本記事で紹介している内容は、DQN(ディープQネットワーク)を用いた日経平均トレードの技術的な解説およびシミュレーション事例であり、特定の投資行動や金融商品の購入・売却を勧誘するものではありません。
また、記載された運用成績や利回りは過去のバックテストまたはシミュレーション結果に基づいており、将来の成果を保証するものではありません。
投資には元本割れや損失が発生するリスクがあり、最終的な投資判断はご自身の責任でお願いいたします。
本記事の内容を参考にして生じたいかなる損失についても、一切の責任を負いかねます。
投資にあたっては、必ずご自身で十分な調査・ご判断のうえ、必要に応じて専門家等にご相談ください。
関連記事一覧
1. DQNでトレードの売買判断を行うAIの試作 〜データ準備編〜
2. DQNでトレードの売買判断を行うAIの試作 〜環境・トレーニング編〜
3. DQNでトレードの売買判断を行うAIの試作 〜性能測定編〜
4. DQNで株価のテクニカル分析を行うAIモデルの試作 〜アンサンブル編〜(本記事)
はじめに
これまでの記事では、DQNを用いた株価テクニカル分析AIの基礎から、データ準備、学習環境の設計、そして性能測定まで詳しく解説してきました。単体のDQNモデルでも優秀な成績を収めることができましたが、機械学習の世界では「アンサンブル」という手法を使って、さらなる性能向上を図ることができます。
「三人寄れば文殊の知恵」という言葉があるように、複数のAIが協力することで、単体では見逃してしまうパターンを捉えたり、判断の精度を高めたりできる可能性があります。今回は、複数のDQNモデルを組み合わせたアンサンブル学習について、実際のコード実装を中心に解説します。
また、今回アンサンブルとその基盤となるモデルの実行結果を視覚化するプログラムも作成しました。その結果も載せています。
成果物(最終的にこんなものができます)
パフォーマンス分析
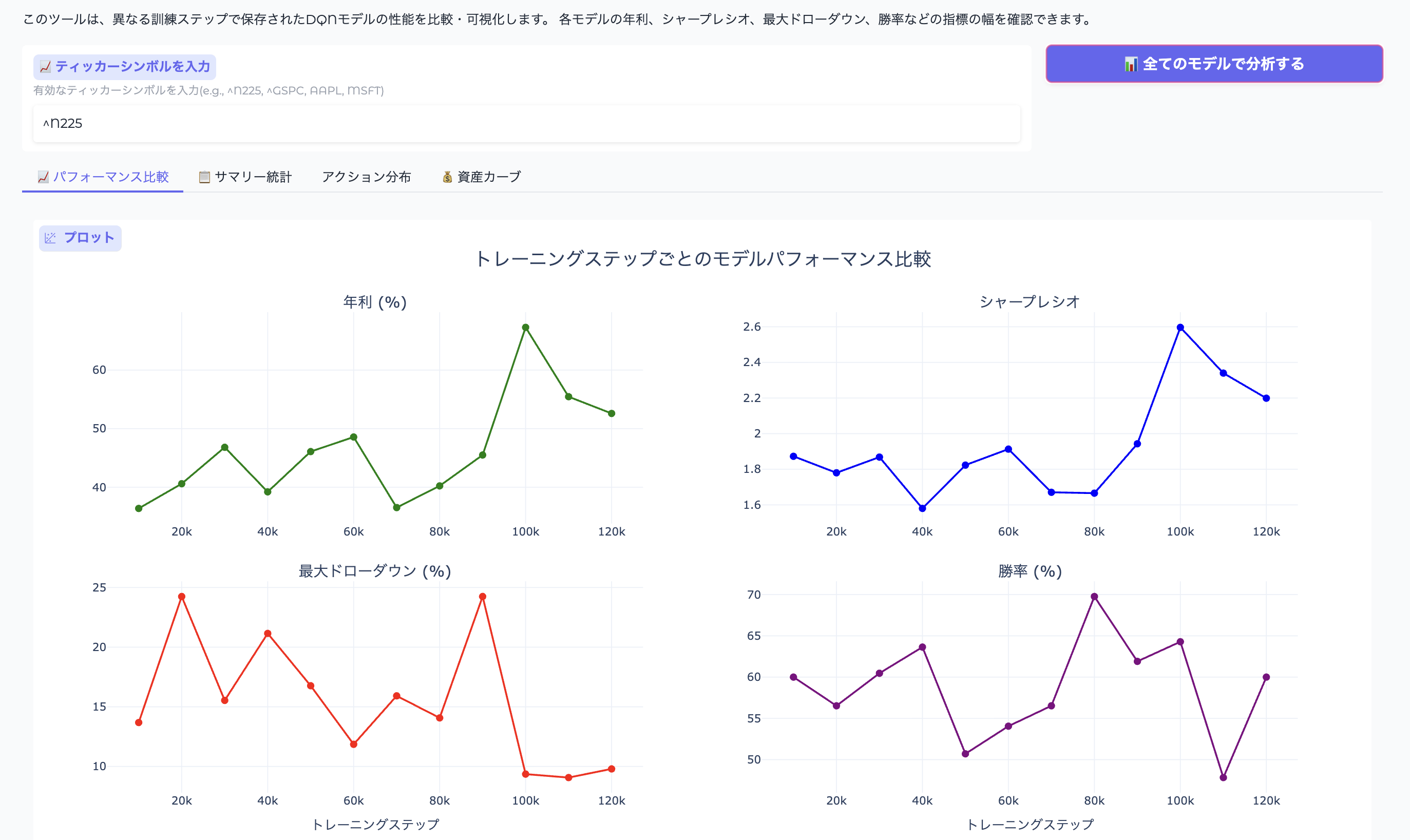
統計

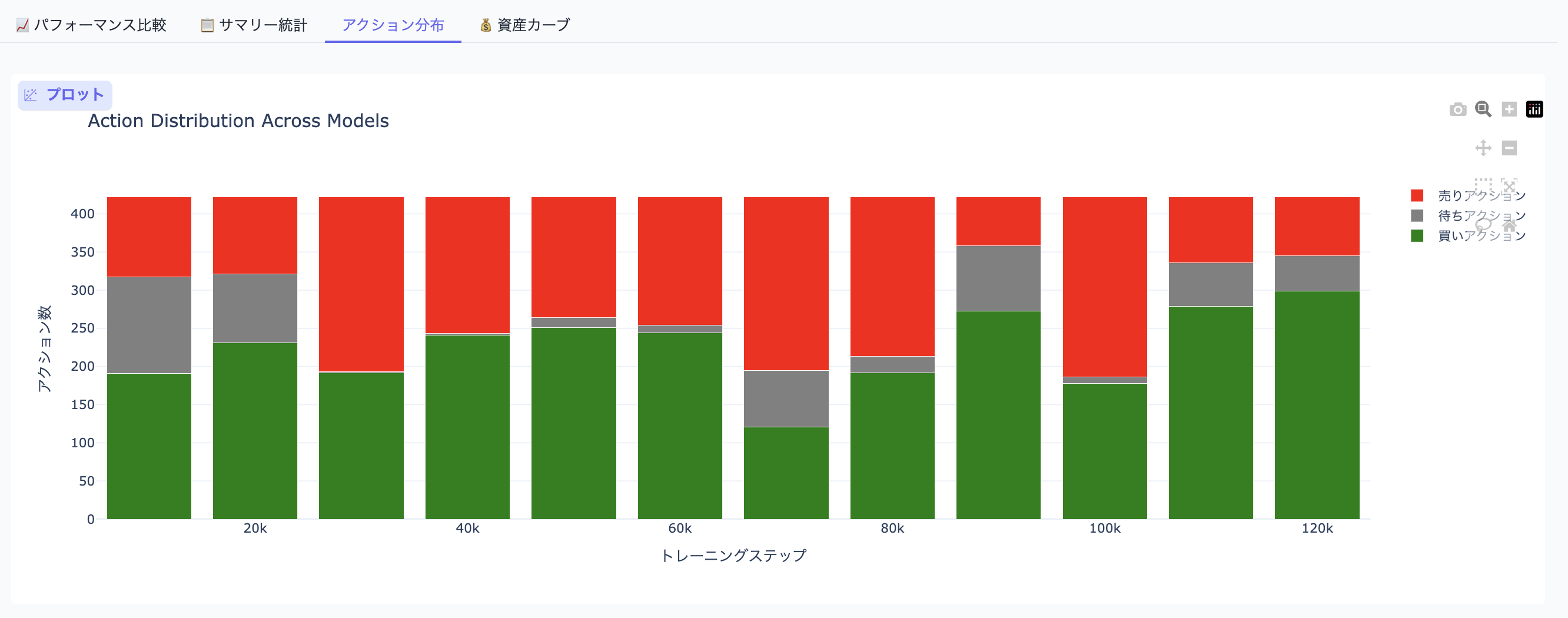
アクション分布
資産カーブ

黒い線がアンサンブルモデルの結果です。
gradioというライブラリを使って画面を作成しました。
アンサンブル学習とは?なぜ有効なのか?
アンサンブル学習は、複数の学習モデルを組み合わせて、単体のモデルよりも高い性能を目指す機械学習手法です。株式投資で例えるなら、「複数の専門家の意見を聞いてから投資判断をする」ようなものです。
DQNにおけるアンサンブルの有効性
1. 学習のランダム性
DQNの学習過程には探索によるランダム性があります。同じ設定でも、異なる学習経験により、わずかに異なる戦略を学習します。
2. ノイズに対する頑健性
株価データはノイズが多いため、単体のモデルは偶発的なパターンに惑わされる可能性があります。複数のモデルの判断を統合することで、ノイズを軽減できます。
実装:多数決による意思決定
今回の実装では、複数のDQNモデルの「多数決」によって最終的な投資判断を行います。visualize.pyの実装を詳しく見てみましょう。
全モデルの性能評価
まず、学習したモデル(1万〜12万ステップ)の性能を評価します。出てくる関数は前回までの記事に書いてあります。
def evaluate_all_models(ticker="^N225"):
"""全モデルの性能を評価して結果を返す"""
start = "2023-01-01"
end = "2025-08-23"
test_data = generate_env_data(start, end, ticker=ticker)
window_size = 130
test_env = NikkeiEnv(
test_data,
window_size=window_size,
transaction_cost=0.001,
risk_limit=0.5,
trade_penalty=0.00,
)
results = []
for i in range(10000, 120001, 10000):
model_path = f"nikkei_cp_1997-01-01_2024-01-01_{i}_steps.zip"
if not os.path.exists(model_path):
continue
model = load_model_safely(model_path, test_env)
obs = test_env.reset()
done = False
action_history = []
while not done:
action, _ = model.predict(obs, deterministic=True)
action_history.append(int(action))
obs, reward, done, info = test_env.step(action)
equity_curve = test_env.get_equity_curve()
sharpe = compute_sharpe_ratio(equity_curve, yearly_risk_free_rate=0.01)
metrics = calculate_performance_metrics(equity_curve, action_history)
# 各モデルの結果を保存
results.append({
"steps": i,
"annual_return": metrics["annual_return"],
"sharpe_ratio": sharpe,
"action_history": action_history, # 重要:アクション履歴を保存
# その他の性能指標...
})
return results
各モデルが実際にどのような判断をしたかを記録するため、action_historyを保存しているのが重要なポイントです。
アンサンブル結果の作成
保存された各モデルのアクション履歴を使って、多数決によるアンサンブルを実行します:
def create_ensemble_result(results, ticker="^N225"):
"""多数決によるアンサンブルの結果を作成"""
if not results:
return [], {}
# 各モデルのアクション履歴を収集
all_actions = {}
max_length = 0
for result in results:
steps = result["steps"]
action_history = result["action_history"]
all_actions[steps] = action_history
max_length = max(max_length, len(action_history))
# 各日での多数決を実行
ensemble_actions = []
for i in range(max_length):
votes = []
for steps, actions in all_actions.items():
if i < len(actions):
votes.append(actions[i])
if votes:
# 多数決(最も多い票のアクション)
vote_counts = Counter(votes)
ensemble_action = vote_counts.most_common(1)[0][0]
ensemble_actions.append(ensemble_action)
# アンサンブルのエクイティカーブを計算
ensemble_env = NikkeiEnv(test_data, window_size=130, transaction_cost=0.001)
obs = ensemble_env.reset()
for action in ensemble_actions:
if done:
break
obs, reward, done, info = ensemble_env.step(action)
equity_curve = ensemble_env.get_equity_curve()
# アンサンブルの性能指標を計算
sharpe = compute_sharpe_ratio(equity_curve, yearly_risk_free_rate=0.01)
metrics = calculate_performance_metrics(equity_curve, ensemble_actions)
return equity_curve, metrics
この実装の核心は以下の部分です:
- 投票の収集:各日において、全てのモデルがどの行動を選択したかを収集
-
多数決の実行:
Counterを使って最も多い票を獲得した行動を選択 - 結果の計算:アンサンブル行動に基づいて実際の取引をシミュレート
可視化システム
実装では、Gradioを使用してWebベースの可視化システムを構築しています:
def create_equity_curves_with_ensemble(ticker="^N225"):
"""全モデルのエクイティカーブとアンサンブルを表示"""
results = evaluate_all_models(ticker)
fig = go.Figure()
# 個別モデルのエクイティカーブ(薄い線)
for result in results:
steps = result["steps"]
equity_curve = result["equity_curve"]
fig.add_trace(go.Scatter(
x=list(range(len(equity_curve))),
y=clean_data_for_plot(equity_curve),
mode="lines",
name=f"Step {steps}",
line=dict(width=1.5),
opacity=0.6,
))
# アンサンブル(多数決)のエクイティカーブ(太い黒線)
ensemble_curve, ensemble_metrics = create_ensemble_result(results, ticker)
if ensemble_curve:
fig.add_trace(go.Scatter(
x=list(range(len(ensemble_curve))),
y=clean_data_for_plot(ensemble_curve),
mode="lines",
name="Ensemble (Majority Vote)",
line=dict(width=4, color="black"), # 太い黒線で強調
opacity=1.0,
))
return fig, ensemble_metrics
アンサンブルの性能分析
アンサンブルの効果を確認するため、以下の指標で個別モデルと比較します:
主要な性能指標
ensemble_metrics = {
"annual_return": metrics["annual_return"], # 年利
"sharpe_ratio": sharpe, # シャープレシオ
"max_drawdown": metrics["max_drawdown"], # 最大ドローダウン
"win_rate": metrics["win_rate"], # 勝率
"profit_factor": metrics["profit_factor"], # プロフィットファクター
}
期待される効果
理論的には、多数決によるアンサンブルは以下の改善をもたらします:
- 安定性の向上:個別モデルの極端な判断を平滑化
- ノイズの軽減:偶発的な判断ミスを多数決で修正
- 汎化性能の向上:異なる市場状況に対してより柔軟に対応
アクション分布の可視化
どのモデルがどの程度各アクション(買い・待ち・売り)を選択したかも可視化できます:
def create_action_distribution(ticker="^N225"):
"""アクション分布の可視化"""
results = evaluate_all_models(ticker)
df = pd.DataFrame(results)
fig = go.Figure()
fig.add_trace(go.Bar(
x=df["steps"],
y=df["long_actions"], # 買いアクション数
name="買いアクション",
marker_color="green",
))
fig.add_trace(go.Bar(
x=df["steps"],
y=df["flat_actions"], # 待ちアクション数
name="待ちアクション",
marker_color="gray",
))
fig.add_trace(go.Bar(
x=df["steps"],
y=df["short_actions"], # 売りアクション数
name="売りアクション",
marker_color="red",
))
fig.update_layout(barmode="stack")
return fig
まとめ:アンサンブルの実践的価値
今回は、DQNを用いた株価テクニカル分析AIにおけるアンサンブル学習の実装について解説しました。重要なポイントは:
アンサンブルの効果
- 安定性の向上:個別モデルのブレを平滑化
- リスク軽減:極端な判断の修正
- 汎化性能:未知の市場環境への対応力向上
アンサンブル学習は、「集合知」の力を活用して、単体モデルでは達成できない安定した性能を実現する手法です。今回の実装では、シンプルな多数決方式を採用しましたが、重み付け投票や条件付きアンサンブルなど、さらなる発展も可能です。
株式市場という不確実性の高い環境において、複数のAIの協調による判断は、個人投資家にとって有用なツールとなる可能性があります。ただし、過去のデータでの性能が将来も保証されるわけではないことは、常に念頭に置く必要があります。
コード全文
インストールするライブラリ
pip install stable-baselines3 yfinance gym shimmy pandas_datareader plotly
コード全文
import os
import gradio as gr
import pandas as pd
import numpy as np
import plotly.graph_objects as go
import plotly.express as px
from plotly.subplots import make_subplots
from stable_baselines3 import DQN
from main import NikkeiEnv
from data import generate_env_data
from calc_performance import compute_sharpe_ratio, calculate_performance_metrics
from collections import Counter
def clean_data_for_plot(data):
"""プロット用データからNaN、無限値、複素数を除去"""
if isinstance(data, (list, tuple)):
cleaned = []
for item in data:
if isinstance(item, (int, float, np.number)):
if np.isfinite(item) and np.isreal(item):
cleaned.append(float(np.real(item)))
else:
cleaned.append(0.0)
else:
cleaned.append(item)
return cleaned
elif isinstance(data, np.ndarray):
# 複素数を実数部に変換し、NaN/Infを0で置換
real_data = np.real(data)
return np.where(np.isfinite(real_data), real_data, 0.0).tolist()
return data
def load_model_safely(model_path, env):
try:
model = DQN.load(
model_path,
env=None,
device="cpu",
custom_objects={
"lr_schedule": None,
"exploration_schedule": None,
"batch_norm_stats": None,
"batch_norm_stats_target": None,
"replay_buffer": None,
},
)
model.policy.to("cpu")
model.policy.set_training_mode(False)
model.set_env(env)
return model
except Exception as e:
print(f"モデルロードエラー: {e}")
return DQN("MlpPolicy", env, verbose=0, device="cpu")
def evaluate_all_models(ticker="^N225"):
"""全モデルの性能を評価して結果を返す"""
start = "2023-01-01"
end = "2025-08-23"
test_data = generate_env_data(start, end, ticker=ticker)
window_size = 130
test_env = NikkeiEnv(
test_data,
window_size=window_size,
transaction_cost=0.001,
risk_limit=0.5,
trade_penalty=0.00,
)
results = []
for i in range(10000, 120001, 10000):
try:
print(f"Evaluating Step {i}...")
obs = test_env.reset()
done = False
action_history = []
model_path = f"nikkei_cp_1997-01-01_2024-01-01_{i}_steps.zip"
if not os.path.exists(model_path):
print(f"Model file not found: {model_path}")
continue
model = load_model_safely(model_path, test_env)
step_count = 0
max_steps = len(test_data) - window_size
while not done and step_count < max_steps:
try:
action, _ = model.predict(obs, deterministic=True)
action_history.append(int(action))
obs, reward, done, info = test_env.step(action)
step_count += 1
except Exception as e:
print(f"Step execution error: {e}")
break
equity_curve = test_env.get_equity_curve()
sharpe = compute_sharpe_ratio(equity_curve, yearly_risk_free_rate=0.01)
metrics = calculate_performance_metrics(equity_curve, action_history)
# 最終アクションの統計
action_counter = Counter(action_history)
result = {
"steps": i,
"annual_return": metrics["annual_return"],
"sharpe_ratio": sharpe,
"max_drawdown": metrics["max_drawdown"],
"win_rate": metrics["win_rate"],
"avg_win": metrics["avg_win"],
"avg_loss": metrics["avg_loss"],
"wl_ratio": metrics["wl_ratio"],
"expectancy": metrics["expectancy"],
"profit_factor": metrics["profit_factor"],
"total_trades": metrics["total_trades"],
"final_balance": equity_curve[-1],
"long_actions": action_counter.get(0, 0),
"flat_actions": action_counter.get(1, 0),
"short_actions": action_counter.get(2, 0),
"equity_curve": equity_curve,
"action_history": action_history, # アクション履歴を追加
}
results.append(result)
del model
except Exception as e:
print(f"Error evaluating model {i}: {e}")
continue
return results
def create_performance_comparison(ticker="^N225"):
"""モデル性能比較グラフを作成"""
results = evaluate_all_models(ticker)
if not results:
return "No model results available"
df = pd.DataFrame(results)
# 4つのメトリクスを表示するサブプロット
fig = make_subplots(
rows=2,
cols=2,
subplot_titles=(
"年利 (%)",
"シャープレシオ",
"最大ドローダウン (%)",
"勝率 (%)",
),
vertical_spacing=0.12,
)
# 年利
fig.add_trace(
go.Scatter(
x=df["steps"],
y=df["annual_return"],
mode="lines+markers",
name="年利",
line=dict(color="green", width=2),
marker=dict(size=8),
),
row=1,
col=1,
)
# シャープレシオ
fig.add_trace(
go.Scatter(
x=df["steps"],
y=df["sharpe_ratio"],
mode="lines+markers",
name="シャープレシオ",
line=dict(color="blue", width=2),
marker=dict(size=8),
),
row=1,
col=2,
)
# 最大ドローダウン
fig.add_trace(
go.Scatter(
x=df["steps"],
y=df["max_drawdown"],
mode="lines+markers",
name="最大ドローダウン",
line=dict(color="red", width=2),
marker=dict(size=8),
),
row=2,
col=1,
)
# 勝率
fig.add_trace(
go.Scatter(
x=df["steps"],
y=df["win_rate"],
mode="lines+markers",
name="勝率",
line=dict(color="purple", width=2),
marker=dict(size=8),
),
row=2,
col=2,
)
fig.update_layout(
title={
"text": "トレーニングステップごとのモデルパフォーマンス比較",
"x": 0.5,
"font": {"size": 20},
},
height=700,
showlegend=False,
template="plotly_white",
)
# X軸ラベル
fig.update_xaxes(title_text="トレーニングステップ", row=2, col=1)
fig.update_xaxes(title_text="トレーニングステップ", row=2, col=2)
return fig
def create_summary_stats(ticker="^N225"):
"""サマリー統計テーブルを作成"""
results = evaluate_all_models(ticker)
if not results:
return pd.DataFrame()
df = pd.DataFrame(results)
# 統計サマリーを計算
metrics = [
"annual_return",
"sharpe_ratio",
"max_drawdown",
"win_rate",
"profit_factor",
]
summary_data = []
for metric in metrics:
values = df[metric]
summary_data.append(
{
"メトリクス名": metric.replace("_", " ").title(),
"最小": f"{values.min():.2f}",
"最大": f"{values.max():.2f}",
"平均": f"{values.mean():.2f}",
"標準偏差": f"{values.std():.2f}",
"範囲": f"{values.max() - values.min():.2f}",
}
)
summary_df = pd.DataFrame(summary_data)
return summary_df
def create_action_distribution(ticker="^N225"):
"""アクション分布の可視化"""
results = evaluate_all_models(ticker)
if not results:
return "No model results available"
df = pd.DataFrame(results)
fig = go.Figure()
fig.add_trace(
go.Bar(
x=df["steps"],
y=df["long_actions"],
name="買いアクション",
marker_color="green",
)
)
fig.add_trace(
go.Bar(
x=df["steps"],
y=df["flat_actions"],
name="待ちアクション",
marker_color="gray",
)
)
fig.add_trace(
go.Bar(
x=df["steps"],
y=df["short_actions"],
name="売りアクション",
marker_color="red",
)
)
fig.update_layout(
title="Action Distribution Across Models",
xaxis_title="トレーニングステップ",
yaxis_title="アクション数",
barmode="stack",
template="plotly_white",
height=500,
)
return fig
def create_ensemble_result(results, ticker="^N225"):
"""多数決によるアンサンブルの結果を作成(エクイティカーブと性能指標)"""
if not results:
return [], {}
# 既存の結果からアクション履歴を取得(効率化)
all_actions = {}
max_length = 0
for result in results:
steps = result["steps"]
action_history = result["action_history"]
all_actions[steps] = action_history
max_length = max(max_length, len(action_history))
# 各ステップでの多数決を計算
ensemble_actions = []
for i in range(max_length):
votes = []
for steps, actions in all_actions.items():
if i < len(actions):
votes.append(actions[i])
if votes:
# 多数決(最も多い票のアクション)
vote_counts = Counter(votes)
ensemble_action = vote_counts.most_common(1)[0][0]
ensemble_actions.append(ensemble_action)
print(f"Ensemble actions length: {len(ensemble_actions)}")
# アンサンブルのエクイティカーブを計算
start = "2023-01-01"
end = "2025-08-23"
test_data = generate_env_data(start, end, ticker=ticker)
window_size = 130
ensemble_env = NikkeiEnv(
test_data,
window_size=window_size,
transaction_cost=0.001,
risk_limit=0.5,
trade_penalty=0.00,
)
obs = ensemble_env.reset()
done = False
step_count = 0
for action in ensemble_actions:
if done or step_count >= len(ensemble_actions):
break
try:
obs, reward, done, info = ensemble_env.step(action)
step_count += 1
except Exception:
break
equity_curve = ensemble_env.get_equity_curve()
# アンサンブルの性能指標を計算
sharpe = compute_sharpe_ratio(equity_curve, yearly_risk_free_rate=0.01)
metrics = calculate_performance_metrics(equity_curve, ensemble_actions)
action_counter = Counter(ensemble_actions)
ensemble_metrics = {
"annual_return": metrics["annual_return"],
"sharpe_ratio": sharpe,
"max_drawdown": metrics["max_drawdown"],
"win_rate": metrics["win_rate"],
"avg_win": metrics["avg_win"],
"avg_loss": metrics["avg_loss"],
"wl_ratio": metrics["wl_ratio"],
"expectancy": metrics["expectancy"],
"profit_factor": metrics["profit_factor"],
"total_trades": metrics["total_trades"],
"final_balance": equity_curve[-1],
"long_actions": action_counter.get(0, 0),
"flat_actions": action_counter.get(1, 0),
"short_actions": action_counter.get(2, 0),
}
return equity_curve, ensemble_metrics
def create_equity_curves_with_ensemble(ticker="^N225"):
"""全モデルのエクイティカーブとアンサンブルを表示し、アンサンブル性能も返す"""
results = evaluate_all_models(ticker)
if not results:
return "No model results available", ""
fig = go.Figure()
# 個別モデルのエクイティカーブ
for result in results:
steps = result["steps"]
equity_curve = result["equity_curve"]
fig.add_trace(
go.Scatter(
x=list(range(len(equity_curve))),
y=clean_data_for_plot(equity_curve),
mode="lines",
name=f"Step {steps}",
line=dict(width=1.5),
opacity=0.6,
)
)
# アンサンブル(多数決)のエクイティカーブと性能指標
ensemble_curve, ensemble_metrics = create_ensemble_result(results, ticker)
if ensemble_curve:
fig.add_trace(
go.Scatter(
x=list(range(len(ensemble_curve))),
y=clean_data_for_plot(ensemble_curve),
mode="lines",
name="Ensemble (Majority Vote)",
line=dict(width=4, color="black"),
opacity=1.0,
)
)
fig.update_layout(
title="資産カーブの比較 + アンサンブル(多数決)",
xaxis_title="日数",
yaxis_title="資産 (円)",
template="plotly_white",
height=600,
hovermode="x unified",
legend=dict(yanchor="top", y=0.99, xanchor="left", x=0.01),
)
# アンサンブルの性能指標をテキスト形式で表示
ensemble_text = ""
if ensemble_metrics:
ensemble_text = f"""
## 🎯 アンサンブル(多数決)性能指標
- **年利**: {ensemble_metrics['annual_return']:.2f}%
- **シャープレシオ**: {ensemble_metrics['sharpe_ratio']:.3f}
- **最大ドローダウン**: {ensemble_metrics['max_drawdown']:.2f}%
- **勝率**: {ensemble_metrics['win_rate']:.2f}%
- **平均勝ち**: {ensemble_metrics['avg_win']:.4f}%
- **平均負け**: {ensemble_metrics['avg_loss']:.4f}%
- **W/Lレシオ**: {ensemble_metrics['wl_ratio']:.2f}
- **期待値**: {ensemble_metrics['expectancy']:.4f}%
- **プロフィットファクター**: {ensemble_metrics['profit_factor']:.2f}
- **総取引数**: {ensemble_metrics['total_trades']}
- **最終残高**: ¥{ensemble_metrics['final_balance']:,.0f}
### アクション分布
- **ロング**: {ensemble_metrics['long_actions']} 回
- **フラット**: {ensemble_metrics['flat_actions']} 回
- **ショート**: {ensemble_metrics['short_actions']} 回
"""
return fig, ensemble_text
# Gradioインターフェース
with gr.Blocks(
title="DQN Model Performance Visualizer", theme=gr.themes.Soft()
) as demo:
gr.Markdown(
"""
# 🚀 DQN Trading Model Performance Analyzer
このツールは、異なる訓練ステップで保存されたDQNモデルの性能を比較・可視化します。
各モデルの年利、シャープレシオ、最大ドローダウン、勝率などの指標の幅を確認できます。
"""
)
with gr.Row():
with gr.Column(scale=3):
ticker_input = gr.Textbox(
value="^N225",
label="📈 ティッカーシンボルを入力",
info="有効なティッカーシンボルを入力(e.g., ^N225, ^GSPC, AAPL, MSFT)",
placeholder="^N225",
)
with gr.Column(scale=1):
analyze_btn = gr.Button(
"📊 全てのモデルで分析する", variant="primary", size="lg"
)
with gr.Tab("📈 パフォーマンス比較"):
performance_plot = gr.Plot()
with gr.Tab("📋 サマリー統計"):
summary_table = gr.DataFrame()
with gr.Tab("アクション分布"):
action_plot = gr.Plot()
with gr.Tab("💰 資産カーブ"):
with gr.Row():
with gr.Column(scale=2):
equity_plot = gr.Plot()
with gr.Column(scale=1):
ensemble_metrics = gr.Markdown()
# ボタンクリック時の動作
analyze_btn.click(
fn=lambda ticker: [
create_performance_comparison(ticker),
create_summary_stats(ticker),
create_action_distribution(ticker),
*create_equity_curves_with_ensemble(
ticker
), # グラフとメトリクスの両方を返す
],
inputs=[ticker_input],
outputs=[
performance_plot,
summary_table,
action_plot,
equity_plot,
ensemble_metrics,
],
)
gr.Markdown(
"""
### 📖 使い方
1. ティッカーシンボルを入力(任意の銘柄が可能)
2. **全てのモデルで分析する**ボタンをクリックして全モデルを評価
3. 各タブで異なる観点からの分析結果を確認
4. **パフォーマンス比較**: 主要指標の推移
5. **サマリー統計**: 指標の統計サマリー
6. **アクション分布**: アクション選択の分布
7. **資産曲線**: 資産曲線の比較 + **アンサンブル(多数決)結果**
### 📈 ティッカーシンボル例
**指数:**
- **^N225**: 日経225(日本) | **^GSPC**: S&P 500(米国) | **^IXIC**: NASDAQ(米国)
- **^DJI**: ダウジョーンズ(米国) | **^RUT**: ラッセル2000(米国) | **^FTSE**: FTSE100(英国)
**個別株:**
- **AAPL**: Apple | **MSFT**: Microsoft | **GOOGL**: Google | **AMZN**: Amazon
- **7203.T**: トヨタ | **6758.T**: ソニー | **9984.T**: ソフトバンク
### 🎯 アンサンブル機能
- 全モデルの各ステップでのアクションを多数決で決定
- 黒い太線で「Ensemble (Majority Vote)」として表示
- 個別モデルの性能のばらつきを平滑化した安定的な戦略
### 📊 指標説明
- **Annual Return**: 年間収益率 (%)
- **Sharpe Ratio**: シャープレシオ (リスク調整済みリターン)
- **Max Drawdown**: 最大ドローダウン (%)
- **Win Rate**: 勝率 (%)
- **Profit Factor**: プロフィットファクター (総利益/総損失)
"""
)
if __name__ == "__main__":
demo.launch(server_name="0.0.0.0", server_port=7860, share=False, show_error=True)
コード全文