はじめに
少し前になりますが、ディープラーニングを使って動き錯視を再現するという研究が出ていました。
https://www.frontiersin.org/articles/10.3389/fpsyg.2018.00345
概要としては、動きを予測するよう学習したモデルに、人が動き錯視を起こす静止画を見せると、錯視で感じるものと類似した動きが予測された、という内容です。

(こちらの図は北岡明佳氏の文献より引用しています)
ここでニューラルネットワークにやらせているのは、「動画の中の1枚から次の動きを予測する」というタスクになるわけですが、推定の手がかりとなる情報には下記のようなものがあります:
- セマンティックな情報(例:クルマの形→前に動きそう)
- モーションブラー
- 映像コーデックが動きを扱うときの癖
- 動きやコントラストなどの統計量
錯視図形を見て直感的に思うところは、1のセマンティックな情報はおそらく使われていないという事です。
残りの項目については、比較的シンプルな推論になるので、先行研究のようなPredNet(ConvolutionalLSTM)はモデルとしては高級すぎるように思います。
今回、4の動きやコントラストの統計量だけから予測するモデルを作ってみたところ、ある程度動き錯視が再現されたので、記事にしておきます。(先行研究があるかもですが、趣味の研究なのでご容赦ください)
モデル
簡単のために1次元で説明します。2次元でも同様にすればOKです。
動きベクトルの確率分布を$P(v)$とし、現在の画像を$I(x,t)$とします。このとき$I(x,t+\delta t)$の期待値は、
E[ I(x,t+\Delta t) ] = \int I(x-v\Delta t,t)P(v)dv
簡単ですね。現在の画像に$P(v)$を畳み込んだ形が次の画像の予測値というわけです。
$P(v)$はデータを元に決めたほうがいいですが、おそらく等方性と$P(v)$の$|v|$に関する単調減少は仮定してよさそうで、これは単なる平滑化フィルタになります。実際、PredNetの1フレームのみからの予測でも、画像がボケていく傾向がみられます。
ここでは$P(v)$として、ガウス分布を仮定しておきましょう。
実験
先行研究にならい、動き予測の結果と現在のフレームとのオプティカルフローを求めます。
結果から先に掲載します。下図は各線がオプティカルフローを拡大表示したもので、丸がついている方の端点が予測値です。
中心付近はやや乱れていますが、外側は比較的きれいに回転が予測されていることがわかります。左側の図形が反時計回り、右側の図形が時計回りと予測しています。これは錯視の回転方向と一致しています。

実験に使ったコードはこちらです。オプティカルフロー抽出はOpenCVのチュートリアルコードほぼそのままです。
import cv2
import numpy as np
fname = "circle3.png"
keypoints = 200
sigma_kp = 2.5
sigma = 2.5
mag = 100
frame = cv2.imread(fname)
# params for ShiTomasi corner detection
feature_params = dict( maxCorners = keypoints,
qualityLevel = 0.3,
minDistance = 7,
blockSize = 7 )
# Parameters for lucas kanade optical flow
lk_params = dict( winSize = (15,15),
maxLevel = 2,
criteria = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# Create some random colors
color = np.random.randint(0,255,(keypoints,3))
# Take first frame and find corners in it
old_frame = np.copy(frame)
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
tmp = cv2.GaussianBlur(old_gray,(11,11),sigma_kp)
p0 = cv2.goodFeaturesToTrack(tmp, mask = None, **feature_params)
while True:
frame = cv2.GaussianBlur(frame,(11,11),sigma) # Predict next frame
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# calculate optical flow
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# Select good points
good_new = p1[st==1]
good_old = p0[st==1]
# draw the tracks
display = np.copy(frame)
for i,(new,old) in enumerate(zip(good_new,good_old)):
new = mag*(new-old)+old
a,b = new.ravel()
c,d = old.ravel()
display = cv2.line(display, (a,b),(c,d), color[i].tolist(), 1)
display = cv2.circle(display,(a,b),2,color[i].tolist(),-1)
cv2.imshow("",display)
k = cv2.waitKey(0) & 0xff
if k == 27:
break
# Now update the previous frame and previous points
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1,1,2)
考察
円周上の輝度プロファイルをプロットしてみると、概ね青色の線のようになります。
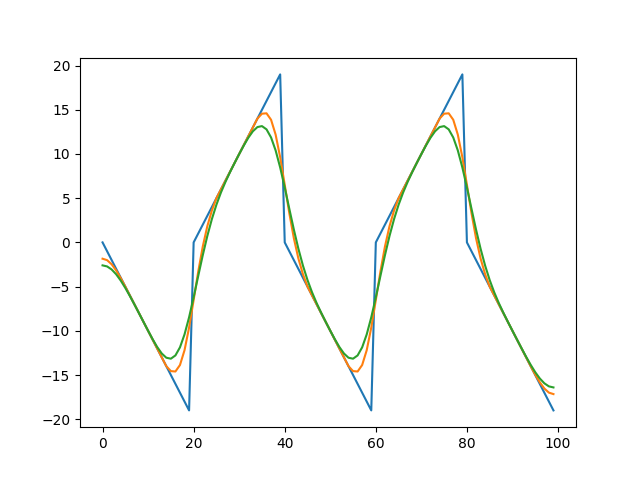
これに対して次フレームの予測がオレンジ色の線、さらに次フレームの予測が緑色の線です。
オレンジ色と緑色の線を比較してみると、ピーク値付近(x=18,38,58,78)では左向きの動きが見られます。一方でエッジ部付近(x=25,45,65,85)ではわずかに右向きの動きが見られます。全体的としては左向きの動きが大きいため、左向きの動きが知覚されていると考えられます。
なお、青線とオレンジ色の線は波形が違うため比較しにくいですが、オプティカルフローの計算時には処理中に平滑化をすることが多いため、これも同様の議論ができると思います。ただしオプティカルフローの計算方法によっては、逆向きの動きが出るかもしれません。
import numpy as np
import cv2
import matplotlib.pyplot as plt
x = np.arange(100)
p = (x//20)%2
y = p*(x%20) - (1-p)*(x%20) # 円周上の輝度プロファイルはだいたいこんな形
y = y.astype(np.float32)
plt.plot(y)
# 次フレームの予測値
y = cv2.GaussianBlur(y[np.newaxis,:],(11,1),2.5).flatten()
plt.plot(y)
# 次々フレームの予測値
y = cv2.GaussianBlur(y[np.newaxis,:],(11,1),2.5).flatten()
plt.plot(y)
plt.show()
追加実験(2018/06/09追記)
元論文の著者のWatanabeさんにコメントをいただきました。
このネガコンは、使っているパーツは同じで、向きが入れ子構造になっています。PredNetはこのネガティブコントロールを無回転と判定しました(主観とおなじ)。論文の図9,図10を参考ください。動きやコントラストの統計量ではどうなるでしょうか?お時間ありましたら、是非。
— Eiji_Watanabe (@eijwat) 2018年6月6日
錯視を起こすテスト画像に対し、類似したパターンで構成されるが錯視を起こさないネガティブコントロール画像を用意して差異を調べましょうというコメントです。
早速やってみます。
入力した画像は下記の2つです。(こちらから引用改変したものです)
↓テスト画像

↓ネガティブコントロール画像。

それぞれの出力結果はこちらです。なお画像サイズ以外の各種パラメータは前の実験と同じです。
↓テスト画像

↓ネガティブコントロール画像

テスト画像に対する結果は前の実験と同様の結果です。コントロール画像に対する結果は、回転錯視は出てきていないものの、各箇所でバラバラな方向の動き錯視があるという結果です。
今回のモデルはごく局所的な情報しか見ていませんので、ある意味当然の結果ではあります。
しかしこれは人間の錯視とは違います。
ということで、今回のモデルは錯視のモデルとして十分ではないことがわかりました。
ネガティブコントロールの出力を再現するには、空間的な整合性がとれるように動きを統合する機能が不足していると思われます。オプティカルフロー計算時のブロックサイズを変更すると、このような効果があるはずなのですが、少し試しても上手く行きませんでした。ほどよいモデル改変も思いつきませんので、今回はここまでとします。
おわりに
あまり詳細には調べていませんので、間違った部分があるかもしれませんが、ひとまずは錯視を再現できるシンプルなモデルをつくることができました。
(2018/06/09追記)
錯視の一部要因を説明できるシンプルなモデルをつくることができましたが、追実験のネガティブコントロール画像に対しては人間の錯視と一致しない結果となっており、錯視のモデルとしては十分ではないことがわかりました。
なお今回のモデルでは色を扱っていませんが、個人的には色がついているほうが錯視量が多いと感じることが多いです。これをモデリングするには実際の人間の視覚特性など入れていく必要があるような気がします。
今回のモデルはニューラルネットワークでもなんでもないわけですが、錯視とニューラルネットワークの組み合わせは面白い研究領域だと思います。今後は前段に画像生成モデルをくっつけて錯視生成とかやってみたいです。