カテゴリカル変数の変数型
業務上で2値分類のタスクでモデルを実装する際に、「カテゴリカル変数をint型とdouble型のどちらかにすることで違いは出るのか」という疑問が起きました。自明すぎて疑問に思わないかもしれませんが、自明ならどこかで言及してほしいタチなので、決定木の場合で調査も含め簡単に検証してみました。(おそらくGBM系のツリーモデルでも同じでしょう)
例えば、名義尺度であるカテゴリカル変数を機械学習のモデルに投入する際に、数字に置き換えてマッピング(ダミー変数化)します。その時、概念として小数はありえなくint型のはずですが、doubleにしたら影響は出るのでしょうか??
結論から言いますと、アルゴリズム上はデータをint型にしようが、double型にしようが結果に影響はありません。ですが、普通に考えて概念上間違っていますし、無駄なメモリを使うことになるので個人的に理由もなくエンコードされたカテゴリカル変数をdouble型(float型)にすることは、お勧めはしません。
1.アルゴリズムの観点では影響はない
木を枝分かれさせる際の分割は説明変数の値の中間が使われるため、double型にしても1と0のone-hotエンコーディングされた変数は常に0.5で分割され、そうでない変数も、ラベル4と5の間での分割なら4.5を分割がなされます。だから、説明変数のデータがint型1か0ではなく、1.000か0.0000になっても分割は1.300など半端な場所ではなく、1.500でなされます。性別という変数をdouble型にして、1.000が男、0.000が女で分割が0.700のような所分割されることはなく0.500で行われる。
教科書を見ると、分割はgini係数、entropyなど情報利得が最大になるようになされるということは紹介されますが、実際はランダムなところから分割がなされるので、実装時にどのように分割を試行していくかは言及が私が知る限りありません。
他に下の記事でも紹介があります:
1.「FindBestSplitを書いてみる」
2.「CART Algorithm for Decision Tree」
また、scikit-learnのtreeの中にあるBestSplitterというクラスのソースコードを見てもそれらしい記述があります。(ここで本当に正しいか自信はないが)
2.無駄にメモリを使うことになる
計算結果への影響はないのですが、本来int型で済むところをdouble型にしているので、無駄にメモリを使う事になります。
検証題材
Kaggleで有名なTitanicの生存者予測のデータを使って検証を行います。ここではpythonでjypyter notebookで行います。pythonではdouble型=float型としてとらえていただければと思います。
ライブラリーのインポート
import os, time
import numpy as np
import pandas as pd
from sklearn.model_selection import cross_val_score
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
import graphviz
データのインポートからデータ前処理
データはここでダウンロードできます。
%%time
# データインポート
train = pd.read_csv('./titanic/train.csv')
test = pd.read_csv('./titanic/test.csv')
# 特徴量とターゲットの定義
features = [i for i in train.columns if i not in ['PassengerId', 'Survived','Name', 'Ticket', 'Cabin']]
target = train['Survived']
# マッピング
train['Sex'] = train['Sex'].map({'male':1, 'female':0})
train['Embarked'] = train['Embarked'].map({'S':1, 'C':2, 'Q':3, np.nan:4})
# 欠損値補完(中央値)
train['Age'] = train['Age'].fillna(train['Age'].median())
決定木の作成
# 決定木の定義
%%time
clf = DecisionTreeClassifier(random_state=0, max_depth = 3)
clf.fit(train[features], target)
# 結果の可視化
dot_data = tree.export_graphviz(clf, out_file=None,feature_names=train[features].columns, max_depth=2)
graph = graphviz.Source(dot_data)
graph
このとき、変数の型を確認します。
for i in features:
print('data type of '+ str(i)+ ' is: '+str(train[i].dtype))
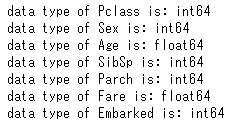
性別:Sexと、搭乗船室クラス:Pclassは名義尺度なため、int型になっています。
この時の決定木による分割は下です。
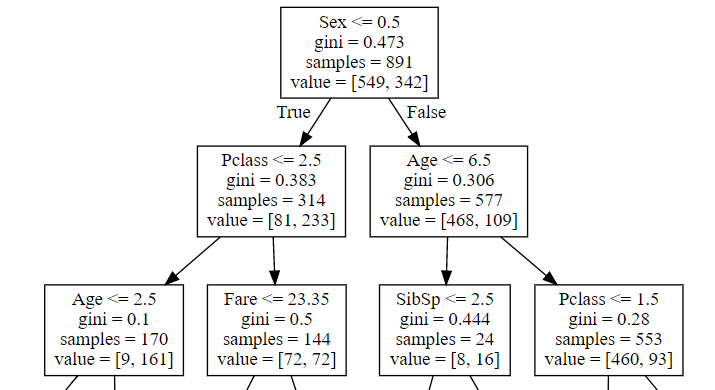
次に、性別と搭乗クラスをdouble=float型に変換してみます。
# float型へ変換
train['Sex'] = train['Sex'].astype('float')
train['Pclass'] = train['Pclass'].astype('float')
# 型の確認
for i in features:
print('data type of '+ str(i)+ ' is: '+str(train[i].dtype))
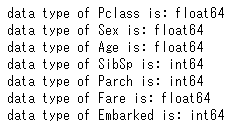
再度決定木を分岐させてみます。
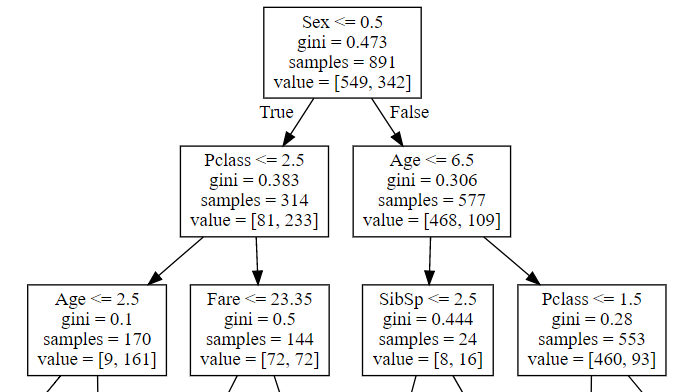
以上のように、変数の型がint型、float型に関わらず、分岐は同じで、XX.5で分岐がなされます。
気づき、修正点などございましたら、コメント頂ければと思います!