はじめに
Aidemyの「データ分析コース」を受講し、成果物として取り組んだ年収予測の分析過程記載させていただきました。
環境情報
Kaggle Notebook
概要紹介
今回の目的は、国勢調査データベースから抽出された、米国に住む個人に関する情報を使用し、年収が$50,000ドルを超えるかどうかを予測するモデルを構築することとなります。
使用したデータ
訓練データ
/kaggle/input/income/train.csv
テストデータ
/kaggle/input/income/test.csv
データのcolumn情報
age:年齢
workclass:職業クラス
fnlwgt:final weight(人口の推計値)
education:教育
educationnal-num:教育年数
marital-status:配偶者の有無
occupation:職業
relationship:関係(家族構成)
race:人種
gender:性別
capital-gain:キャピタルゲイン
capital-loss:キャピタルロス
hours-per-week:週あたりの労働時間
native-country:母国
income_>50K:年収カテゴリ(>50K, <=50K)
内容
データの読み込みと可視化
まずは訓練データとテストデータの特徴を把握するためにサイズや統計量を可視化します。
#訓練データのダウンロード
train_df = pd.read_csv("/kaggle/input/income/train.csv")
#訓練データ情報の表示
print(f"train_df_shape:{train_df.shape}\n")
print(f"train_df_dtypes:\n{train_df.dtypes}\n")
#訓練データの統計量の表示
display(train_df.describe(include='all'))
#テストデータのダウンロード
test_df = pd.read_csv("/kaggle/input/income/test.csv")
#テストデータ情報の表示
print(f"test_df_shape:{test_df.shape}\n")
print(f"test_df_dtypes:\n{test_df.dtypes}\n")
#テストデータの統計量の表示
display(test_df.describe(include='all'))
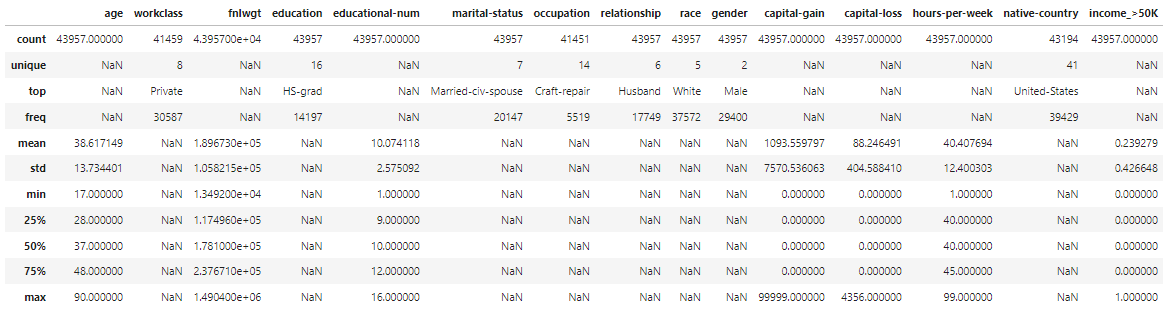
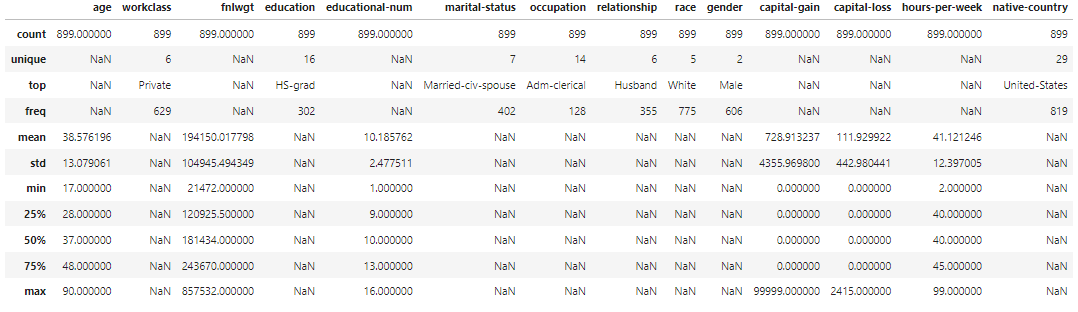
統計量を可視化することで以下の特徴が見えてきました。
・workclassとoccupation、native-countryに欠損あり
・educationnal-numの第一四分位数が”9”なのに対し、最小値が"1"なので外れ値を含む可能性あり
・hours-per-weekは最小値、最大値ともに四分位数から大きく離れているため外れ値を含む可能性あり
・capital-gainとcapital-lossの平均値と中央値が大きく離れているためデータに偏りがある可能性あり
・ income_>50Kの平均値が0.5より低いのでデータに偏りがある可能性あり
次にデータの傾向を詳細に確認するためにヒストグラムやヒートマップ、クロス集計を使用して可視化しました。
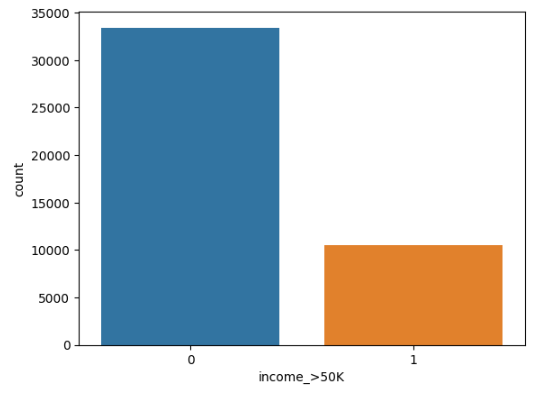
#$50K以上の人の分布を可視化
import seaborn as sns
sns.countplot(x='income_>50K', data=train_df)
# FigureとAxesの生成
fig, axes = plt.subplots(5,2,figsize=(10,25))
#ageをヒストグラムで表示し外れ値の有無を確認
# 訓練データのヒストグラム
axes[0,0].hist(train_df['age'], bins=20, color='blue', alpha=0.7, edgecolor='black')
axes[0,0].set_xlabel('age')
axes[0,0].set_ylabel('Frequency')
axes[0,0].set_title('Histogram of Train_df')
# テストデータのヒストグラム
axes[0,1].hist(test_df['age'], bins=20, color='green', alpha=0.7, edgecolor='black')
axes[0,1].set_xlabel('age')
axes[0,1].set_ylabel('Frequency')
axes[0,1].set_title('Histogram of Test_df')
#educational-numeをヒストグラムで表示し外れ値の有無を確認
# 訓練データのヒストグラム
axes[1,0].hist(train_df['educational-num'], bins=16, color='blue', alpha=0.7, edgecolor='black')
axes[1,0].set_xlabel('educational-nume')
axes[1,0].set_ylabel('Frequency')
axes[1,0].set_title('Histogram of Train_df')
# テストデータのヒストグラム
axes[1,1].hist(test_df['educational-num'], bins=16, color='green', alpha=0.7, edgecolor='black')
axes[1,1].set_xlabel('educational-num')
axes[1,1].set_ylabel('Frequency')
axes[1,1].set_title('Histogram of Test_df')
#hours-per-weekをヒストグラムで表示し外れ値の有無を確認
# 訓練データのヒストグラム
axes[2,0].hist(train_df['hours-per-week'], bins=20, color='blue', alpha=0.7, edgecolor='black')
axes[2,0].set_xlabel('hours-per-week')
axes[2,0].set_ylabel('Frequency')
axes[2,0].set_title('Histogram of Train_df')
# テストデータのヒストグラム
axes[2,1].hist(test_df['hours-per-week'], bins=20, color='green', alpha=0.7, edgecolor='black')
axes[2,1].set_xlabel('hours-per-week')
axes[2,1].set_ylabel('Frequency')
axes[2,1].set_title('Histogram of Test_df')
#capital-gainをヒストグラムで表示し外れ値の有無を確認
# 訓練データのヒストグラム
axes[3,0].hist(train_df['capital-gain'], bins=10, color='blue', alpha=0.7, edgecolor='black')
axes[3,0].set_xlabel('capital-gain')
axes[3,0].set_ylabel('Frequency')
axes[3,0].set_title('Histogram of Train_df')
# テストデータのヒストグラム
axes[3,1].hist(test_df['capital-gain'], bins=10, color='green', alpha=0.7, edgecolor='black')
axes[3,1].set_xlabel('capital-gain')
axes[3,1].set_ylabel('Frequency')
axes[3,1].set_title('Histogram of Test_df')
#hours-per-weekをヒストグラムで表示し外れ値の有無を確認
# 訓練データのヒストグラム
axes[4,0].hist(train_df['capital-loss'], bins=10, color='blue', alpha=0.7, edgecolor='black')
axes[4,0].set_xlabel('capital-lossk')
axes[4,0].set_ylabel('Frequency')
axes[4,0].set_title('Histogram of Train_df')
# テストデータのヒストグラム
axes[4,1].hist(test_df['capital-loss'], bins=10, color='green', alpha=0.7, edgecolor='black')
axes[4,1].set_xlabel('capital-loss')
axes[4,1].set_ylabel('Frequency')
axes[4,1].set_title('Histogram of Test_df')
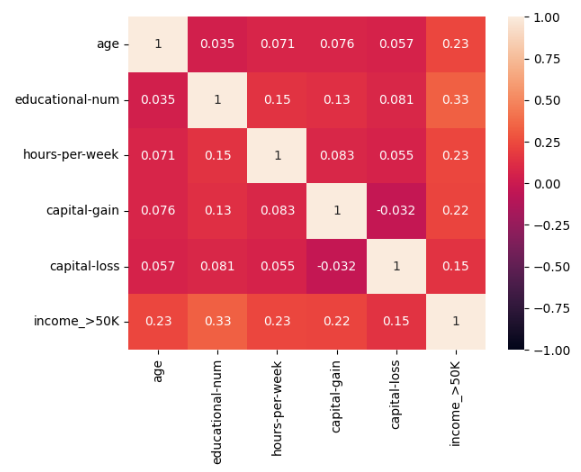
#ヒートマップで量的変数の相関関係を確認
sns.heatmap(
train_df[['age','educational-num','hours-per-week','capital-gain','capital-loss','income_>50K']].corr(),
vmax=1,vmin=-1,annot=True
)
#クロス集計でworkclassの確認
cross = pd.crosstab(train_df['workclass'], train_df['income_>50K'])
cross['%'] = cross[1] / cross[0]
print(cross)
#クロス集計でeducationの確認
cross = pd.crosstab(train_df['education'], train_df['income_>50K'])
cross['%'] = cross[1] / cross[0]
print(cross)
#クロス集計でmarital-statusの確認
cross = pd.crosstab(train_df['marital-status'], train_df['income_>50K'])
cross['%'] = cross[1] / cross[0]
print(cross)
#クロス集計でoccupationの確認
cross = pd.crosstab(train_df['occupation'], train_df['income_>50K'])
cross['%'] = cross[1] / cross[0]
print(cross)
#クロス集計でrelationshipの確認
cross = pd.crosstab(train_df['relationship'], train_df['income_>50K'])
cross['%'] = cross[1] / cross[0]
print(cross)
#クロス集計でraceの確認
cross = pd.crosstab(train_df['race'], train_df['income_>50K'])
cross['%'] = cross[1] / cross[0]
print(cross)
#クロス集計でgenderの確認
cross = pd.crosstab(train_df['gender'], train_df['income_>50K'])
cross['%'] = cross[1] / cross[0]
print(cross)
ここまでの可視化の工程によって新たに以の特徴があることがわかりました。
・全体的に$50K以上の人は少ない
・workclassとoccupationとnative-countryに欠損あり
・ageは偏りがあり、多くのデータが20代から50代となる
・capital-gainとcapital-lossはデータに偏りがあり75%以上が0をとる
・capital-gainと、capital-lossは外れ値がある
・educational-numとincome_>50Kの間には正の相関がみられる
特徴量作成
これまでの可視化の工程で分かった特徴をもとに以下の方針で特徴量を作成しました。
・fnlwgt,native-countryは欠損があり、カテゴライズしにくいため特徴量から外す
・workclassとoccupationが欠損しているデータは削除する
・capital-gainとcapital-lossは多くの値が0をとることと、値の差が激しいため、0が1以上の2つのグループにカテゴライズする
・質的データもカテゴリが少なくなるようまとめる
・workclassは自営業、行政、収入なしの3つのカテゴリにまとめる
・marital-status:既婚、結婚しているが別れたか離れて暮らしている、未婚の3つのカテゴリにまとめる
#訓練データとテストデータを連結させてall_dfを作成
all_df = pd.concat([train_df, test_df],axis=0).reset_index(drop=True)
all_df['Test_Flag'] = 0
all_df.loc[train_df.shape[0]: , 'Test_Flag'] = 1
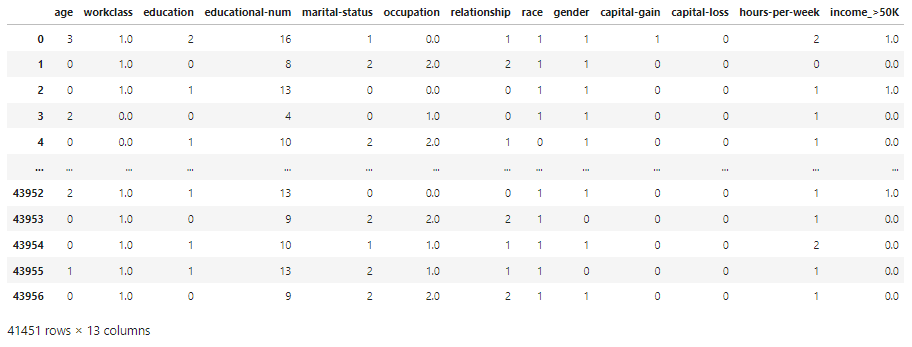
display(all_df)
#特徴量から排除する列を削除
drop_col_list = ['fnlwgt','native-country']
all_df = all_df.drop(drop_col_list,axis=1)
#量的データをカテゴリカル変数に変換
all_df['age'] = pd.cut(all_df['age'], 5, labels=[0,1,2,3,4])
all_df['hours-per-week'] = pd.cut(all_df['hours-per-week'], 4, labels=[0,1,2,3])
all_df['capital-gain'] = pd.cut(all_df['capital-gain'], bins=[0,1,100000], labels=[0,1],right=False)
all_df['capital-loss'] = pd.cut(all_df['capital-loss'], bins=[0,1,100000], labels=[0,1],right=False)
#workclassのカテゴリを行政(0)、自営業(1)、収入なし(3)の3カテゴリにまとめる
all_df = all_df.replace({'workclass':['State-gov','Federal-gov','Local-gov']},0)
all_df = all_df.replace({'workclass':['Private','Self-emp-not-inc','Self-emp-inc']},1)
all_df = all_df.replace({'workclass':['Never-worked','Without-pay']},2)
#marital-statusのカテゴリを既婚(1)、結婚したが分かれたか一緒に住んでいない(2)、未婚(3)の4カテゴリにまとめる
all_df = all_df.replace({'marital-status':['Married-civ-spouse','Married-AF-spouse']},0)
all_df = all_df.replace({'marital-status':['Divorced','Separated','Married-spouse-absent','Widowed']},1)
all_df = all_df.replace({'marital-status':['Never-married']},2)
#educationのカテゴリをクロス集計で似た傾向がみられたの3カテゴリにまとめる
all_df = all_df.replace({'education': ['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'HS-grad', 'Preschool']}, 0)
all_df = all_df.replace({'education': ['Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Prof-school', 'Some-college']}, 1)
all_df = all_df.replace({'education': ['Doctorate', 'Masters', 'Prof-school']}, 2)
#mrelationshipのカテゴリを夫か妻(1)、家族以外(2)、その他(3)の3カテゴリにまとめる
all_df = all_df.replace({'relationship': ['Husband', 'Wife']}, 0)
all_df = all_df.replace({'relationship': ['Not-in-family']}, 1)
all_df = all_df.replace({'relationship': ['Other-relative', 'Own-child', 'Unmarried']}, 2)
#raceのカテゴリをクロス集計で似た傾向がみられたの2カテゴリにまとめる
all_df = all_df.replace({'race': ['Amer-Indian-Eskimo', 'Black', 'Other']}, 0)
all_df = all_df.replace({'race': ['Asian-Pac-Islander', 'White']}, 1)
#occupationのカテゴリをクロス集計で似た傾向がみられたの2カテゴリにまとめる
all_df = all_df.replace({'occupation': ['Exec-managerial', 'Prof-specialty']}, 0)
all_df = all_df.replace({
'occupation':
[
'Adm-clerical',
'Armed-Forces',
'Craft-repair',
'Farming-fishing',
'Machine-op-inspct',
'Machine-op-inspct',
'Protective-serv',
'Sales','Tech-support',
'Transport-moving'
]
}, 1)
all_df = all_df.replace({'occupation': ['Other-service', 'Priv-house-serv','Handlers-cleaners']}, 2)
# genderのカテゴリを2に分ける
all_df['gender'] = all_df['gender'].replace('Female', 0).replace('Male', 1)
# 前処理を施したall_dfを訓練データとテストデータに分割
train_df = all_df[all_df['Test_Flag']==0]
test_df = all_df[all_df['Test_Flag']==1].reset_index(drop=True)
#訓練データから欠損値が含まれるデータを削除する
train_df = train_df.dropna()
#Test_Flag列を排除する
train_df = train_df.drop('Test_Flag', axis=1)
test_df = test_df.drop('Test_Flag', axis=1)
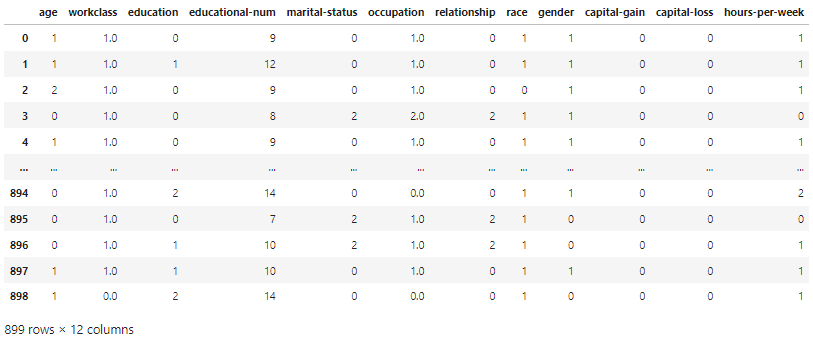
test_df = test_df.drop('income_>50K', axis=1)
モデル選択
今回はKholdを用いて複数のモデルの正解率を算出し、最も良い結果が出たモデルを採用します。
モデルの種類はロジスティック回帰、SVC、MLP、ランダムフォレスト、LightGBMの5つとし、訓練データの一部を検証データとして用いました。
from sklearn.model_selection import train_test_split
#訓練データの一部から検証データを抽出
#訓練データのincome_>50Kを教師データとする
target = train_df['income_>50K']
train_df = train_df.drop('income_>50K', axis=1)
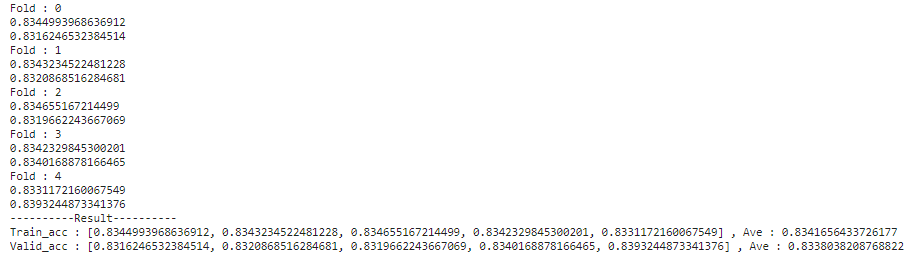
ロジスティック回帰
#ロジスティック回帰による学習
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
cv = KFold(n_splits=5, random_state=0, shuffle=True)
train_acc_list = []
val_acc_list = []
# fold毎に学習データのインデックスと評価データのインデックスが得られます
for i ,(trn_index, val_index) in enumerate(cv.split(train_df, target)):
print(f'Fold : {i}')
# データ全体(Xとy)を学習データと評価データに分割
X_train ,X_val = train_df.iloc[trn_index], train_df.iloc[val_index]
y_train ,y_val = target.iloc[trn_index], target.iloc[val_index]
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_train)
train_acc = accuracy_score(y_train, y_pred)
print(train_acc)
train_acc_list.append(train_acc)
y_pred_val = model.predict(X_val)
val_acc = accuracy_score(y_val, y_pred_val)
print(val_acc)
val_acc_list.append(val_acc)
print('-'*10 + 'Result' +'-'*10)
print(f'Train_acc : {train_acc_list} , Ave : {np.mean(train_acc_list)}')
print(f'Valid_acc : {val_acc_list} , Ave : {np.mean(val_acc_list)}')
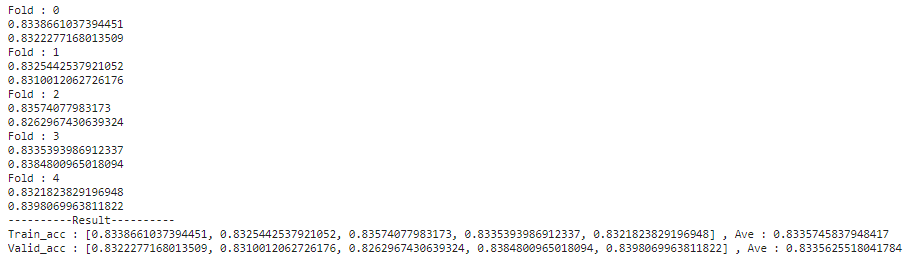
SVC
#SVCによる学習
from sklearn.svm import SVC
cv = KFold(n_splits=5, random_state=0, shuffle=True)
train_acc_list = []
val_acc_list = []
# fold毎に学習データのインデックスと評価データのインデックスが得られます
for i ,(trn_index, val_index) in enumerate(cv.split(train_df, target)):
print(f'Fold : {i}')
# データ全体(Xとy)を学習データと評価データに分割
X_train ,X_val = train_df.iloc[trn_index], train_df.iloc[val_index]
y_train ,y_val = target.iloc[trn_index], target.iloc[val_index]
model = SVC(random_state=0)
model.fit(X_train, y_train)
y_pred = model.predict(X_train)
train_acc = accuracy_score(y_train, y_pred)
print(train_acc)
train_acc_list.append(train_acc)
y_pred_val = model.predict(X_val)
val_acc = accuracy_score(y_val, y_pred_val)
print(val_acc)
val_acc_list.append(val_acc)
print('-'*10 + 'Result' +'-'*10)
print(f'Train_acc : {train_acc_list} , Ave : {np.mean(train_acc_list)}')
print(f'Valid_acc : {val_acc_list} , Ave : {np.mean(val_acc_list)}')
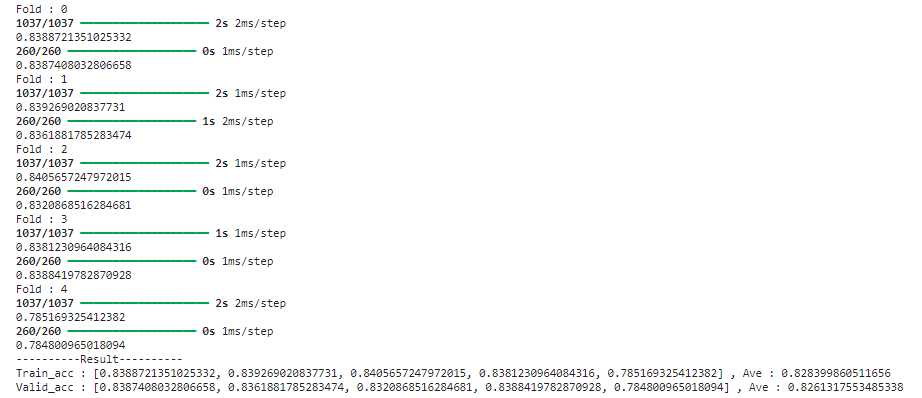
MLP
import tensorflow as tf
import random
import os
from tensorflow.keras.utils import to_categorical
# 乱数を固定
tf.random.set_seed(0)
np.random.seed(0)
random.seed(0)
os.environ["PYTHONHASHSEED"] = "0"
cv = KFold(n_splits=5, random_state=0, shuffle=True)
train_acc_list = []
val_acc_list = []
# fold毎に学習データのインデックスと評価データのインデックスが得られます
for i ,(trn_index, val_index) in enumerate(cv.split(train_df, target)):
print(f'Fold : {i}')
# データ全体(Xとy)を学習データと評価データに分割
X_train ,X_val = train_df.iloc[trn_index], train_df.iloc[val_index]
y_train ,y_val = target.iloc[trn_index], target.iloc[val_index]
# モデルを定義
model = tf.keras.models.Sequential([
tf.keras.layers.Input((X_train.shape[1],)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax')
])
# モデルをコンパイル
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(
X_train, to_categorical(y_train),
batch_size=256, epochs=100, verbose=False
)
y_pred = np.argmax(model.predict(X_train),axis=1)
train_acc = accuracy_score(y_train, y_pred)
print(train_acc)
train_acc_list.append(train_acc)
y_pred_val = np.argmax(model.predict(X_val),axis=1)
val_acc = accuracy_score(y_val, y_pred_val)
print(val_acc)
val_acc_list.append(val_acc)
print('-'*10 + 'Result' +'-'*10)
print(f'Train_acc : {train_acc_list} , Ave : {np.mean(train_acc_list)}')
print(f'Valid_acc : {val_acc_list} , Ave : {np.mean(val_acc_list)}')
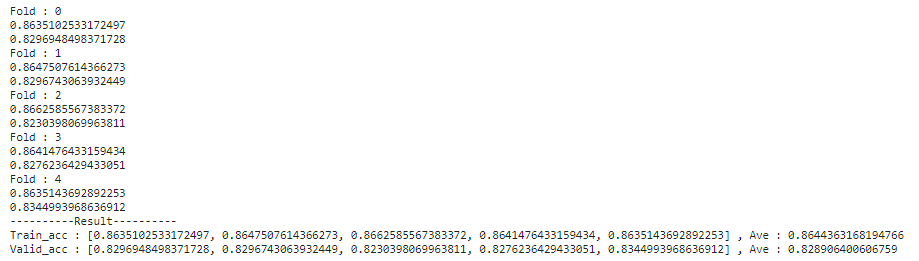
ランダムフォレスト
from sklearn.ensemble import RandomForestClassifier
cv = KFold(n_splits=5, random_state=0, shuffle=True)
train_acc_list = []
val_acc_list = []
# fold毎に学習データのインデックスと評価データのインデックスが得られます
for i ,(trn_index, val_index) in enumerate(cv.split(train_df, target)):
print(f'Fold : {i}')
# データ全体(Xとy)を学習データと評価データに分割
X_train ,X_val = train_df.iloc[trn_index], train_df.iloc[val_index]
y_train ,y_val = target.iloc[trn_index], target.iloc[val_index]
model = RandomForestClassifier(random_state=0)
model.fit(X_train, y_train)
y_pred = model.predict(X_train)
train_acc = accuracy_score(y_train, y_pred)
print(train_acc)
train_acc_list.append(train_acc)
y_pred_val = model.predict(X_val)
val_acc = accuracy_score(y_val, y_pred_val)
print(val_acc)
val_acc_list.append(val_acc)
print('-'*10 + 'Result' +'-'*10)
print(f'Train_acc : {train_acc_list} , Ave : {np.mean(train_acc_list)}')
print(f'Valid_acc : {val_acc_list} , Ave : {np.mean(val_acc_list)}')
LightGBM
#LightGBM
import lightgbm as lgb
cv = KFold(n_splits=3, random_state=0, shuffle=True)
train_acc_list = []
val_acc_list = []
# ハイパーパラメーターを定義
lgb_params = {
"objective":"binary",
"metric": "binary_error",
"force_row_wise" : True,
"seed" : 0,
}
# fold毎に学習データのインデックスと評価データのインデックスが得られます
for i ,(trn_index, val_index) in enumerate(cv.split(train_df, target)):
print(f'Fold : {i}')
# データ全体(Xとy)を学習データと評価データに分割
X_train ,X_val = train_df.iloc[trn_index], train_df.iloc[val_index]
y_train ,y_val = target.iloc[trn_index], target.iloc[val_index]
# LigthGBM用のデータセットを定義
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_val, y_val)
model = lgb.train(
params = lgb_params,
train_set = lgb_train,
valid_sets = [lgb_train, lgb_valid],
callbacks = [lgb.log_evaluation(period=100),lgb.early_stopping(10)]
)
y_pred = model.predict(X_train)
train_acc = accuracy_score(
# y_predは0〜1の確率になっています。
y_train, np.where(y_pred>=0.5, 1, 0)
)
print(train_acc)
train_acc_list.append(train_acc)
y_pred_val = model.predict(X_val)
val_acc = accuracy_score(
y_val, np.where(y_pred_val>=0.5, 1, 0)
)
print(val_acc)
val_acc_list.append(val_acc)
print('-'*10 + 'Result' +'-'*10)
print(f'Train_acc : {train_acc_list} , Ave : {np.mean(train_acc_list)}')
print(f'Valid_acc : {val_acc_list} , Ave : {np.mean(val_acc_list)}')
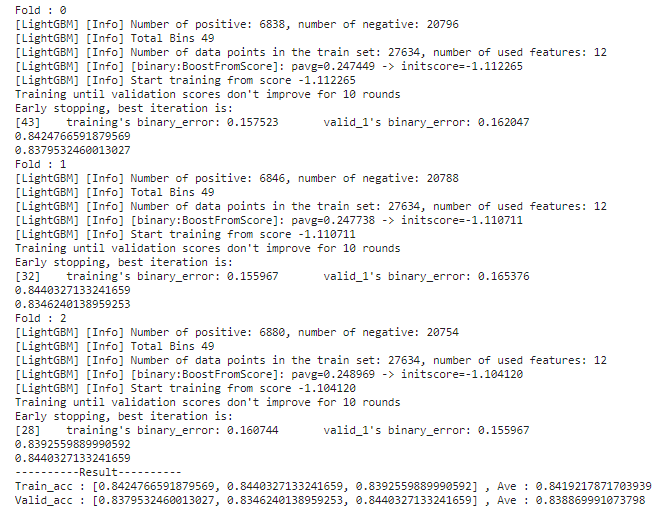
【モデル別の検証データに対する正解率】
ロジスティック回帰:0.8338038208768822
SVC:0.8335625518041784
MLP:0.8261317553485338
ランダムフォレスト:0.828906400606759
LightGBM:0.838869991073798
上記結果から最も正解率の高いLightBGMを採用しました。
パラメータ最適化
最後にLightGBMのハイパーパラメータの最適化を行いました。
今回はハイパーパラメータ探索ライブラリの「optuna」を使用しmax_depth,num_leaves,learning_rateの3つの引数に対する最適な値を求めます。
#パラメータ最適化
import optuna
def objective(trial):
# 今までと同様にクロスバリデーションでモデルを評価します
cv = KFold(n_splits=3, random_state=0, shuffle=True)
val_acc_list = []
# ハイパーパラメーターを定義
lgb_params = {
"objective":"binary",
"metric": "binary_error",
"force_row_wise" : True,
"seed" : 0,
'learning_rate': 0.1,
'min_data_in_leaf': 5,
"max_depth": trial.suggest_int('max_depth', 3, 20),
"num_leaves": trial.suggest_int('num_leaves', 21, 41),
"learning_rate": trial.suggest_uniform('learning_rate', 0.1, 0.2),
}
# fold毎に学習データのインデックスと評価データのインデックスが得られます
for i ,(trn_index, val_index) in enumerate(cv.split(train_df, target)):
print(f'Fold : {i}')
# データ全体(Xとy)を学習データと評価データに分割
X_train ,X_val = train_df.iloc[trn_index], train_df.iloc[val_index]
y_train ,y_val = target.iloc[trn_index], target.iloc[val_index]
# LigthGBM用のデータセットを定義
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_val, y_val)
model = lgb.train(
params = lgb_params,
train_set = lgb_train,
valid_sets = [lgb_train, lgb_valid],
callbacks = [lgb.log_evaluation(period=-1),lgb.early_stopping(10)]
)
y_pred = model.predict(X_train)
y_pred_val = model.predict(X_val)
val_acc = accuracy_score(
y_val, np.where(y_pred_val>=0.5, 1, 0)
)
val_acc_list.append(val_acc)
return np.mean(val_acc_list)
# 最適化タスクを定義
# 引数のdirectionには最適化する指標を最大化したいのか、最小化したいのかを指定
study = optuna.create_study(direction="maximize")
# 最適化を実行します。この時の探索の試行回数をn_trialsで指定
study.optimize(objective, n_trials=100)
# 最適なパラメータとその時の精度を表示
print("best_value", study.best_value)
print("best_params", study.best_params)
# 最適化の過程を表示 & 可視化
optuna_log_df = study.trials_dataframe(attrs=("number", "value", "params"))
display(optuna_log_df)
plt.scatter(optuna_log_df["params_max_depth"], optuna_log_df["value"])
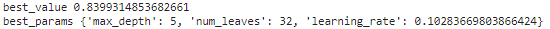
上記内容からこのモデルのパイパーパラメータは以下とすることで最終的に約84%の正解率を出すことができました。
max_depth=5
num_leaves=32
learning_rate=0.10283669803866424
まとめ
特徴量を作成する段階で量的データもカテゴライズしていたため、カテゴライズせずに流すなどデータ成形を試行錯誤することで精度が向上するかもしれないと感じました。トライ&エラーで引き続き精度向上を目指していきたいと思います。