商談データをスキャンすることになりました。しかも毎回リーフに書いてあるデータの所在地をもとにそのデータを読みこんで確認するステップを踏んでいます。
これであれば、元の商談データのリストを上から順番に読みながら比較していったのとデータ量的にもそれほど変わりませんし、むしろそちらのほうが楽だったかもしれません。詳細は割愛しますが、データの所在地を確認しながら情報を1つ1つ読んでいくより、連続した情報を順番に読んでいったほうがアクセス効率が良いことが実際に知られています。
つまり、インデックスはいつでも何時であっても効率が良いわけではなく、インデックスによってデータが一定量以下に絞り込まれることがわかっている場合にのみ使うのが妥当だということです。
インデックスにはこのような性質があるため、ある検索に対してインデックスを利用するかどうかは、データの中身を知らないユーザが決定するのはなかなか困難です。そのためインデックスを利用するかどうかについてはDBMSが決定することがほとんどです。DBMSは統計的な情報からこのような絞り込みの概算を検索前にあらかじめ推定できるようにしており、インデックスを使うのか、使うのであれば複数あるインデックスのうちどれを使うのか、などを決定します。これを実行計画と呼びます。
実行計画を知ることは、実際にどのような検索がDBMSにおいて内部で行われるのかを知ることになります。つまり実行計画はデータベースに対するパフォーマンス問題が発生したときの解決の足がかりになります。パフォーマンス問題が起きたとき、DB管理者は検索文から実行計画を探り、その実行計画に問題がないかをチェックします。もしインデックスを与えることで改善できる可能性があるのであれば、データベースの属性にインデックスを付与した後で再度同じ検索文に対して実行計画を取得し、改善を行います。
上限件数指定による検索の打ち切りと実行計画
データベースへの検索の際に上限のデータ件数を指定できる場合、たとえインデックスがなかったり使えるような状況でなかった場合でもパフォーマンスが向上する可能性があります。
インデックスが使われない場合、データの検索時にはテーブルにあるデータを上から順番に調べていく(テーブルフルスキャン)ことになりますが、マッチするデータが上限件数に達した段階でそのチェックを停止することができます。たとえばテーブル内に数百万件のデータが入っていたとして、何も条件を指定せず100件を上限件数として取得するのであれば、最初の100件を見るだけでデータの検索は完了してOKです。
また、インデックスはあるけれども絞り込み度がそれほど大きくない検索の場合であっても、上限件数が指定されていればいくつかのリーフをスキャンするだけでスキャンを終了できるため、テーブルのフルスキャンよりも効率的になる可能性があります。
DBMSにおける実行計画の算出では、このような上限件数の条件も考慮して各検索方式のコストを計算し、最良の検索方式を選択することが一般的です。
Salesforceにおけるインデックス
さて、ここまで一般的なDBMSにおけるインデックスの役割と使われ方、および検索パフォーマンスに与える影響について見てきました。ここであげたものはすべてSalesforceにおいてもほぼ同様に機能しており、実際にSalesforceでのレコードの検索の際に使われています。
ただし、一般的なDBMSとSalesforceが大きく異なるのは、一般的なDBMSではインデックスの作成はデータベースの管理者が行えるのに対し、Salesforceでは管理者が自由に項目に対してインデックスを作る直接的な方法は存在しないということです。
ただ、ここで「直接的な方法」といったことに注意してください。つまり、間接的には存在します。Salesforceでは直接的にインデックスの作成はできなくともあるルールに従っていればその項目にはインデックスが自動的に付くようになっています。
Salesforceでインデックス付与のルール
Salesforceで項目にインデックスが付与されるためには、項目が以下の種類の項目である必要があります。
- ID項目
- 名前項目
- 参照/主従関係項目
- 作成日/最終更新日項目4
- 外部ID項目
- ユニーク(一意)項目
- いくつかの標準オブジェクトの項目(例:取引先責任者/リードのメール項目など)
これらのうち、「外部ID項目」についてはSalesforce管理者が項目に対して設定画面で直接的に設定できるものです。そのため、インデックスを利用するために項目定義の「外部ID:外部システムの一意のレコード識別子として設定する」にチェックを付けるという運用がなされているケースがよくあります。もちろん本来の外部IDの用途はシステム連携などのためのものであるので、あくまでカジュアルなハックだと思っておくのがいいと思います(外部IDはインデックスを作るための機能だ、などという本末転倒の認識にならないように気をつけましょう)。


また項目の定義において「ユニーク:値の重複を許可しない」にチェックをつけた項目はユニーク(一意)項目となり、インデックスが付けられます。
一般的に一意制約を実現するにはインデックスを用いてチェックを行うということを先に説明しましたが、まさにこの通りです。
このユニーク設定についてもSalesforce管理者が設定画面より項目に対して直接設定できるものであるため、一意になるという条件が当てはまるのであればこれもインデックス作成のための手段となりえます。


明示的なインデックスの付与方法
Salesforce管理者が直接的に項目に対してインデックスを付与することはできない、と言いましたが、もし明示的にある項目にインデックスを付与したければ、Salesforceサポートへ連絡することによってカスタムインデックスを付与してもらうことが可能になっています5。
カスタムインデックスについては数式項目についても付与が可能というのが特徴的です。ただしその数式項目は「決定性の」数式項目である必要があります。つまり現在のユーザの属性値や日時情報など、検索を実施したときのコンテキストに依存するような情報を元に計算を行う数式の項目は「非決定性数式項目」とされカスタムインデックスを作成できません。
このような制約は、インデックスが属性の値を元にあらかじめツリー構造を作っておくものだ、ということを理解していれば自然に理解できるでしょう。つまり、属性の値がコンテキストによって変化するようではそのような構造を事前に作っておくことは不可能だから、というののが理由になります。
自動的に作成されるインデックス
いつからか正確なことはわかりませんでしたが、2017年頃から「Auto Query Tuner (AQT)」という仕組みがSalesforceには備わっており、頻繁に利用されるクエリの内容に応じて自動的にカスタムインデックスを付与してくれるようになっているようです。
項目に対するインデックスの確認方法
Salesforce設定のオブジェクトマネージャよりオブジェクトの設定画面を開き、「項目とリレーション」のリストテーブルの中に「インデックス付き」というカラムがありますので、そこにチェックがついていればその項目にはインデックスが付与されている、とわかります。

おそらくSalesforceは本当はインデックスの存在自体をSalesforceの管理者には隠したかったのかもしれません。事実、少し昔のSalesforceでは、オブジェクトの設定画面で項目のインデックスを確認することはできませんでした。現在はオブジェクトマネージャから確認できるようになっています。これは大量データがあるSalesforce組織においてはインデックスを意識せずに運用するということは難しいということからの現実的な判断であろうと推測しています。
Salesforceでの実行計画
Salesforceで実行計画を知るためには、検索のためのクエリ文(SOQL)を入手する必要があります。ApexコードなどでSalesforceプラットフォーム上でカスタム開発をしているのであればそのSOQLをそのまま出力すればよいでしょう6。
SOQLを入手した後は、開発者コンソールの中の「クエリプランツール」を立ち上げることで、実行計画の詳細を確認できます。クエリプランツールを使用するには、最初にHelp > Preferenceメニューから「Enable Query Plan」を有効にした後、Query EditorタブからエディタにSOQLを入力して [Query Plan (クエリプラン)] ボタンを押すだけです。これで、SOQLのクエリプラン=実行計画が返されます。
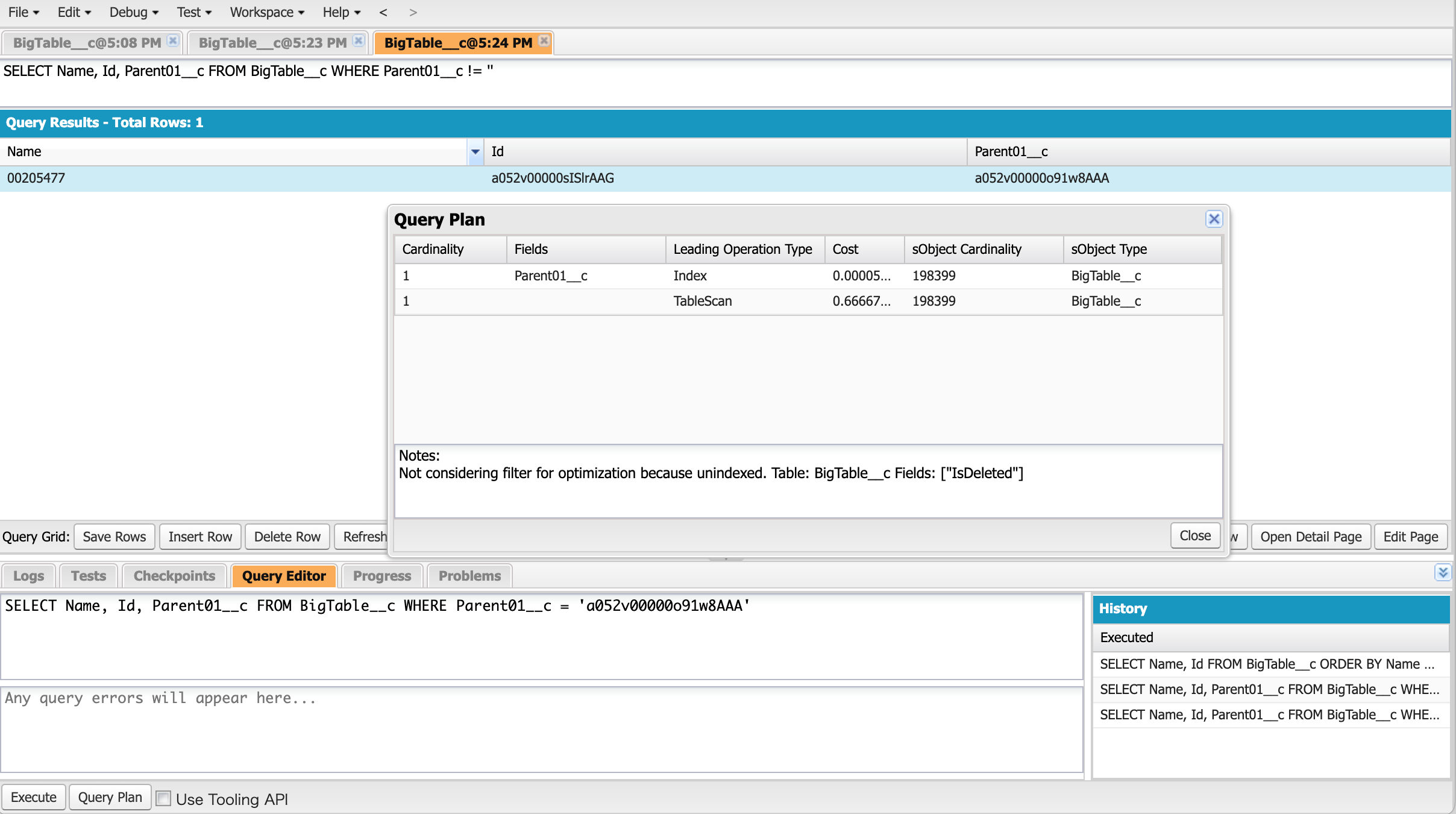
[Query Plan]ダイアログに表示されたいくつかのプランのうち最初のもの(=最も「Cost」の値の少ないもの)が検索実行時に使われることになります。ここでこのプランの「Leading Operation Type」の値が「Index」となっていれば「Fields」項目のインデックスを使ってデータを検索しますし、「Table Scan」となっていればインデックスを使わずにオブジェクト内のレコードを先頭から順番にチェックしながら検索することになります。
まとめ
Salesforceはデータベースとしての性質を一般的なDBMSから引き継いでおり、そのうちの1つとしてインデックスおよびそれにともなう実行計画の仕組みがあります。Salesforceにおいて大量のレコードデータを相手にする場合、インデックスという仕組みの構造と役割、利用のされ方を理解して押さえておく必要があります。
参考資料
-
幸か不幸か、現在のSalesforceは数万件程度のデータであればインデックスは関係なくともストレスない速度でレスポンスを返してきます。中小の企業を中心にそのようなサイズ内で業務が収まることも多く、インデックスの存在を意識する機会は少ないとも言えますが、そのことがいざインデックスを意識する必要が出た時にSalesforceエンジニアを困惑させることに繋がっている可能性は否めません。 ↩
-
ツリー構造はよくコンピュータ科学の分野で用いられるデータ構造です。このようなデータ構造に関しては初学者向けのものも含めて書籍がいろいろあります。ここではツリーの「少ないアクセス数で目的のデータに辿れる」という性質だけ抑えておけばよいですが、なぜそうなのか気になった方は書籍などで調べてみてください。 ↩
-
下限か上限かはどちらでもいいですが簡単化のために下限としています ↩
-
実際には最終更新日項目は「SystemModstamp」項目のインデックスを利用するため、大小比較の際の適用条件に注意が必要になります。詳しくは「初期設定における SOQL 実行時の LastModifiedDate と SystemModStamp のインデックス利用について」を参照ください ↩
-
ただし項目の種別などの条件はあります。詳細は「カスタムインデックスが必要な場合の依頼方法について」を参照してください ↩
-
ただし、フローやレポートなどではレコードの検索時にどのようなSOQLが使われているかは隠蔽されているため、SOQLを入手するのは困難です。また、3rd Party製のツールを使っている場合にもそのような生のクエリ文を得ることはユーザ側からはなかなか難しい可能性があります。 ↩