はじめに
WebスクレイピングでSeleniumを使っており、かれこれ1年以上経ちます。
いつも「あれ??これどうやって書くんだっけ??」となり、毎回調べているのうんざりし始めたので、本記事にまとていくことにしました。
ChromeOptions
必要なオプションが設定されていないと、稀に下記のようなタイムアウトエラーが発生します、
Timed out receiving message from renderer: 600.000
この件について、Stack Overflowの回答では、以下のオプション設定を行えば問題ないそうです。ちなみに「役に立たない増え続ける引数オプション」と呼ばれています。(まさにその通り・・・)
options = webdriver.ChromeOptions()
options.add_argument("start-maximized")
options.add_argument("enable-automation")
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-infobars")
options.add_argument('--disable-extensions')
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-browser-side-navigation")
options.add_argument("--disable-gpu")
options.add_argument('--ignore-certificate-errors')
options.add_argument('--ignore-ssl-errors')
prefs = {"profile.default_content_setting_values.notifications" : 2}
options.add_experimental_option("prefs",prefs)
driver = new ChromeDriver(options);
要素探索
親要素
driver.find_element_by_xpath('//div[@id="cnfm_btn"]').find_element_by_xpath('..')
子要素
driver.find_element_by_xpath('//div[@id="cnfm_btn"]/div')
子要素(取得要素を基に)
anchors = driver.find_elements_by_xpath("//*[(@id='movie_link')]")
for anchor in anchors:
anchor.find_element_by_xpath(".//img") #[.]を付けることで親要素の配下が対象となる
隣の要素(前)
driver.find_element_by_xpath("//p[@id='one']/preceding-sibling::p")
隣の要素(後)
driver.find_element_by_xpath("//p[@id='one']/following-sibling::p")
クラス名で探す(単数)
driver.find_element_by_class_name('content')
クラス名で探す(複数)
driver.find_elements_by_class_name('content')
テキストコンテントで探す
React等で作成されたサイトはID等のキーを用いて要素を探索する事が難しくなっています。
例えば、Twitterはログインボタンにid="login"と要素特定するためのキーが無いので探索が少し難しいです。。
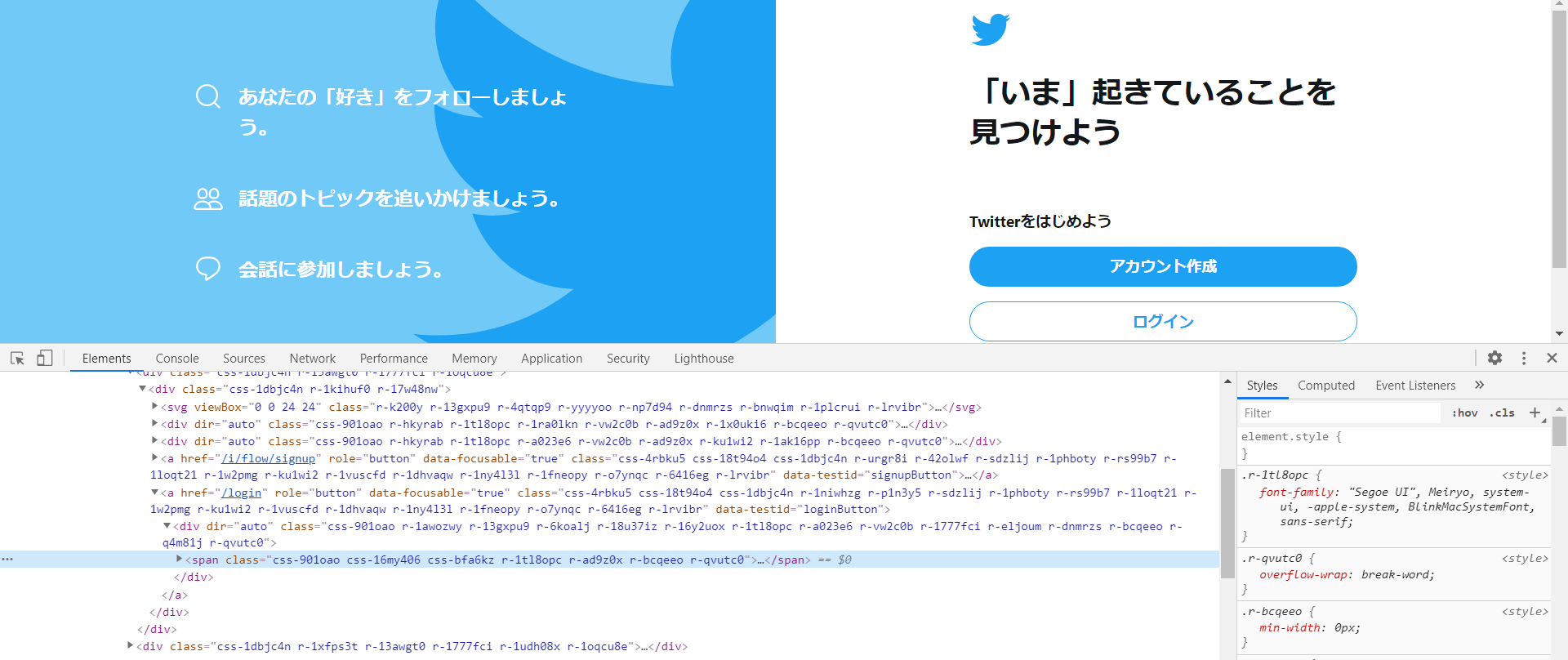
そこで、一つの打開策としてテキストコンテントで探す方法があります。(Stack Overflowの回答)
・部分一致
driver.find_elements_by_xpath("//*[contains(text(), 'My Button')]")
・完全一致
driver.find_elements_by_xpath("//*[text()='My Button']")
ID、クラス名(部分一致)で探す
こちらも同じくReact等で作成されたサイトはID、Class等のキーを用いて要素を探索する事が難しくなっています。ID、クラス名の部分一致で探す方法があります。
driver.find_element_by_xpath("//div[contains(@class, 'playerStateIcon')]")
要素操作
削除
JavaScriptを実行して要素を削除することが出来ます。
#クラス名で特定して削除する場合
element = driver.find_element_by_class_name('classname')
driver.execute_script("""
var element = arguments[0];
element.parentNode.removeChild(element);
""", element)
ダウンロード
urllibを用いファイルダウンロードを行います。
import urllib
data = urllib.request.urlopen("https://sample.com/sample.png").read()
with open(f"sample.png", mode="wb") as f:
f.write(data)
画面操作
スクロール
JavaScriptを実行してスクロールが出来ます。
footer = driver.find_element_by_xpath("//*[(@id='footer')]") #画面下部にある要素を取得する
driver.execute_script("arguments[0].scrollIntoView();",footer)
明示的な待機処理
WebDriverWait.untilメソッドで、任意のHTMLの要素が特定の状態になるまで待つ明示的な待機時間を設定することができます。詳細はこちら。
クリック可能か判定
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "cnfm_btn")))
選択可能か判定
WebDriverWait(driver, 10).until(EC.element_located_to_be_selected((By.ID, "cnfm_btn")))