はじめに
この記事は佐久間まゆ Advent Calendar 2017の24日目の記事です。
雑談
皆さん、アニメや漫画、ゲーム...などなどの多くのメディアの中で好きなキャラクターはいるでしょうか?
私はアイドルマスターシンデレラガールに登場する、佐久間まゆ(CV.牧野由依)が大好きです。一途な性格と少し入ってる天然?と言いますか、どこか少し抜けてる所とか可愛いです。
最近はモバマスだけではなく、デレステでも彼女の色々な一面が見えるので良ければやってみて欲しいです。
目的
そんな佐久間まゆなのですが、最近は色々な絵師さんが絵を描いてくださってツイッターなどで上げてくれることがあります。また、色々な人が佐久間まゆに関連した画像(ゲームのスクリーンショットなど)を上げています。そういった画像を一気にまとめて保存したいことってないでしょうか?そんなことないって?
そんな時に一括で集めれるスクリプトを書いてみました。
ソースコード
setting.py
# アクセトークンの設定ファイル
CONSUMER_KEY = "************"
CONSUMER_SECRET = "************"
ACCESS_TOKEN = "************"
ACCESS_TOKEN_SECRET = "************"
get_illustration.py
from requests_oauthlib import OAuth1Session
import json
import os
import re
import urllib
import setting
twitter = OAuth1Session(setting.CONSUMER_KEY, setting.CONSUMER_SECRET, setting.ACCESS_TOKEN, setting.ACCESS_TOKEN_SECRET)
mkdir_name = "mayu_illustration"
# 集めた画像を格納するディレクトリの作成を行う
def dir_check():
if not os.path.isdir(mkdir_name):
os.mkdir(mkdir_name)
check_count = 0
while True:
if not os.path.isdir(mkdir_name + "/dir" + str(check_count)):
os.mkdir(mkdir_name + "/dir" + str(check_count))
dir_name = "/dir" + str(check_count)
return dir_name
check_count += 1
# ツイッター上の「佐久間まゆ」と入ったツイートを100個取得する
def get_target_ward(ward):
url = "https://api.twitter.com/1.1/search/tweets.json"
params = {'q':ward,
'count':100
}
req = twitter.get(url, params = params)
timeline = json.loads(req.text)
return timeline
# 取得したツイートに画像があれば、その画像を取得する
def get_illustration(timeline, dir_name):
global image
global image_number
image_number = 0
check_image = []
for tweet in timeline['statuses']:
try:
media_list = tweet['extended_entities']['media']
for media in media_list:
image = media['media_url']
if image in check_image:
continue
with open(mkdir_name + dir_name +"/mayu_image_"+str(image_number) +"_"+os.path.basename(image), 'wb') as f:
img = urllib.request.urlopen(image).read()
f.write(img)
check_image.append(image)
image_number += 1
print("get tweet media")
except KeyError:
print("KeyError:画像を含んでいないツイートです")
except:
print("error")
if __name__ == '__main__':
dir_name = dir_check()
all_list = []
# 検索対象の単語を設定
# ORで条件を付けれる
# 例:ward = "佐久間まゆ+OR+ままゆ"
# ならば、ツイートに「佐久間まゆ」、もしくは「ままゆ」と含まれる物を取得
ward = "佐久間まゆ"
timeline = get_target_ward(ward)
get_illustration(timeline, dir_name)
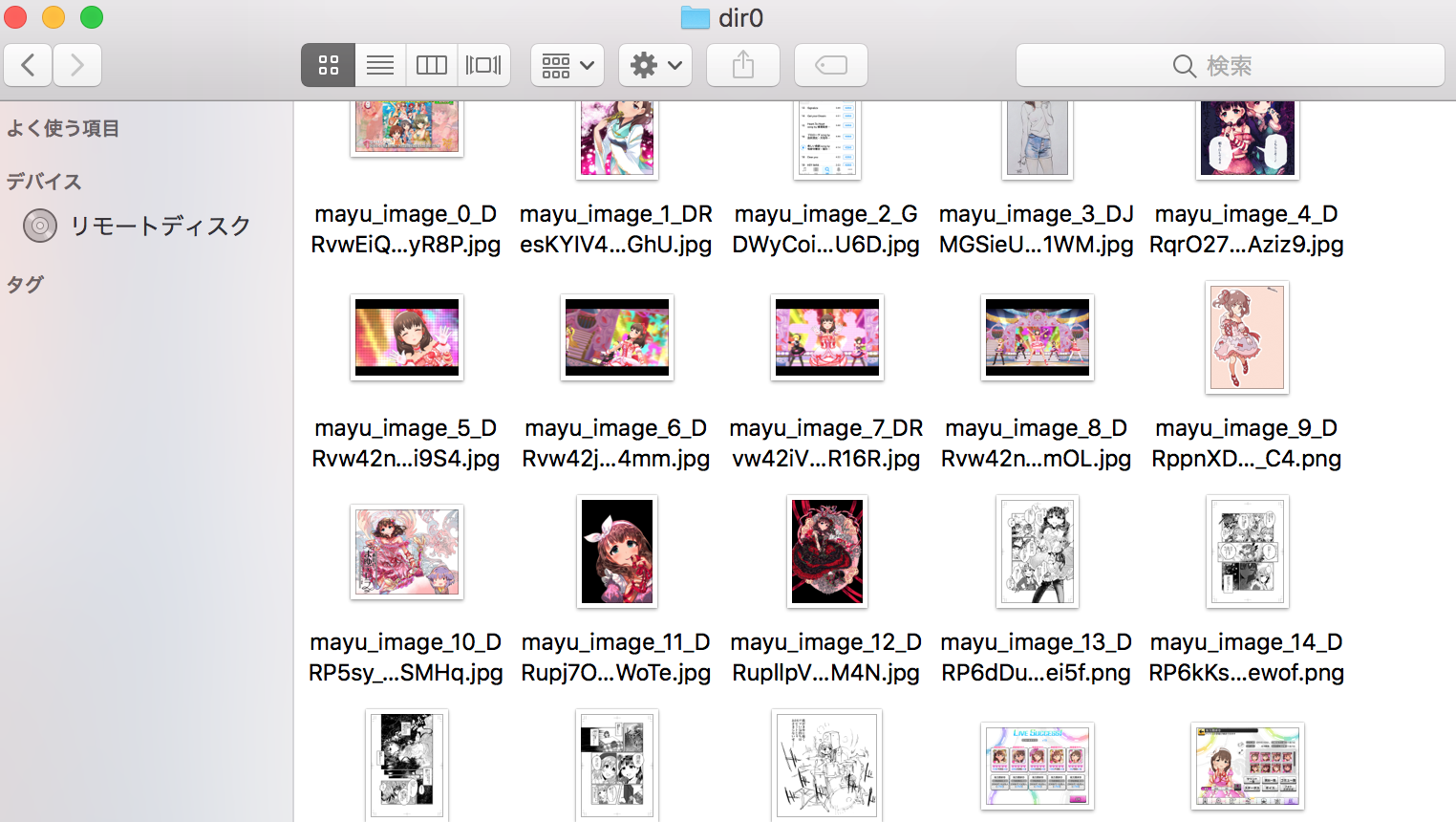
実行結果
結構良い感じです。ただ、画像を集める基準として、
「佐久間まゆ」という単語が含まれているツイート且つ、ツイートに画像が含まれている
という条件にしているので、関係のない画像データ等も混ざってしまうことがあるみたいです💦
終わりに
画像を集めること自体は割と簡単にできます。ただ、より多くの画像を集めることやノイズ画像を取り除くといった最適をどうやってすれば良いのか調べていきたいと思います。
あと、やっぱりまゆ可愛いです。