#目次
1. はじめに
2. モデル構築編
3. WEBアプリ開発編
4. 作ってみた感想
5. おまけ
1. はじめに
最近、とある友人に「空飛ぶ哺乳類」である日本の「ムササビ」と「モモンガ」を紹介してもらいました。英語で同じく「Flying Squirrel」で呼ばれているぐらい非常に似ている動物たちです。今回は、最近学んだ移転学習の手法で、VGG16という学習済みのモデルをファインチューニングし、「ムササビ」と「モモンガ」の判別AIアプリを作ってみました!
1-1. そもそも違いわからない
「ムササビ」と「モモンガ」の違いを知らない方は、こちらの2つの記事をオススメします。
簡単に言うと、「ムササビ」=「空飛ぶ座布団」、「モモンガ」=「空飛ぶハンカチ」です。
(余計にわかりにくいかも)
1-2. VGG16とは、移転学習とは
VGG16モデルは、2014年のILSVRCという大規模な画像認識のコンペティションで2位になった、オックスフォード大学VGG(Visual Geometry Group)チームが作成した全16層の畳み込みニューラルネットワーク(CNN)の画像認識モデルです。この素晴らしいモデルを基本構成とし、こちらで準備したムササビとモモンガの画像データを使い、判別モデルにファインチューニング(移転学習)を行います。詳細は「2.モデル学習編」の移転学習とチューニングの部分をご確認ください。
1-3. 使用したもの
このAIアプリの開発は以下ものを使用しています。
Pythonライブラリー
・Python 3.9.7
・numpy 1.20.3
・tensorflow 2.7.0
・keras 2.7.0
・OpenCV 4.1.0
・matplotlib 3.4.3
・Flask 2.0.2
WEBアプリ開発
・Bootstrap 5.0
環境
・Google Colab ※AIモデルを学習する環境
・Visual Studio Code ※WEBアプリ開発のエディター
・Heroku ※WEBアプリのホスティング
1-4. 成果物
「ムササビ」「モモンガ」判定アプリは、Herokuに公開しています。
無料で構築できるサーバーですので、最初の読み込みに時間かかります。
作り方については、「3. WEBアプリ開発編」をご確認ください。
2. モデル構築編
今回の判別AIモデルを作成する主な流れは、概ね下記5つのステップです。
- 画像データの収集 → 2. 画像データの前処理 → 3. モデルの構成設定 →
- 画像データを使って移転学習 → 5. ハイパラメーターの調整と評価
2-1. データ収集
まずGoogleを使ってムササビとモモンガの画像を探してダウンロードします。
最終的にムササビ80枚、モモンガ80枚の画像を用意しました。
最初の30枚ぐらいをGoogle検索で探すのは楽勝でしたが、そのあと重複がないかを気をづけながら集めるのは大変でした。
途中Google Imagesという画像で検索するサービスを発見しました。
アップロードした画像と類似するものを勝手に探してくれるので、データ収集作業はすごく楽になりました。
画像データをダウンロード後、ファイル名に変な記号や空白スペースがあるだと、この後のPython処理にデータをうまく読み込みできないため、ファイル名の一括変換と空白スペースを取り除く処理を行いました。
空白スペースを取り除く処理は、ネットで見つけたRemoveBlank.batファイルで行いました。このbatファイルを画像フォルダに配置し実行すれば、空白スペースがなくなります。
:renameNoSpace [/R] [FolderPath]
@echo off
setlocal disableDelayedExpansion
if /i "%~1"=="/R" (
set "forOption=%~1 %2"
set "inPath="
) else (
set "forOption="
if "%~1" neq "" (set "inPath=%~1\") else set "inPath="
)
for %forOption% %%F in ("%inPath%* *") do (
if /i "%~f0" neq "%%~fF" (
set "folder=%%~dpF"
set "file=%%~nxF"
setlocal enableDelayedExpansion
echo ren "!folder!!file!" "!file: =!"
ren "!folder!!file!" "!file: =!"
endlocal
)
)
最後に画像フォルダこんな感じにきれいに準備しました。
画像を見るだけで癒されます ![]()

2-2. 学習開始前の準備
今回のAIモデルの学習環境は、Google Colaboratory(略称: Colab)を使用します。
モデル学習を開始する前の準備を行います。
2-2-1. データアップロード
新しいColabノートブックを作成後、まず学習データのフォルダを作成し、画像データをアップロードしました。
データをアップロード後、フォルダに「.ipynb_checkpoints」という謎なファイルが生成される場合があります。データをAIに読み込ませる処理の邪魔になるので、Colabのコード行を追加しこちらのコードを使って削除を行いました。
rmdir ./data_folder/{フォルダ名}/.ipynb_checkpoints
また、私の場合、画像データを2、3回アップロードし直すことがありました。Colabのファイルパネルからデータを一括削除する方法がないため、こちらのコードでフォルダからファイルの一括削除をしました。
from pathlib import Path
for f in Path('./data_folder/{フォルダ名}/').glob('*.*'):
try:
f.unlink()
except OSError as e:
print("Error: %s : %s" % (f, e.strerror))
2-2-2. 必要なライブラリーをインポート
次、新しいコード行を追加して、下記のコードで今回のモデル学習とテスト必要なライブラリーをインポートします。
# ファイル処理用のOS
import os
# 画像処理用のOpenCV
import cv2
# 計算処理と画像を表示するツール
import numpy as np
import matplotlib.pyplot as plt
# 深層学習に必要なものをKerasでインポート
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# 今回のベースモデルのVGG16
from tensorflow.keras.applications.vgg16 import VGG16
2-2-3. 画像データの読み込み
VGG16モデルに画像データを学習させるため、画像データのサイズ変更、クラスラベリング、データセットの分割(学習用とテスト用)を行いました。処理の詳細は、コードのコメントをご確認ください。
# ファイル一覧を取得
path_momonga = os.listdir('./data_folder/momonga/')
path_musasabi = os.listdir('./data_folder/musasabi/')
# 画像データを格納する配列を準備
img_momonga = []
img_musasabi = []
# 画像データをサイズ変換を行い、配列に格納
# VGG16のInput層は50x50
for i in range(len(path_momonga)):
img = cv2.imread('./data_folder/momonga/' + path_momonga[i])
img = cv2.resize(img, (50,50))
img_momonga.append(img)
for i in range(len(path_musasabi)):
img = cv2.imread('./data_folder/musasabi/' + path_musasabi[i])
img = cv2.resize(img, (50,50))
img_musasabi.append(img)
# 画像データ(X)とラベル(y)の生成
# クラスラベル0がモモンガ、1がムササビ
X = np.array(img_momonga + img_musasabi)
y = np.array([0]*len(img_momonga) + [1]*len(img_musasabi))
# データのIndexをシャフル
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データを学習セットとテストセットに2つ分ける
# 学習データ全体の75%、テストデータは残りの25%
X_train = X[:int(len(X)*0.75)]
y_train = y[:int(len(y)*0.75)]
X_test = X[int(len(X)*0.75):]
y_test = y[int(len(y)*0.75):]
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# データの構成をチェック(必要ではない)
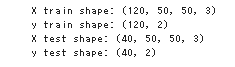
print("X train shape: {0}".format(X_train.shape))
print("y train shape: {0}".format(y_train.shape))
print("X test shape: {0}".format(X_test.shape))
print("y test shape: {0}".format(y_test.shape))
ここまでのコードを実行した結果は想定通りの学習データ120枚、テストデータ40枚です。
2-3. 移転学習とチューニング
いよいよデータの準備ができましたので、学習モデルの設定に入ります。
2-3-1. VGG16の基本構成設定
はじめに、モデルのアーキテクチャを定義します。VGG16を読込する際に、include_topをfalseにし、VGG16の特徴抽出部分のみを使いてそれ以降のモデルは自分で作成したモデルと結合するのは、移転学習(ファインチューニング)の手法です。
# VGG16を読込、include_topをFalse, 既存weightsを読み込め
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# ファインチューンモデルの定義
# Dense 256(relu), Dropout 0.5, Dense 2(softmax)の構成でスタート
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# VGG16モデルとファインチューンモデルを結合
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# モデルの19層目までがVGGのモデルに固定
for layer in model.layers[:19]:
layer.trainable = False
# モデルの構成確認
model.summary()
この部分のコードを実行して、モデルの全体構成を確認します。
ハイライトされた部分は、今回追加したファインチューンモデルの層です。

2-3-2. 学習開始
モデルの構成が問題なさそうですので、このままコンパイルし学習を始まります。
# モデルコンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
# モデル学習
model.fit(X_train, y_train, batch_size=10, epochs=30)
# 学習済みWeightsを保存
model.save_weights('flyingS001.hdf5')
#学習済みmodelを保存(アプリ開発時に使う.h5ファイル)
model.save('flyings.h5')
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=0)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
学習する部分は大きくないため、GPUマシンを使わず、全体の処理時間は約2分ぐらいかかりました。

初回の精度は**67.5%**ですね。
2-3-3. モデルのチューニング
モデルの構成やハイパラメターを調整し、判別モデルの精度を評価する繰り返し作業(チューニング)を行いました。
データ数が少ない中、精度が90%以上出すのはなかなか難しいため、5回のチューニングを行って、4度目のモデル(精度85.3%のモデル)を今回の判定アプリに採用することにしました。
| Ver | レイヤー構成 | バッチサイズ(Batch_size) | エポック(Epochs) | VGG固定層数 | 結果精度 | 前回比 |
|---|---|---|---|---|---|---|
| 1 | Dense256(relu), Dropout 0.5, Dense2(softmax) | 10 | 30 | 19 | 67.5% | |
| 2 | Dense256(relu), Dense256(relu), Dense2(softmax) | 10 | 30 | 19 | 72.1% | |
| 3 | Dense256(relu), Dropout 0.5, Dense2(softmax) | 10 | 30 | 19 | 77.5% | |
| 4 | Dense256(relu), Dropout 0.5, Dense2(softmax) | 10 | 30 | 15 | 85.3% | |
| 5 | Dense256(relu), Dropout 0.5, Dense2(softmax) | 12 | 30 | 15 | 62.5% |
2-3-4. 試し実行
学習したモデルを使って画像を入れて判別結果を確認しました。
確認用のコードはこちらです。
# 学習済みモデルのweightsを読込
model.load_weights('flyingS001.hdf5')
# 画像を一枚受け取り、モモンガかムササビかを判定して返す関数設定
def pred_fly(img):
x = cv2.resize(img, (50,50))
pred = np.argmax(model.predict(x.reshape(1,50,50,3)))
if pred == 0:
return "momonga"
else:
return "musasabi"
# pred_fly関数に写真を渡して判別を予測します
path_test = os.listdir('./data_folder/test/')
for i in range(6):
img = cv2.imread('./data_folder/test/' + path_test[i])
b,g,r = cv2.split(img)
rgb_img = cv2.merge([r,g,b])
plt.imshow(rgb_img)
plt.show()
print(pred_fly(rgb_img))
テストするため、ランダムで選んだムササビ画像3枚と、モモンガ画像3枚を
新規作成したtestフォルダにアップロードしました。
上記のコードを実行して、結果を確認します。


6枚の中5枚的中で、悪くないモデルですね。
このモデルをWEBアプリに作って、さまざまな画像を試せるのは楽しみです。
3. WEBアプリ開発編
開発されたモデルのままだと、Colabやpythonの実行環境を持つ人しか実行できないので、誰でも判別モデルを楽しめるため、WEBアプリを作りました。基本的な手順は以下のとおりです。
3-1. アプリの構造
ユーザーがファイルをアップロードして、OCRの判定結果とアップロードした画像を返すアプリを実現するため、以下のアプリ構造を設計しあした。
3-1-1. フォルダとファイル構成
アプリのルートフォルダ名は、flyingsquirrelにして、あらかじめ用意したBootstrapのcssとjs、モデルファイル(.h5)、アプリを動かすmain.pyなどを下記のフォルダ配置にしました。
flyingsquirrel/
├ static/
│ ├ whoami.png #アップロード前表示する画像
│ ├ css/
│ │ └ bootstrap.min.css
│ │ └ stylesheet.css #カスタムCSS用
│ ├ js/
│ │ └ bootstrap.min.js
│ └ uploads/
│ └ .gitkeep #仮置きファイル(Herokuアップロード対策用)
├ templates/
│ └ index.html
├ main.py
├ flyings.h5 #AIモデル
├ Procfile #Heroku定義ファイル
├ runtime.txt #Heroku定義ファイル
└ requirements.txt #Heroku定義ファイル
3-1-2. Heroku定義ファイル
Herokuにデプロイするための定義ファイル3点セットです。
web: python main.py
python-3.9.7
absl-py==0.10.0
astor==0.8.1
bleach==3.1.5
bottle==0.12.18
click==7.1.2
certifi==2020.6.20
chardet==3.0.4
flask==2.0.1
future==0.18.2
gast==0.4.0
grpcio==1.34.0
gunicorn==20.0.4
h5py==3.1.0
html5lib==1.1
itsdangerous==2.0
idna==2.10
Jinja2==3.0.1
line-bot-sdk==1.16.0
Markdown==3.2.2
MarkupSafe==2.0
numpy==1.19.3
oauthlib==3.1.0
pillow==7.2.0
protobuf==3.12.4
PyYAML==5.4.1
python-dotenv==0.14.0
requests==2.25.1
scipy==1.7.1
six==1.15.0
tensorboard==2.5.0
tensorflow-cpu==2.5.0
termcolor==1.1.0
urllib3==1.26.5
Werkzeug==2.0.0
3-2. アプリのコード
今回作成したアプリのコードを解説します。
3-2-1. main.py
main.pyはアプリの全体処理をコントロールする役割になります。
各処理の詳細は、コメントに記載してあります。
import os
from flask import Flask, request, redirect, render_template, flash, url_for
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
# 変数の定義
image_size = 50
UPLOAD_FOLDER = "static/uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
# Flaskのappを定義
app = Flask(__name__)
app.secret_key = '{secret}'
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
# 学習済みモデルを読み込み
model = load_model('./flyings.h5')
# ページの処理
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if allowed_file(file.filename) == False:
flash('ファイルの拡張子が正しくないです')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
# 受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
# 判別AI予測処理
predict = np.argmax(model.predict(data.reshape(1,50,50,3)))
if predict == 0:
pred_answer = "これは「モモンガ」です"
else:
pred_answer = "これは「ムササビ」です"
# 判別結果メッセージとアップロード画像を返す
return render_template("index2.html",answer=pred_answer, filename=filename)
return render_template("index2.html",answer="")
@app.route('/display/<filename>')
def display_image(filename):
return redirect(url_for('static', filename='uploads/' + filename), code=301)
# アプリ実行
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
3-2-2. index.html
テンプレートとなるindex.htmlのhead部分には、表示したいタイトルやメタ情報、利用するCSSを入れました。
<!doctype html>
<html lang="ja" class="h-100">
<head>
<meta charset='UTF-8'>
<meta name='viewport' content="device-width, initial-scale=1.0">
<meta http-equiv='X-UA-Compatible' content="ie=edge">
<meta name="discription" content="AIが送信された画像を「ムササビ」か「モモンガ」に判別します。">
<title>「ムササビ」「モモンガ」判別AIアプリ</title>
<!-- OG Meta -->
<meta property="og:title" content="「ムササビ」「モモンガ」判別AIアプリ">
<meta property="og:type" content="website">
<meta property="og:image" content="https://flying-squirrel-ai.herokuapp.com/static/whoami.png">
<meta property="og:url" content="https://flying-squirrel-ai.herokuapp.com/">
<meta property="og:description" content="AIが送信された画像を「ムササビ」か「モモンガ」に判別します。">
<meta property="og:locale" content="ja_JP">
<!-- CSS -->
<link href="./static/css/bootstrap.min.css" rel="stylesheet">
<link href="./static/css/stylesheet.css" rel="stylesheet">
</head>
次はbodyの部分です。containerの部分を2つコラムに分けています。
左側に画像、右側にアップロードフォームを表示する設計になります。
アップロード画像がない時は、if分岐で?の画像を表示します。
<body class="d-flex flex-column h-100">
<header>
<!-- Fixed navbar -->
<nav class="navbar navbar-expand-md navbar-dark fixed-top bg-dark">
<div class="container-fluid">
<a class="navbar-brand" href="#">「ムササビ」「モモンガ」判別AIアプリ</a>
</div>
</nav>
</header>
<!-- Begin page content -->
<main class="flex-shrink-0">
<div class="container">
<div class="row">
<div class="col-md-5 offset-md-1">
{% if filename %}
<h3>{{answer}}</h3>
<img class="upload_image" src="{{ url_for('display_image', filename=filename) }}">
{% else %}
<img class="upload_image" src="./static/whoami.png">
{% endif %}
</div>
<div class="col-md-5 offset-md-1">
<h2 class="mt-5"><u>ムササビ</u>か<u>モモンガ</u>かAIが判別します。</h2>
<p class="lead">画像を送ってみてください。</p>
{% with messages = get_flashed_messages() %}
{% if messages %}
<div class="alert alert-warning d-flex align-items-center" role="alert">
<div>
{% for message in messages %} {{ message }} {% endfor %}
</div>
</div>
{% endif %}
{% endwith %}
<form method='POST' enctype="multipart/form-data">
<div class="mb-3">
<input class='form-control' type="file" name="file" id="file">
</div>
<div class="d-grid gap-2">
<input class='btn btn-primary' value="送信" type="submit">
</div>
</form>
</div>
</div>
</div>
</main>
最後のフッターのところに、Copyright情報とjsのインポートをして完了です。
<footer class="footer mt-auto py-3 bg-light">
<div class="container">
<span class="text-muted">Copyright ©2021 Johnson Lin</span>
</div>
</footer>
<script src="./static/js/bootstrap.bundle.min.js"></script>
</body>
</html>
3-2-3. style.css
アプリの基本デザインはBootstrapのデフォルトを使いますので、一部だけの微修正をstyle.cssに入れました。
/* Mainを下に移動 */
main > .container {
padding: 80px 15px 0;
}
/* アップロードファイルのサイズ調整 */
.upload_image {
width: 100%;
height: auto;
}
3-3. Herokuにデプロイ
最後に完了したアプリの動作確認し、Herokuにアップロードする手順を説明します。
3-3-1. ローカル環境で検証
まずローカル環境で、アプリがちゃんと動くかどうかを確認します。
アプリをローカル端末に立ち上げるコマンドはこちらです。
cd /path/to/flyingsquirrel/
python main.py
* Serving Flask app 'main' (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on all addresses.
WARNING: This is a development server. Do not use it in a production deployment.
* Running on http://192.168.0.6:8080/ (Press CTRL+C to quit)
そして、ブラウザーで上記のIPアドレスを開いて確認します。
アップロードを試すと、可愛いモモンガたち画像と結果が正しく表示されました。

ファイルのバリデーションも動作しているようですので、これで確認が終了です。
3-3-2. Herokuプロジェクト作成
Herokuのアカウントを新規作成した後、新しいプロジェクトを作りました。
プロジェクト名がURLの一部になりますので、「flying-squirrel-ai」に決めました。
実際のURLはこうなります→https://flying-squirrel-ai.herokuapp.com/
そして、今回のアプリはpythonで作成されているため、
プロジェクト画面のSettings > Buildpack > Add Buildpackを開き、
pythonを選択して設定を保存します。

これでHeroku側の初期設定が完了しました。
3-3-3. デプロイ
そして最後のデプロイ作業に入ります。
まずは、Herokuにログインします。
cd /path/to/flyingsquirrel/
heroku login
heroku: Press any key to open up the browser to login or q to exit:
Opening browser to https://cli-auth.heroku.com/auth/cli/browser/xxxxxxxxxx?requestor=xxxxxxxxxxxxxxx
Logging in... done
Logged in as johnson.lin@email.com
次、gitの初期化を行い、ローカルのアプリフォルダをherokuにアップロード先に繋ぎます。
git init #初回のみ
heroku git:remote -a (アプリ名)
最後に今のアプリをgitにコミットし、Herokuにデプロイします。
git add .
git commit -m "変更メッセージ"
git push heroku master
初回のデプロイ時に、requirements.txtに記載されているモジュールのインストールも行うため、十数分時間かかりますが、「remote: Verifying deploy... done.」というメッセージが表示されたら、デプロイが完了しました。
そして、ブラウザーにURLを入力して開くか、ターミナルにてheroku openでアップロードしたアプリを確認します。

問題なく読み込みできたですね。肝心の判別AIは?

こちら問題なく動作しました。ムササビさんの万歳ポーズで締めて、本プロジェクトは以上で終了します。
4. 作ってみた感想
今回はVGG16の移転学習を使って、「ムササビ」と「モモンガ」を判別するAIモデルを短時間(16時間ぐらい?)に開発しました。やはりAI・機械学習の分野では、先行者たちのおかげさまで様々な基盤が整えてきて、私みたいなAI初心者でも実用性のあるAIモデルを作れる時代になってきたと感じます。
そして、判定アプリを作りながら、可愛い動物たちの画像を見て癒されるのは、思わぬメリットでした。
5. おまけ
おまけに、何点か「モモンガ?」「ムササビ?」の画像を試した結果を共有します。
最後までこの記事を読んでいただき、ありがとうございました。
漫画版ムササビ

銅像ムササビ

人間ムササビ(笑)

モモンガぬいぐるみ

対戦カードモモンガ(!?)どっちかというとムササビっぽいだが。。
