自然言語や画像の分野で埋め込みベクトルを使ってみることが多くなってきたので、実験用に手元でさっと遊べるプログラムを作っておきました。
なお、これらの仕組みはおそらくLangChainとか使うともっと堅実に実現できると思います。あくまでお試し用にどうぞ。
こちら
READMEはまだ全然書けていない。
どういう機能?
テキストや画像を雑に突っ込むと、類似検索や分類ができるようになるというものです。
仕組みとしては入力されたテキストor画像を言語or画像モデルを用いて埋め込みベクトル化し近傍探索できるようにしたものです。
ついでにゼロショットでの分類もできるようにしてみています。
機能として特に新規性はないですが、雑に突っ込んでそれなりに動いて遊べる自分用ツールとして作っています。
この記事(仮想「データサイエンティスト採用試験」作って採点してみる)作るときにサンプル回答として作っていたものを汎用化したものでもあります。
利用もの色々
- 埋め込みベクトル
- 最近傍探索のsqlite拡張
動かしてみる
何はともあれ動かしてみる。
現在3種類のクラスを実装しています。今後元気があれば機能拡張and種類増加するかもしれません。
- VSU_Text_E5
- テキスト用
- VSU_Image_CLIP
- 画像、画像toテキスト用
- VSU_Image_EfficientNet
- 画像用
サンプルデータ
検索を試すためのデータとして、国立国会図書館のオープンデータを利用させてもらいます。
国立国会図書館 - オープンデータセット
手頃なデータ量のものとして、博士論文のデータを利用します。

※以下、Colaboratoryで動作検証
インストール
!pip install git+https://github.com/stkdev/VectorSearchUtil.git
QuickStart - テキスト編
コード
import pandas as pd
from vsu.text import VSU_Text_E5
from vsu.image import VSU_Image_CLIP, VSU_Image_EfficientNet
# データ
dat = pd.read_csv("https://dl.ndl.go.jp/static/files/dataset/dataset_202305_h_internet.zip", sep='\t')
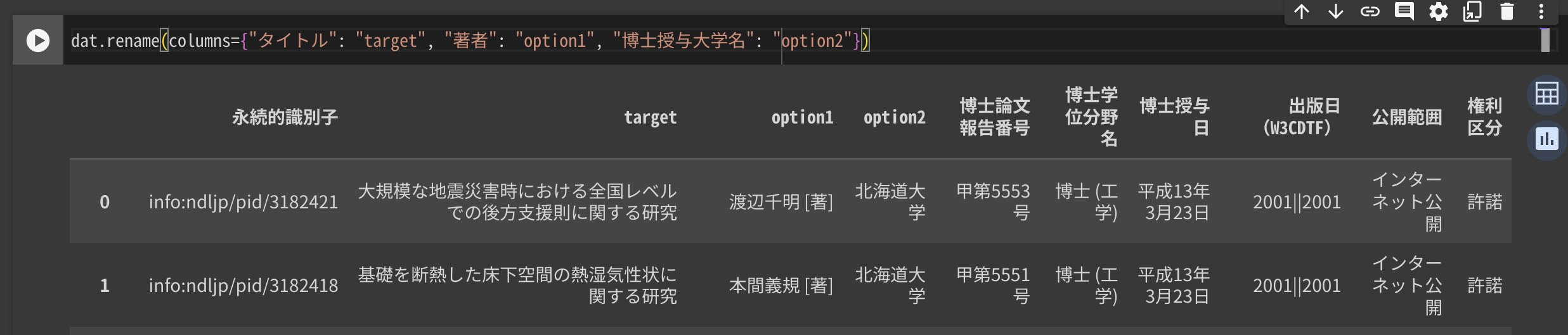
# ①列名設定
# 例なので1000行ぐらいにしておきます
dat = dat.rename(columns={"タイトル": "target", "著者": "option1", "博士授与大学名": "option2"}).head(1000)
# ②インスタンス化
vsu = VSU_Text_E5()
# vsu = VSU_Text_E5(db_name="test.db")
# ③データ登録
vsu.set_data(dat)
# ④検索
q = "ベクトル検索"
print(f'テキストの近傍探索。クエリ:{q}')
vsu.query_with_info(q)
①列名設定
ベクトル化・検索の対象とする列名をtargetとします。
検索対象ではないですがデータとして保持しておきたい列名をoption1~5とします。
②インスタンス化
引数無指定の場合はインメモリのDBに保持。
db_nameに名称を指定するとsqliteのファイルとして保持されます。
③データ登録
set_data()に突っ込んで少々待ちます。
set_dataに無指定で突っ込むとデータの総入れ替え、append=Trueをつけると追記モードとなります。
④検索
検索クエリを入れると類似度Top5の結果が返されます。

「ベクトル検索」の類似検索結果として「類似検索」や「特徴量距離の推定に基づく画像検索」が返ってきており、うまくごいてそうです。
QuickStart - 画像編
画像の場合は画像へのパスの列をtargetとします。
また、テキスト編と同様にデータとして保持しておきたい列をoption1~5とします。
サンプルとしてimg/以下に画像が入っていることを想定して準備します。
# データの準備部分
# img/ に対象画像ファイルがある前提
import glob
from PIL import Image
from IPython.display import display, HTML
style = "<style>#output-body{display:flex; flex-wrap: wrap;}</style>"
display(HTML(style))
img_paths = []
for p in glob.glob('img/*.png'):
img_paths.append(p)
display(Image.open(p).resize((200,200)))
# ①列名設定
df = pd.DataFrame({"target": img_paths}) #画像パスが設定されたデータフレーム
df.head(5)

コード
import pandas as pd
from vsu.text import VSU_Text_E5
from vsu.image import VSU_Image_CLIP, VSU_Image_EfficientNet
# ②インスタンス化
vsu = VSU_Image_CLIP()
# ③データ登録
vsu.set_data(df)
# ④検索
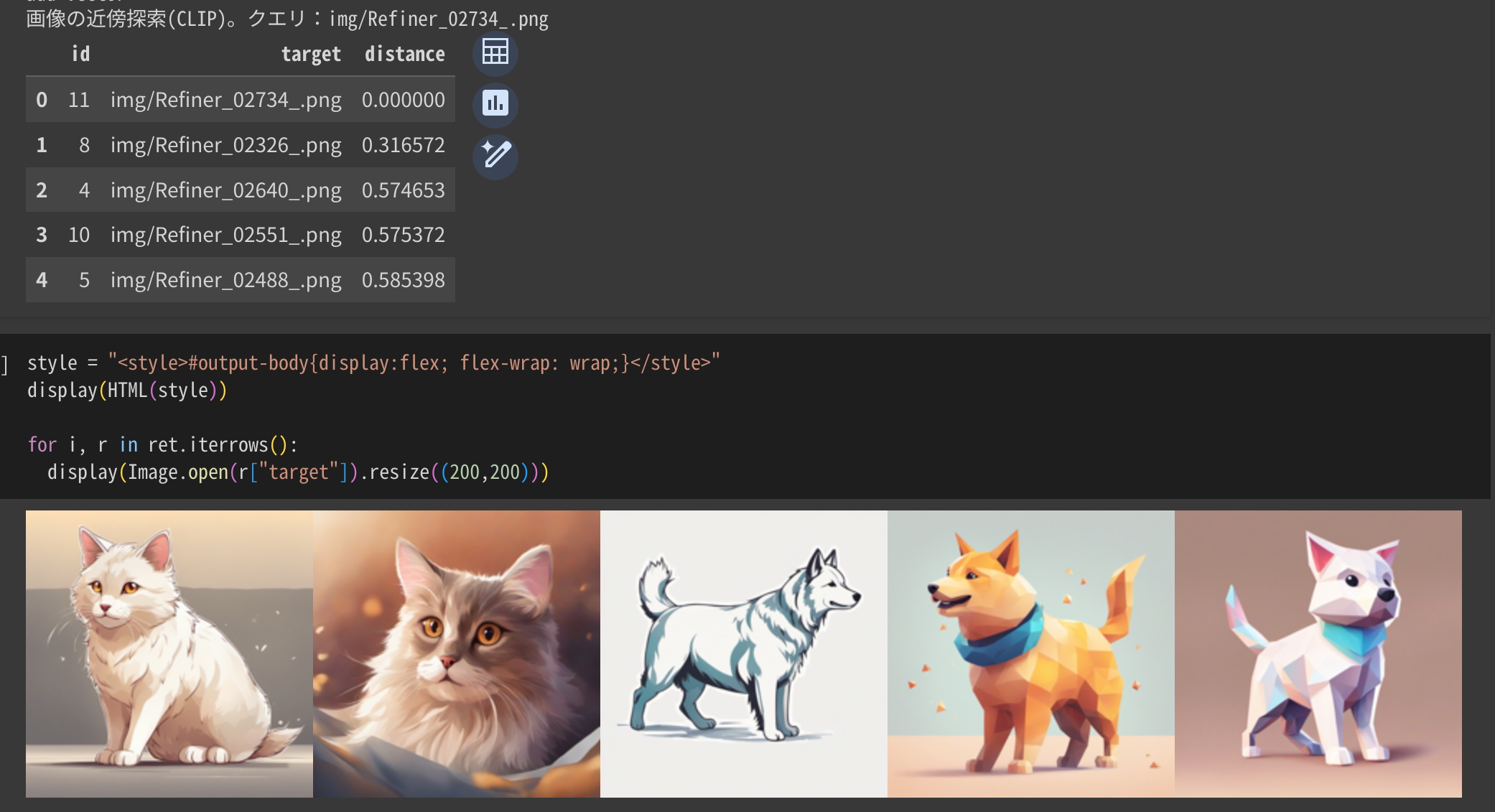
q = "img/Refiner_02734_.png"
print(f'画像の近傍探索(CLIP)。クエリ:{q}')
ret = vsu.query_with_info(q)
display(ret)
②インスタンス化
引数無指定の場合はインメモリのDBに保持。
db_nameに名称を指定するとsqliteのファイルとして保持されます。
③データ登録
set_dataメソッドに突っ込んで少々待ちます。
set_dataに無指定で突っ込むとデータの総入れ替え、append=Trueをつけると追記モードとなります。
④検索
検索したい画像のパスを検索クエリとして入れると類似度Top5の結果が返されます。
(これ、パスじゃなくて画像そのものを入れるバージョンもあったほうがよさそうだな・・・)
選ばれた5つはこちら。左端の白い猫で検索して、近い順に左から並べています。
いい感じで動いてそう。
ゼロショット分類
VSU_Image_CLIPではCLIPの機能を使って画像からテキストのゼロショット分類もできるようにしています。
①ラベル設定
分類したい文章をリストで定義し、set_zeroshot_labels()で登録します。
②分類実行
do_zeroshot()を実行すると現在保持している全画像データに対して分類を行いその結果を返します。
# ①ラベル設定
labels = ["a cat", "a dog"]
vsu.set_zeroshot_labels(labels)
# ②分類実行
scores, pred = vsu.do_zeroshot()
# ③結果
print(f'画像のゼロショット分類。分類キー:{labels}')
ret = pd.DataFrame({"target": vsu.data["target"], "pred": pred})
for i, r in ret.iterrows():
display(Image.open(r["target"]).resize((200,200)), r["pred"])
こんな感じでラベルが推定されます。
分類やタグ付けにどうぞ。

このあたりの設計は変える可能性大いにあり。
その他機能予定
まだ発展途上なので、今後機能追加や修正は色々入ると思います。
- 埋め込みベクトルを入力に、NNで教師あり学習できるようにする(途中)
- 対応モデル増やす
- ベクトルの近傍探索以外の検索機能(普通にキーワード検索とか、組み合わせるとか)