MySQL非エンジニア
目的
MySQLの使用環境があったので備忘録としてまとめておく。
企業が使っているデータベースの仕組みや普段接しているアプリケーションがどのようにデータベースと繋がっているか学習したいと思ったから。基本的には個人備忘録用。
誤った箇所があればご指摘ください。
データベースの管理
データベースの作成
データベースを新たに作成するにはCREATE DATABASE文を使う
CREATE DATABASE データベース名;
データベースを作成する際にはキャラクタセット(利用できる文字の種類)を
指定することも可能。
デフォルトのキャラクタセットはLatin-1という欧文セット。
日本語を扱う場合には、utf8(UTF-8/Unicode)やcp932(シフトJS)が指定できる。
次の例では文字コードをUTF-8にしてデータベースexampledbを作成
CREATE DATABASE exampledb CHARACTER SET utf8;
データベースの一覧を見る
SHOW databases;
※ データベースの一覧に表示される「Information_schema」「mysql」はMySQLサーバーの管理用データベースなのでいじらないように。
データベースの削除
データベースを削除するにはDROP DATABASE文を使う。
DROP DATABASE データベース名;
データベースの選択
USE データベース名
「Database changed」と表示されればOK( ;は不要。)
データベースにユーザーを登録する
MySQLを利用するにはあらかじめデータベースユーザーを作成しておく必要がある。
MySQLをインストールした直後には管理者権限を持つrootユーザーが用意されている。
実際にはrootユーザーは使用せず管理用のユーザーを作成して利用する。
rootユーザーはとても大きな権限を持っているので、もし第三者にアカウントを奪われたら大変。
新しいユーザーを追加するコマンドは以下の通り
CREATE USER ユーザー名@ホスト名 IDENTIFIED BY 'パスワード';
ユーザーを作成するときには同時にホスト名も指定する。
ここで指定したホストからのみデータベースに接続できる。
(ホスト名にはwww.example.comといった名前や「192.168.11.1」といったIPアドレスが指定できる)
データベースサーバーと同じホストから接続する場合は「localhost」としておけば良い。
ユーザーのパスワードはIDENTIFIED BYに続けて指定。パスワードは省略可能。
EXAMPLE
CREATE USER newuser@localhost IDENTIFIED BY 'dbpassword';
ユーザーに権限を付与する
データベースのユーザーにはデータベースにアクセスする権限、テーブルを作成する権限、テーブルのデータを閲覧する権限など、様々な権限を付与することができる。
新しく作られたユーザーには権限が設定されていないので必要な権限を設定する。
権限の設定にはGRANT文を使用する。
GRANT 権限 ON データベース名.テーブル名
TO ユーザー名@ホスト名 [IDENTIFIED BY 'パスワード']
代表的な権限は以下のとおり。
| 権限 | 説明 |
|---|---|
| ALL | 全ての権限(ただしGRANT OPTIONを除く) |
| ALL PRIVILEGES | ALLと同じ |
| CREATE | データベースやテーブルの作成 |
| CREATE USER | ユーザーの作成・削除 |
| CREATE VIEW | ビューの作成 |
| DELETE | DELETEコマンドの実行 |
| DROP | データベースやテーブルの削除 |
| INSERT | INSERTコマンドの実行 |
| SELECT | SELECTコマンドの実行 |
| UPDATE | UPDATEコマンドの実行 |
| GRANT OPTION | 権限の付与 |
次の例では、sampledbデータべースの全テーブルに対して、全ての権限をnewuserに与えている。「sampledb.*」は「sampledbデータベースにある全てのテーブル」を表す。
GRANT ALL PRIVILEGES ON sampledb.* TO newuser@localhost;
データベースを特定せず、全てのデータベースに対する権限を設定する場合は
「.」を使ってデータベースとテーブルを指定する。次の例では全てのデータベースに対してSELECT文が実行できる権限をユーザーnewuserに与えている。この場合、データベースを更新したりレコードを削除したりする権限は「newuser」にはない。
GRANT ALL PRIVILEGES ON *.* TO newuser@localhost;
指定したユーザーが存在しない場合にはGRANT文だけで新規ユーザー作成、権限付与を行うことができる。
GRANT ALL PRIVILEGES ON *.* TO testuser@localhost IDENTIFIED BY 'パスワード'
データベースのユーザーパスワードの変更
パスワードを変更するときにはSET PASSWORDを使う
SET PASSWORD FOR ユーザー名@ホスト名=password('新しいパスワード');
ユーザーの一覧表示
データベースにどんなユーザーがいるのか調べるにはMySQLが管理用に使っているmySQLデータベースのuserテーブルを参照する。
SELECT User, Host FROM mysql.user;
ユーザーの削除
不要になったデータベースのユーザーはDROP USERコマンドで削除できる
DROP USER ユーザー名@ホスト名;
テーブルの設計
テーブル情報の確認
DESC members;

左から列名、データ型、非NULL制約、キー、デフォルト値、その他と並んでいる。
※1列目の「Field」は列に付けられた名前(予約後は使用不可)
データ型とは
レコードの各列にはどのようなデータを格納できるのかあらかじめ属性が決められている
主なデータ型は下記の通り
| データ型 | 説明 |
|---|---|
| TINYINT | 整数(1バイト) |
| SMALLINT | 整数(2バイト) |
| INT | 整数(4バイト) |
| BIGINT | 整数(8バイト) |
| FLOAT | 浮動小数点数(4バイト) |
| DOUBLE | 浮動小数点数(8バイト) |
| CHAR(N) | N(0~255)文字の固定長文字列 |
| VARCHAR(N) | N(0~65535)文字の可変長文字列 |
| TEXT | 65535バイトまでの文字列(大文字小文字の区別なし) |
| BLOB | 65535バイトまでの文字列(大文字小文字の区別あり) |
| DATE | 日付(YYYY-MM-DD) |
| DATETIME | 日時(YYYY-MM-DD HH:MM:SS) |
| TIME | 時刻(HH:MM:SS) |
制約とは
制約とは,テーブルに格納するデータを限定する方法。
データ型によって整数であるか,文字列であるかといったデータの種類を限定することができる。しかし,それでは正数のデータのみを受け付けるとか,同じデータが重複してはいけないとかといった制限を行うことができません。
このような制約を列やテーブルに対して定義することができる。
制約に違反するデータを格納しようとするとエラーとなる。
代表的な制約
| 制約 | 説明 |
|---|---|
| PRIMARY KEY | 主キーとする |
| UNIQUE | 重複した値を受け付けない |
| NOT NULL | NULL値を受け付けない(非NULL制約) |
| DEFAULT値 | デフォルト値を設定する |
非NULL制約
NULL値を許容するかどうか、その列にはNULLが格納されても良いか示されている
「NO」となっていればNULLはダメ。
主キーとは
PRIMARY KEYを表す。値に重複がなくユニークな値でなければならない。
外部キーとは
他のテーブルの主キーが参照している列のことを外部キーという。
※主キー列と外部キー列によってテーブルが結びつけられる
参照整合性
主キー列にはデータがあるのに外部キー列にはその値がないといった場合どうなるか?
下記一例


この例ではunitテーブルの主キーであるid列は外部キーとしてstaffテーブルのunit_idを参照している。
しかし、例えばstaffテーブルにある「unit_id = 3」に該当する値はunitテーブルには存在しない。そのため、テーブルを結合すると該当部分は「NULL」になってしまう。
主キーと外部キーとの間の整合性を**"参照整合性という"**。
参照整合性がなくなってしまうとテーブルを結合した時にレコードが取得できなくなったり適切な値が表示されなくなったりする。
正規化
目的:データの冗長性をなくして、データベースの保守性を高める
正規化には幾つもの段階がある。
全く正規化されていない非正規化から正規化を進めて第1正規化、第2正規化、第3正規化に
至る。第4正規化以降もあるが通常は第3正規化までで十分。
テーブルの作成
テーブルの管理
テーブルの作成
新しいテーブルを作るにはCREATE TABLE文を使う
CREATE TABLE テーブル名(
列名1 データ型 [制約],
列名2 データ型 [制約],
列名3 データ型 [制約],
...
);
EXAMPLE
CREATE TABLE goods(
id INT PRIMARY KEY,
name CHAR(10),
price INT
);
テーブルのコピー
テーブルの構造をコピーして新しくテーブルを作成することができる
CREATE TABLE 新規テーブル名 LIKE コピー元テーブル名;
カラムをテーブルに追加する
テーブルの作成後にカラムを追加する場合にはALTER ~ ADD文を使う。
ALTER TABLE テーブル名 ADD カラム名 データ型 [FIRST];
※もし左端にカラムを追加した場合は[FIRST]を指定する
カラムをテーブルから削除する
カラムをテーブルから削除する場合にはADDの代わりにDROPを使う。
ALTER TABLE テーブル名 DROP カラム名 データ型 [FIRST];
テーブル名の変更
テーブル作成後にテーブル名を変更。
ALTER TABLE 現在のテーブル名 RENAME 新しいテーブル名;
テーブルの削除
テーブルの削除を行うには DROP TABLE文を使用する。
DROP TABLE テーブル名;
ビューの作成
ビューとは
実際のテーブルとは異なる仮想敵なテーブルを作ることができる。
仮想的なテーブルをビュー(View)と呼ぶ。
ビューは複数のテーブルを結合して一時的なテーブルを作ったり、実際のテーブルとは異なったアクセス権を持たせたい場合などに利用する。SELECT文を使って何度もデータを抽出したりテーブルを結合したりするよりもあらかじめビューを作っておいたほうがパフォーマンスも高まる。
ビューを作成するにはCREATE VIEW文を使う。
CREATE VIEW ビュー名
AS SELECT 列名 FROM テーブル名 WHERE 条件;
ビューの削除
DROP VIEW ビュー名;
代表的な制約
| 制約 | 説明 |
|---|---|
| PRIMARY KEY | 主キーとする |
| UNIQUE | 重複した値を受け付けない |
| NOT NULL | NULL値を受け付けない(非NULL制約) |
| DEFAULT値 | デフォルト値を設定する |
レコードの挿入/変更/削除
INSERT命令を使ってレコード追加する
データベースにデータを追加するにはレコード単位で行う。
INSERT INTO db_name.tbl_name (col_name1, col_name2, ...)
VALUES (value1, value2, ...);
USE文を使ってデータベースに接続している状態で、そのデータベース内に
あるテーブルにデータを追加する場合は次のように単にテーブル名だけを
指定して作成することもできる
INSERT INTO tbl_name (col_name1, col_name2, ...)
VALUES (value1, value2, ...);
複数レコードの登録を1つのSQL文で実行する場合は下記のようにカンマ区切りで記述する。
EXAMPLE
INSERT INTO user_table (id, name, memo, status) VALUES
(1, 'test1', 'メモ', 1),
(2, 'test2', 'メモ', 1),
(3, 'test3', 'メモ', 1),
(4, 'test4', 'メモ', 1);
- テーブルにレコードを追加するにはINSERT命令を使う。
- VALUES ()内に全ての列を「,」で区切って指定する。
- 登録する値が文字列の場合は、引用符「'」で囲む。
NULLとは何か?
NULLというのはINSERT命令で何もしていしなかったところ、「NULL」という文字が入る。
NULLは「値が存在してない」状態を示す。数字の「0」とは違うので注意。
NULLのあるレコードを検索する
SELECT * FROM table名 WHERE IS NULL;
レコードの更新(変更)
特定のレコードの内容を変更するには、UPDATE命令を使用する。
UPDATE テーブル名 SET フィールド名 WHERE 条件;
EXAMPLE
UPDATE goods SET origin = 'THAILAND' WHERE id = 5;
レコードの削除
レコードを削除するには、DELETE命令を使用する。
DELETE FROM テーブル名 WHERE 条件;
EXAMPLE
DELETE FROM goods WHERE id = 5;
全てのレコードを削除
WHERE句を省略することにより全てのレコードが削除される。
テーブルの結合
複数のテーブルを対象とした結合方法
内部結合で使用するテーブルは以下の通り
classテーブル
| classname | t_id |
|---|---|
| 1-1 | t1 |
| 1-2 | t5 |
| 1-3 | t7 |
| 2-1 | t4 |
| 2-2 | t3 |
| 2-3 | t9 |
| 3-1 | t2 |
| 3-2 | t8 |
| 3-3 | t8 |
teachersテーブル
| id | name | age |
|---|---|---|
| t1 | Sato | 27 |
| t2 | Suzuki | 32 |
| t3 | Takahashi | 31 |
| t4 | Tanaka | 28 |
| t5 | Watanabe | 29 |
| t6 | Ito | 30 |
外部結合で使用するテーブルは以下の通り
staffテーブル
| id | name | unit_id |
|---|---|---|
| 1 | Sato | 1 |
| 2 | Suzuki | 2 |
| 3 | Tanaka | 3 |
unit テーブル
| id | u_name |
|---|---|
| 1 | Tokyo |
| 2 | Osaka |
| 4 | Nagoya |
内部結合
WHERE句を使用した内部結合方法
SELECT class.classname , teachers.name FROM class, teachers
Where class.t_id = teachers.id;
JOIN句を使用した内部結合方法
SELECT classname, name FROM class
JOIN teachers ON class.t_id = teachers.id;
外部結合
内部結合では紐付けたカラムのデータが片方のテーブルにしかないレコードは出力されない。
結合に使う列のデータが片方のテーブルにしか存在しない場合でも、テーブルを結合する
方法がある。それを外部結合という
左外部結合
最初に指定したテーブルにあるレコードを全て出力する左外部結合
SELECT *, FROM staff
LEFT JOIN unit
ON staff.unit_id = unit.id;
出力結果
| id | name | unit_id | id | u_name |
|---|---|---|---|---|
| 1 | Sato | 1 | 1 | Tokyo |
| 2 | Suzuki | 2 | 2 | Osaka |
| 3 | Tanaka | 3 | NULL | NULL |
最初=左側に指定したテーブルにあるレコードは全て出力されている。
しかし、staffテーブルにある「unit_id = 3」に対応するデータが右側のテーブル(unitテーブル)にないので、その部分は「NULL」となっている
右外部結合
SELECT *, FROM staff
RIGHT JOIN unit
ON staff.unit_id = unit.id;
出力結果
| id | name | unit_id | id | u_name |
|---|---|---|---|---|
| 1 | Sato | 1 | 1 | Tokyo |
| 2 | Suzuki | 2 | 2 | Osaka |
| NULL | NULL | NULL | 4 | Nagoya |
左外部結合とは逆。2番目=右側に指定したunitテーブルにあるレコードは全て出力されている。
しかし、unitテーブルにある「id = 4」に対応するデータが左側のテーブル(staffテーブル)にないため、その部分は「NULL」になっている。
サブクエリ
2つのSELECT文を1つにまとめる
利用するテーブルは以下の通り
members テーブル
| id | name | address | age |
|---|---|---|---|
| 1 | Sato | Tokyo | 27 |
| 2 | Suzuki | Tokyo | 32 |
| 3 | Takahashi | Kanagawa | 32 |
| 4 | Tanaka | Tokyo | 28 |
| 5 | Watanabe | Kanagawa | 29 |
| 6 | Ito | Tokyo | 30 |
| 7 | Yamamoto | Kanagawa | 35 |
平均年齢より高い人だけ抽出したいときは下記のようにサブクエリを使う
SELECT * FROM members age >= (SELECT AVG(age) FROM members);
上記の通り >= 以降で具体的な数値を指定するのではなく、その値を得るための
SQL文そのものを()で括って指定するのがサブクエリ。サブクエリを使うと複数のSQL文
を一つにまとめて見やすくすることができる。
複雑なサブクエリ
membersテーブルと以下のテーブルを使用して複雑なサブクエリで検索結果を表示してみる
class テーブル
| classname | t_id |
|---|---|
| 1-1 | t1 |
| 1-2 | t5 |
| 1-3 | t7 |
| 2-1 | t4 |
| 2-2 | t3 |
| 2-3 | t9 |
| 3-1 | t2 |
| 3-2 | t8 |
| 3-3 | t8 |
年齢が30歳以上の先生が担任をやっているクラスを検索
SELECT classname FROM class
WHERE t_id IN
(SELECT id FROM teachers WHERE age >= 30);
出力結果
| id | name | address | age |
|---|---|---|---|
| 2 | Suzuki | Tokyo | 32 |
| 3 | Takahashi | Kanagawa | 32 |
| 7 | Yamamoto | Kanagawa | 35 |
「WHERE~比較演算子(サブクエリ)」ではなく「WHERE ~ IN (サブクエリ)」となっている。
「年齢(age)が30歳以上の先生」(SELECT id FROM teachers WHERE age >= 30)
の結果は複数。比較演算子の右側に複数の値があると、どれを比較したら良いのかわからない。
そこで、サブクエリの結果が複数の値になる場合は比較演算子ではなくINを使用する。
データ整合性を維持する仕組み
トランザクションとは
トランザクションとは分割することのできない人まとまりの処理のこと。
- 「口座Aからの引き落としの処理」
- 「口座Bへの入金処理」
片方だけ実施されると処理に矛盾が生じる。
そのようなことにならないようにひとまとまりの処理のいずれかが失敗したら全体処理の開始時の状態に戻すことによってデータベースに矛盾が生じないようにする。
コミット:トランザクション処理を開始し、全部終わった時点で確定すること
ロールバック:トランザクション処理中に何か問題が発生し、その処理を開始時点に戻すこと
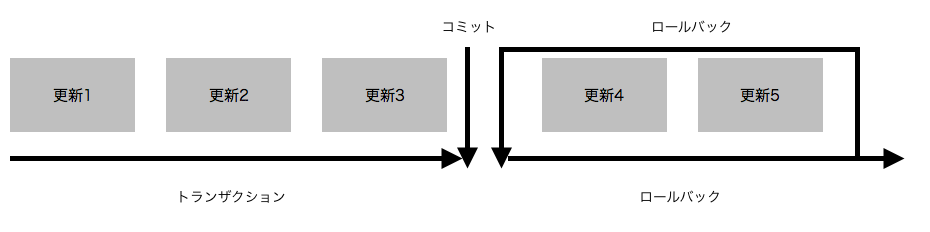
トランザクション実施例
- MySQLのストレージエンジンをトランザクションに対応したもの変更する。
※ストレージエンジン:データを格納したり検索したりといった処理を担当する部分
MySQLは複数のストレージエンジンを持っている。デフォルトのMyISAMというストレージエンジンはトランザクションに対応してないのでInnoDBというトランザクションに対応したものに変更が必要。
テーブルのストレージエンジンの調べ方
SHOW TABLE STATUS;
ストレージエンジンをInnDBに変更する
ALTER TABLE テーブル名 ENGINE = InnoDB;
- トランザクションを開始する
START TRANSACTION;
- INSERT INTO命令でテーブルにレコードを追加する
コードは省略
- 3の処理を取り消してトランザクション開始時の状態に戻す
ROLLBACK;
-
3の処理がなかった事になり、INSERT INTO命令がされる前の状態になる
-
4の時点で
COMMIT;を行うとコミットが完了する