プログラマーのためのR言語入門の続きです。
R言語を始めるときのポイントまとめです。
前回はR言語の文法的な内容がメインでしたが、今回はR言語を使ってデータの分析をする際によく使うものを中心にまとめてみます。
apply関数群 補足
apply関数はよく使うので、前回分をもう少しまとめておきます。
apply関数群は「○○ごとに集計を行う」関数です。
apply
「行・列ごとに集計」を行います。
第2引数に"1","2"の指定で行ごとか列ごとかを切り替えます。

適当なサンプルで見てみると
data.sample <- data.frame(
"りんご" = c(120,110,150),
"たまねぎ" = c(80,90,85),
"にんじん" = c(50,45,60)
)
rownames(data.sample) <- c("A店","B店","C店")
> りんご たまねぎ にんじん
> A店 120 80 50
> B店 110 90 45
> C店 150 85 60
apply(data.sample, 1, sum)
> A店 B店 C店
> 250 245 295
apply(data.sample, 2, mean)
> りんご たまねぎ にんじん
> 126.66667 85.00000 51.66667
lapply
「リストごとに集計」を行います。
リストはデータフレームのような2次元構造ではなく、いわばなんでも入る入れ物です。
list.sample <- list(
"お店" = c("A店","B店"),
"データ" = c(1,2,3,2,3,4,5),
"評価" = c(T,F,T,F,F)
)
> $お店
> [1] "A店" "B店"
>
> $データ
> [1] 1 2 3 2 3 4 5
>
> $評価
> [1] TRUE FALSE TRUE FALSE FALSE
lapply(list.sample, length)
> $お店
> [1] 2
>
> $データ
> [1] 7
>
> $評価
> [1] 5
リストだけでなく、ベクトルを受け取ることもできます。
1個ずつ処理される動きになるので、ループの代わりとしても使えます。
lapply(1:10, function(n){rep(n,n)})
> [[1]]
> [1] 1
>
> [[2]]
> [1] 2 2
>
> [[3]]
> [1] 3 3 3
>
> [[4]]
> [1] 4 4 4 4
tapply
「グループごとに集計」を行います。
第一引数に集計対象、第二引数にグループを集計したいグループを指定します。
data.train <- data.frame(
"名前" = c("A","B","C","D","E","F"),
"血液型" = c("A","B","A","O","AB","B"),
"給料" = c(300,450,400,500,430,380),
"身長" = c(170,160,180,168,172,165)
)
> 名前 血液型 給料 身長
> A A 300 170
> B B 450 160
> C A 400 180
> D O 500 168
> E AB 430 172
> F B 380 165
tapply(data.train$`給料`,data.train$`血液型`,mean)
> A AB B O
> 350 430 415 500
同じデータフレームのデータでなくても可能です。
例として奇数偶数のグループ分け用のベクトルを作って集計してみます。
また、集計だけでなくリストを返すことも可能で、奇数偶数ごとにデータを集めて取り出すということが簡単にできます。これが結構便利。
group <- c("奇数","偶数","奇数","偶数","奇数","偶数")
tapply(data.train, group, mean)
> 奇数 偶数
> 376.6667 443.3333
tapply(data.train$`給料`, group, list)
> $奇数
> [1] 300 400 430
>
> $偶数
> [1] 450 500 380
行列
行列計算もよく使うのでまとめます。行列用の型、matrixを利用します。
作り方はベクトルと何行何列にするかを引数で指定します。
与えたベクトルが順に要素になっていくので、どういう順番方向に埋めるかはbyrowで調整します。
matrix(1:12, nrow = 3)
> [,1] [,2] [,3] [,4]
> [1,] 1 4 7 10
> [2,] 2 5 8 11
> [3,] 3 6 9 12
matrix(1:12, ncol = 4, byrow = T)
> [,1] [,2] [,3] [,4]
> [1,] 1 2 3 4
> [2,] 5 6 7 8
> [3,] 9 10 11 12
行列演算の足し算引き算は"+","-"を使います。
各要素同士を掛けるのは"*"ですが、行列の掛け算は"%*%"です。
A <- matrix(1:4, nrow = 2, ncol = 2)
B <- matrix(2:5, nrow = 2)
A
[,1] [,2]
[1,] 1 3
[2,] 2 4
B
[,1] [,2]
[1,] 2 4
[2,] 3 5
A * B
[,1] [,2]
[1,] 2 12
[2,] 6 20
A %*% B
[,1] [,2]
[1,] 11 19
[2,] 16 28
他にも、転置するt()、逆行列を求めるsolve()、固有値固有ベクトルを求めるeigen()など、機能は盛りだくさんです。
モデル作成と予測
R言語の真髄として、データに対して様々な分析手法を適用して結果を利用するということがあります。
R言語ではいくつもの手法が利用可能ですが、ある程度使い方が共通するところがあるので回帰分析(lm)を例にまとめます。
回帰分析のイメージは、データの分布を表す線を引くものです。
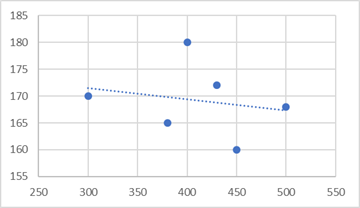
モデル作成
回帰分析の詳しい内容や理論は他の記事に任せるとして…、
R言語を使って「データを使ってある数値を予測する」ということをすることがよくあります。
その時の記述方法として 予測対象 ~ 利用するデータとすることで分析結果が得られます。
data.train <- data.frame(
"名前" = c("A","B","C","D","E","F"),
"血液型" = c("A","B","A","O","AB","B"),
"給料" = c(300,450,400,500,430,380),
"身長" = c(170,160,180,168,172,165)
)
model <- lm("給料 ~ 血液型 + 身長", data.train)
summary(model)
> Call:
> lm(formula = "給料 ~ 血液型 + 身長", data = data.train)
>
> Residuals:
> 1 2 3 4 5
> -2.400e+01 4.800e+01 2.400e+01 -1.776e-15 9.770e-15
> 6
> -4.800e+01
>
> Coefficients:
> Estimate Std. Error t value Pr(>|t|)
> (Intercept) -560.00 1680.86 -0.333 0.795
> 血液型AB 95.60 97.31 0.982 0.506
> 血液型B 130.00 141.99 0.916 0.528
> 血液型O 186.40 114.70 1.625 0.351
> 身長 5.20 9.60 0.542 0.684
>
> Residual standard error: 75.89 on 1 degrees of freedom
> Multiple R-squared: 0.7517, Adjusted R-squared: -0.2414
> F-statistic: 0.7569 on 4 and 1 DF, p-value: 0.6856
血液型と身長を使って給料を予測する場合、給料~血液型+身長という記述方法になります。
回帰分析ではlm()関数を使いますが他の関数でも同じように記述すると実行できるものがたくさんあります。
実行するとその結果が戻り値として返ってきます。これは単一の数値というわけではなく、その評価などが詰まったもので、summary()関数で中身が確認できます。
実際にデータ分析する際はこの値をみて、ちゃんとできてるかなーと確認します。
予測
モデルの活用方法として、予測に使うことがあります。
例えば、先程のモデルを使うと、血液型と身長をつかって給料を導き出すことができます。(モデルの良し悪しは置いておいて。)
予測にはpredict関数を使います。
今回は血液型と身長のデータがあればよいのでデータを準備して給料を予測してみます。データはnewdataに指定します。
data.test <- data.frame(
"名前" = c("G","H","I"),
"血液型" = c("O","B","A"),
"身長" = c(178,165,175)
)
predict(model,newdata = data.test)
> 1 2 3
> 552 428 350
これで、G,H,Iさんの給料予測ができました。
なんとlm(…)とpredict(…)の2行でここまでできてしまいます。
一つ注意点、先程のpredictにnewdataを指定しなかった場合。
predict(model)
> 1 2 3 4 5 6
> 324 402 376 500 430 428
こうなります。これは、predict(model, newdata = data.train)とした場合と同じ意味になります。
ややこしいですが、予測モデルを作成するために使ったデータを使って予測している状態です。
予測モデルのできを調べるために使うこともありますが、「予測対象を指定してないのに動いた!」と混乱しないように注意しましょう。(私は昔混乱した。)
plot関数
R言語の特徴としてデータの可視化がサクッとできることがあります。
さすが統計用言語。
可視化の方法もいろいろありますが、何はともあれplot関数です。
plot関数は受け取るデータに合わせて様々なグラフを表示してくれます。先程のデータで試してみます。
たとえばplot(data.train$血液型)のようにfactor型を指定すると
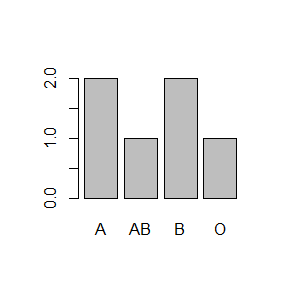
のような棒グラフになったり、データフレームをそのまま指定すると
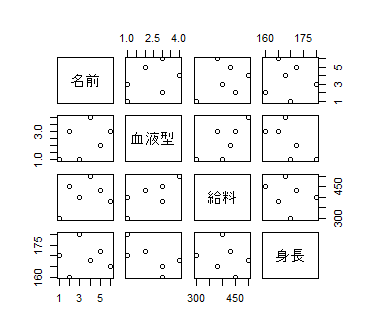
のように各要素の関連が見れる図になったりします。
またパラメータ設定によって見せ方を変えることもできます。
代表的なものとして、
- main …タイトル
- sub …サブタイトル
- type …プロットする点/線の設定
- xlab/ylab …軸のラベル
- col …色
- lty …線の形式
- lwd …線の太さ
- pch …プロットのマーカー
などがあります。
plot(data.train[,c("身長","給料")],
main = "タイトル",
sub = "サブ",
type = "b",
xlab = "xxx",
ylab = "yyy",
pch = 6,
lty = 4,
lwd = 2,
col=data.train$`血液型`)
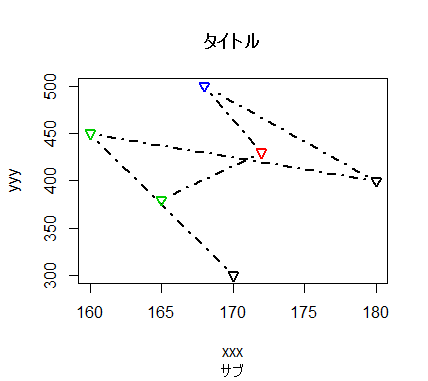
colの設定は"red"のように色名を直接指定することもできますし、サンプルのようにベクトルを指定すると対応するプロットの色が変わるので何かと便利です。
参考: グラフィックスパラメータ(弐)
おすすめライブラリ
R言語はlibraryを利用することでどんどん機能を拡張できます。
R言語専用のものもありますが、javascriptライブラリとして有名なものがR言語用に拡張されているものもあります。
- magrittr
- パイプ処理の記述が書けるようになる。pipeRも。
- Leaflet
- Rから地図を簡単に扱えるようになります。
- dygraph
- 時系列データのグラフ化にどうぞ。
- dyplr
- データ操作。そういえばあんまり使ったことがない。。。
- ggplot2
- 多機能できれいなグラフライブラリ
上記のものはデータ操作や可視化のためのものですが、いろいろな分析手法用のライブラリもたくさんあります。
以下のようなまとめが非常に参考になります。
- すごく詳しいまとめ
参考
おわりに
R言語入門向けということで最初に覚えたらよいと思う内容をまとめてきましたが、ちょっとしたRの文法や分析機能の記述方法さえ抑えてしまえば、他のプログラム言語の知識を活用してなんとかなります。統計向けとかデータ分析向けとは言っても近代的なスクリプト言語なイメージです。
データ分析やちょっと高度な集計をやってみたい方はこういった言語を触りながら遊んでみるのがいいですね。