- goal:pythonを使ってジョブ情報を集めましょう。
- language:python
- IDE: repl.it https://replit.com/
- framework: flask
- 講座:https://nomadcoders.co/python-for-beginners/lobby (音声:英語、字幕:韓国語)
1.htmlとpythonを連動しましょう。
1.repl.itスタート
pythonだけでなく支援する言語が幅広くて、自分のPCに限らずコーディングができます。
また、協業にも結構使われているそうなので後の共通プロジェクトにも活用できると思います。

まずは自分が使いたい言語を選んでMY REPLを作成しましょう。
2.flaskをインストールしましょう。
flaskとはpython用 web freamworkです。単純に申しますと、python <> htmlでデータのやり取りができるようにすることです。
それではrepl.itからflaskをインストールしましょう。
(何もインストールしないと書いててインストールしましょう、はおかしいかもしれないですが、、パッケージのインストールは避けられません。。)
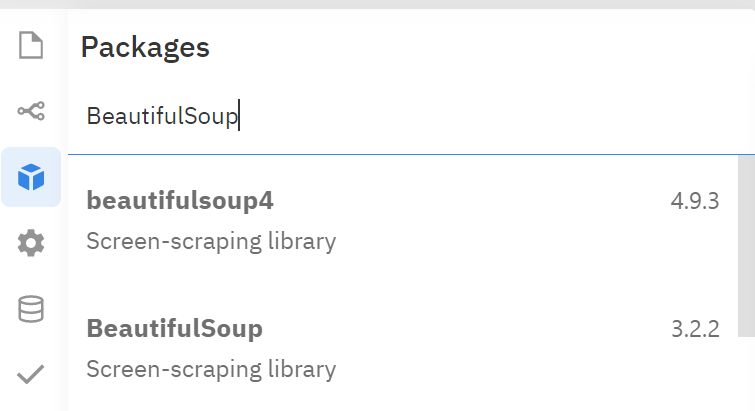
左側のボックスアイコンをクリック → インストールしたいパッケージ名を検索します。

3.flaskを使ってみよう。
まずはflaskを使いたいpythonファイルで(自分の場合はmain.pyでした)必要な機能だけimportしましょう。
main.py
from flask import Flask, render_template, request, redirect, send_file
// ① Flaskの名前を付けます。
app = Flask("this is the site for practicing Flask")
# ③ メイン画面を設定しましょう。
@app.route("/")
def home():
return render_template("input_keyword.html")
// ② repl.it用のurlでIDEによってホスト番号に差はあるそうです。
app.run(host="0.0.0.0", port=8080)
templatesフォルダーを生成 → フォルダー内にメイン画面用htmlを作ります。
input_keyword.html
<!DOCTYPE html>
<html>
<head>
<title>job searching</title>
</head>
<body>
<h1>Job search</h1>
</body>
</html>
Runボタンをクリックして連動結果を確認しましょう。少々時間がかかります。

4.検索機能を追加しましょう。
ユーザーが画面から入力したキーワードをpythonに渡されるようにしましょう。
input_keyword.html
<body>
# 入力した内容を"0.0.0.0/result?word=XXX"のように送ります。
<h1>Job search</h1>
<form action="/result" method="get">
<input placeholder="what do you want" required name="word"/>
<button>search</button>
</form>
</body>
htmlからの信号をpythonで受け取るようにしましょう。
main.py
@app.route("/result")
def home_report():
word = request.args.get("word")
if word:
# 大・小文字の区分付けをしたいなら不要です。
word = word.lower()
else:
return redirect("/")
2.pythonのweb scrppingスタート
- request, BeautifulSoupをインストールしよう。

green.py
import requests
from bs4 import BeautifulSoup
def get_page_max_num(URL):
# ⓪ input_keyword.html の入力キーワードをこのurlで入れることで検索させます。
URL = "https://www.green-japan.com/search_key/01?key=2vkn2gx21xjyx34dfj15&keyword=python&&page=1"
# ① urlのソース情報を持ってきます。
result = requests.get(URL)
# ② HTMLにbeautiful化(。。。)が必要です。
soup = BeautifulSoup(result.text, "html.parser")
# ③_① 探したい情報を find(タグ名、クラス名)で探したり
pages = soup.find("div", "pagers")
# ③_② find_all(タグ名)で探しましょう。
page_num = pages.find_all("a")
3.結果を画面表示、ダウンロードしましょう。
csv出力機能はインストール不要です。
csv出力
exporter.py
import csv
def save_to_file(jobs):
file = open("jobs.csv", mode="w")
writer = csv.writer(file)
writer.writerow(["company_name","salary","address","language"])
for job in jobs:
writer.writerow(job)
return
画面表示
main.py
# "result.html" にsearchingby、resultNumber、jobsに 送信したい文字情報を格納して送りします。(皆string)
return render_template("result.html",searchingby=word, resultNumber=len(jobs),jobs=jobs)
result.html
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<h1>Search Results</h1>
<h3>You are looking {{searchingby}} which has {{resultNumber}} notices </h3>
<a href="/export?word={{searchingby}}">Export to csv</a>
<section>
<h4>Company_name</h4>
<h4>Salary</h4>
<h4>Address</h4>
<h4>language</h4>
# jobs は[{”company_name”=””、... },{}.. ]で届くようにします。
{% for job in jobs %}
<span>{{job.company_name}}</span>
<span>{{job.salary}}</span>
<span>{{job.address}}</span>
<span>{{job.language}}</span>
{% endfor %}
</section>
</body>
</html>
- 今までweb scrappingにほぼ基本ばかりでした。
ホームページごとにHTMLの構造が違いため、自分の意図にあうコードまでたどりつく方法は皆違います。しかし、上記は共通機能なので勉強した内容のメモがてら記入しました。参考になりましたら嬉しいですー