今日でこのAdvent Calendarも最後です。
今日はその他の考慮事項と新機能について説明したいと思います。
よりスケールさせるための工夫
vte.cxはマルチテナントであり、各サービスを複数のノードに分散して管理することができます。これはスケールアウト型であり、たとえサービスが爆発的に増えたとしてもノードの追加だけで対応することができます。
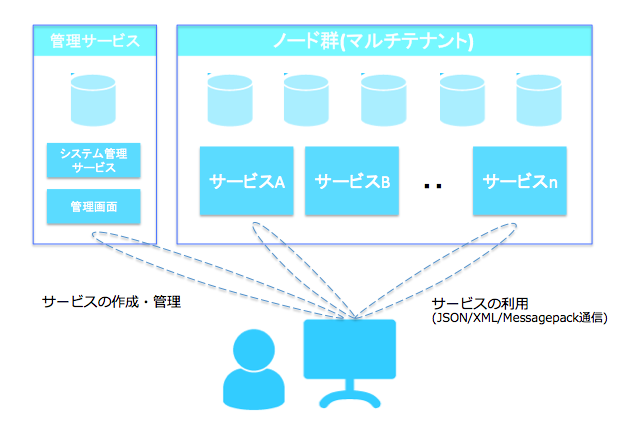
しかし、特定のあるサービスがヒットして急にアクセス数が増えた場合には、そのサービスのノードに集中してしまうため対応が困難です。
そこで、以下のようにuid配下のフォルダにデータを格納することを考えます。uidはユーザ識別子です。
こうすることで、/{uid}がノード振り分け対象となり、システム内で分散化が可能になります。
/{uid}/{ユーザ定義のフォルダ}/・・/{ユーザ定義のEntry}
どんなに巨大なデータでもユーザ単位に分割できれば分散化も可能です。
最初からスケールアウトに対応しておけば将来的にアクセスが増えても心配することはありません。
サービスのデータ設計をするうえで、ぜひ検討してみてください。
BigQueryの利用
StreamingAPIで広がるオンラインアプリケーションの世界でも述べたように、データ分析基盤としてのBigQueryの利用を考えています。
vte.cxのKVSはオンライントランザクション処理は得意ですが分析は得意ではありません。
一方、BigQueryは分析は得意ですがトランザクション更新系は不得意です。
vte.cxとBigQueryの両方の得意なところを組み合わせて、オンライン処理+分析に使おうというのが目的です。
このアーキテクチャーで面白いのはRDBが存在しないということです。
これまでの3階層Webシステムでは当然のように存在していたRDBですが、オンライントランザクションではKVSに劣り、データ分析ではDWHに勝てない、結局は中途半端なものだったというわけです。
外部ストレージの利用
BigQueryとの連携ではユーザが所有しているBigQueryアカウントを登録してもらうことで、ユーザのBigQuery環境を利用することを想定しています。つまり、BigQueryのデータはユーザ自身のものであり、利用しただけユーザに課金されるということです。
とりわけ、ユーザデータを自身の環境に保管できるのは安心感が増すと思います。
同様に、ユーザが契約しているGoogle Cloud StorageやGoogle Driveといった外部ストレージにvte.cxのコンテンツを保管できるようにすることも考えています。
また、vte.cxでは保管料にマージンを取りません。ユーザは純粋に利用した分のストレージ費用だけを負担すればいいので安心して大量のコンテンツを格納できます。
全文検索対応
外部ストレージにコンテンツを自由に格納できるようになれば、そのIndexを構築して全文検索ができるようになれば便利かなと考えています。全文検索ではLuceneがベースになると思います。
スマホ対応について
今回のAdvent Calendarでは特に触れませんでしたが、vte.cxではスマホにも対応しています。基本的な考え方は以下のようにWebとの共通のAPIを持つことです。
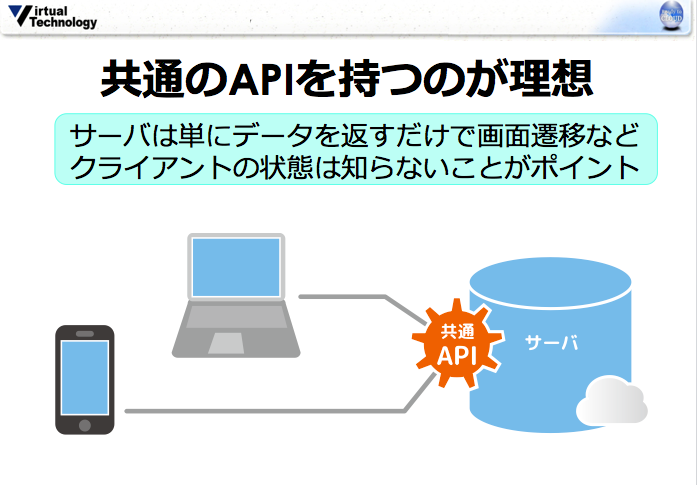
ただ、スマホからREST APIを直接アクセスするのも酷なのでSDKを準備しようと考えています。
SDKではオフライン対応を考えます。
つまり、デバイスがオフライン状態になってもアプリケーションの動作に影響はなく、オンライン状態になった時点でバックエンドとのデータ同期を自動的に行います。
アプリケーション開発者がデータ同期の方法やネットワークのオンライン、オフラインの状態を気にすることなくモバイルアプリケーションの開発をできるようにしたいと考えています。
IoT対応について
最近ではIoTがかなり注目されているようです。
vte.cxはKVSなのでIoTとも相性がいいと思っています。
今具体的に何か考えているわけではありませんが、WebSocketプロトコルと同じような感じでMQTTプロトコルにも対応できたらいいかな程度には考えています。
vte.cxとサーバレスアーキテクチャーの違い
将来的な対応を含めいろいろ書いてきましたが、結局のところvte.cxの目指すところは「フロントエンドエンジニアだけでWebシステムが作れるようになる」というところであり、PHPやRailsといったいわゆるフロントエンドサーバを駆逐して、BaaSだけでWebシステムを作れるようにすることなわけです。いわゆる、サーバレスアーキテクチャーなのですが、AWS Lamdbaなどとは大きな違いがあります。
サーバレスアーキテークチャーとの違いは、サーバレスアーキテークチャーは静的コンテンツとAPIのドメインが異なるCORSでの運用が多いのに対し、vte.cxではオーソドックスなWebアプリケーションと同じSame Origin Policyで構築できるということです。
サーバレスアーキテークチャーではステートフルなWebアプリケーションを構築しずらいという欠点があり、また、CORS環境になるため各サーバ設定が面倒になりがちで、ローカル開発環境が持てずCIによる自動化も困難になります。
一方のvte.cxでは、gulpによるローカル開発環境と簡単なデプロイ、CircleCIによる自動化などが可能であり、Same Origin Policyなので普通にステートフルなWebアプリケーションを作成できます。
ビジネス的に目指すところ
vte.cxのターゲットは、SalesforceやkintoneのようなSaaSとフルスクラッチ開発の間にあるWebシステムと考えています。Salesforceやkintoneではちょっとものたりないがフルスクラッチ開発するような体力がないといったケースが当てはまると思います。
もちろん、単純にWebページをホストするだけのCMSとして使うことも可能ですが、データベースを伴う業務システムの基盤として利用していただく方がより効果を発揮できると思います。
これまで説明したようにvte.cxで普通に開発すればセキュリティも安全で、将来的にトランザクションが増えてもスケールするので大丈夫です。
既にいくつかの事例もありますが、私たち自身、これからもvte.cx/reflexworksを活用してWebアプリケーションをどんどん作っていこうと考えています。
というわけで、今日はおしまいです。
25日間、お付き合いいただきまして誠にありがとうございました。
今後とも、vte.cxをよろしくお願いいたします。