ちょっとしたデータの加工や集計に、ExcelやGoogle Spreadsheetは便利ですが、それが日常的な作業になってしまったら自動化したいですよね?
そこでお勧めなのがpandasです。
Pandasは Python 用のデータ処理パッケージであり、ExcelファイルやCSVなどの表形式データを読みこみ、加工や集計した上で、出力するといったことがプログラムで記述できます。また開発環境を用意しなくとも、Googleが提供する無料の開発環境であるColaboratory上で、すぐに試すことができます。
そしてPythonは、Office 98以降20年以降更新されていないVBAに代わる新たなスクリプト言語として、Microsoftが採用を検討しているという話もあります。
まずPandasの全体像を掴んでみる
Pandasでは、1次元データのことをSeries、2次元をDataFrame、3次元をPanelと呼びます。DataFrameはExcelでいうテーブルあるいはピボットテーブルに相当します。Pandas公式のチートシートの邦訳版は、全体像を掴む上で役立つでしょう。以下は、下記リンク先の資料をそのまま画像化したものになります。
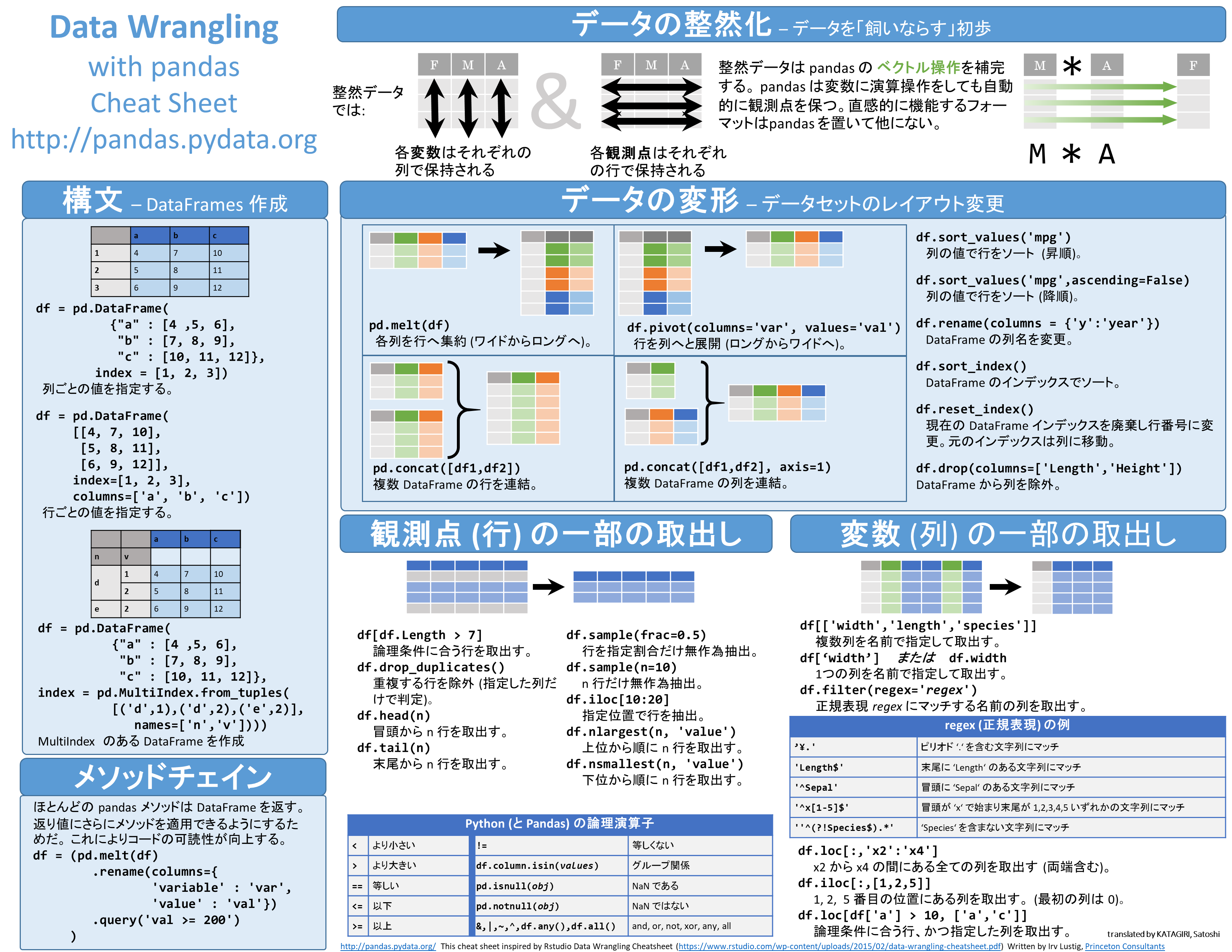

以下は、下記の記事を一部抜粋し、翻訳したものです。
集計列を加える
始めに、まずリンク先のexcelデータをpandasの DataFrameに読み込みます。
import pandas as pd
import numpy as np
df = pd.read_excel("excel-comp-data.xlsx")
df.head()
DataFrameとして格納したdfの先頭5行をhead()で求めると、以下のようになります。
| account | name | street | city | state | postal-code | Jan | Feb | Mar | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 211829 | Kerluke, Koepp and Hilpert | 34456 Sean Highway | New Jaycob | Texas | 28752 | 10000 | 62000 | 35000 |
| 1 | 320563 | Walter-Trantow | 1311 Alvis Tunnel | Port Khadijah | NorthCarolina | 38365 | 95000 | 45000 | 35000 |
| 2 | 648336 | Bashirian, Kunde and Price | 62184 Schamberger Underpass Apt. 231 | New Lilianland | Iowa | 76517 | 91000 | 120000 | 35000 |
| 3 | 109996 | D’Amore, Gleichner and Bode | 155 Fadel Crescent Apt. 144 | Hyattburgh | Maine | 46021 | 45000 | 120000 | 10000 |
| 4 | 121213 | Bauch-Goldner | 7274 Marissa Common | Shanahanchester | California | 49681 | 162000 | 120000 | 35000 |
ここで "Jan", "Feb", "Mar"の合計列"total"を追加するケースを考えます。Excelなら下記画像のように、sum(G2:I2)の列を加えることになりますね。
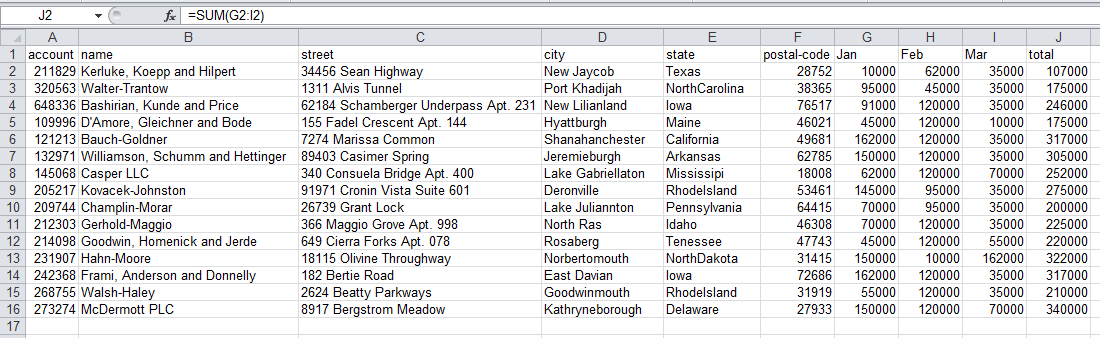
一方、pandasでは次のように記述します。
df["total"] = df["Jan"] + df["Feb"] + df["Mar"]
df.head()
| account | name | street | city | state | postal-code | Jan | Feb | Mar | total | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 211829 | Kerluke, Koepp and Hilpert | 34456 Sean Highway | New Jaycob | Texas | 28752 | 10000 | 62000 | 35000 | 107000 |
| 1 | 320563 | Walter-Trantow | 1311 Alvis Tunnel | Port Khadijah | NorthCarolina | 38365 | 95000 | 45000 | 35000 | 175000 |
| 2 | 648336 | Bashirian, Kunde and Price | 62184 Schamberger Underpass Apt. 231 | New Lilianland | Iowa | 76517 | 91000 | 120000 | 35000 | 246000 |
| 3 | 109996 | D’Amore, Gleichner and Bode | 155 Fadel Crescent Apt. 144 | Hyattburgh | Maine | 46021 | 45000 | 120000 | 10000 | 175000 |
| 4 | 121213 | Bauch-Goldner | 7274 Marissa Common | Shanahanchester | California | 49681 | 162000 | 120000 | 35000 | 317000 |
集計行を加える
次に、各列の合計値を求めるケースを考えます。Excelの場合、SUM(G2:G16)という記述を集計したい列ごとに記入する必要があります。
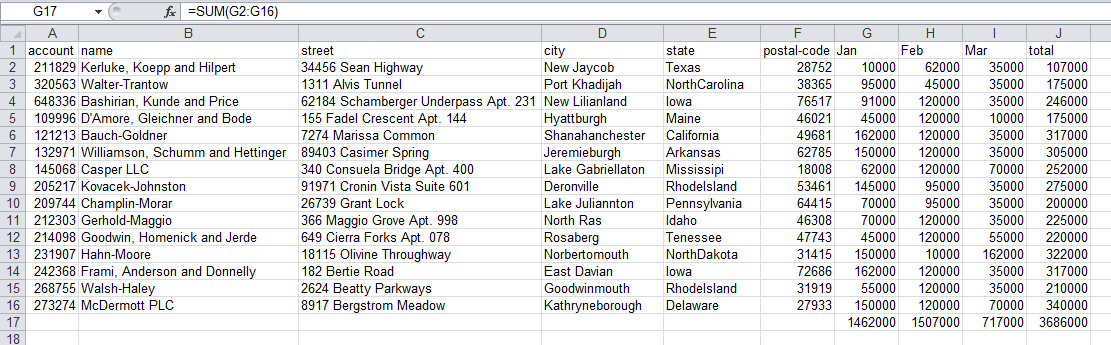
pandasなら次のように記述できます。
df["Jan"].sum(), df["Jan"].mean(),df["Jan"].min(),df["Jan"].max()
(1462000, 97466.666666666672, 10000, 162000)
あるいは次のように記述することで、Seriesとして結果を取り出すことができます。
sum_row=df[["Jan","Feb","Mar","total"]].sum()
sum_row
Jan 1462000
Feb 1507000
Mar 717000
total 3686000
dtype: int64
sum_rowの型はこの時点ではSeriesですが、DataFrameの型に変換し、転置することで、一行の表になります。
df_sum=pd.DataFrame(data=sum_row).T
df_sum
| Jan | Feb | Mar | total | |
|---|---|---|---|---|
| 0 | 1462000 | 1507000 | 717000 | 3686000 |
先ほど求めたdf_sumを、dfの列に対応付けてみましょう。するとdf_sumは次のような内部状態となります。※ NaNはExcelでいう#N/A
df_sum=df_sum.reindex(columns=df.columns)
df_sum
| account | name | street | city | state | postal-code | Jan | Feb | Mar | total | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN | NaN | NaN | 1462000 | 1507000 | 717000 | 3686000 |
最後に、次のようにdfとdf_sumを結合できます。
df_final=df.append(df_sum,ignore_index=True)
df_final.tail()
以下は、結合したdf_finalの末尾5行をtail()で表したものです。
| account | name | street | city | state | postal-code | Jan | Feb | Mar | total | |
|---|---|---|---|---|---|---|---|---|---|---|
| 11 | 231907 | Hahn-Moore | 18115 Olivine Throughway | Norbertomouth | NorthDakota | 31415 | 150000 | 10000 | 162000 | 322000 |
| 12 | 242368 | Frami, Anderson and Donnelly | 182 Bertie Road | East Davian | Iowa | 72686 | 162000 | 120000 | 35000 | 317000 |
| 13 | 268755 | Walsh-Haley | 2624 Beatty Parkways | Goodwinmouth | RhodeIsland | 31919 | 55000 | 120000 | 35000 | 210000 |
| 14 | 273274 | McDermott PLC | 8917 Bergstrom Meadow | Kathryneborough | Delaware | 27933 | 150000 | 120000 | 70000 | 340000 |
| 15 | NaN | NaN | NaN | NaN | NaN | NaN | 1462000 | 1507000 | 717000 | 3686000 |
いかがでしたか?
本記事が好評でしたら、テーブルのフィルタや並び変え、ピボットテーブル編も書いてみたいと思います!