こちらは【Sansan アドベントカレンダー 2018】の2日目の記事になります。
前書き
師走となり、読者のみなさまは忙しい時期かと思います。例に漏れず私も忙しい毎日を送っているのですが、日頃のアウトプットが足りないと感じたため、思い切ってアドベントカレンダーに登録しました。本記事のテーマは、SimStringのC++実装とPython実装の速度の違いの検証となります。おそらく、この段階でもC++実装の方がPython実装よりも速いことが予想されますが、それがどの程度のものか、何に依存してより高速に動作するのかなども今回のテーマの範囲とします。
SimStringとは
SimStringとは、Naoaki Okazaki's websiteで公開されている「高速かつシンプルな類似文字列検索ライブラリ」です。予め作成しておいた文字列データベースの中から、入力した文字列との類似度が特定の閾値以上となる文字列を全て抽出することができます。Naoaki Okazaki's websiteのオリジナル実装では、類似度関数として、コサイン係数、ジャッカード係数、ダイス係数、オーバーラップ係数が利用可能です。また、SimStringは高速なだけでなく100%正確な検索を保証している特徴もあります。
ちなみにNaoaki Okazaki's websiteのオリジナル実装をLinux上にビルドする際に、うまくいかない場合には、【SimStringをLinuxで動かす際の注意点】を見てみると良いかと思います。実際に私もLinux上でのビルドがうまくいかなかったときに、この記事を参考にした結果ビルドすることができました。
今回の問題設定
さて、この記事では、オリジナルのC++実装とPython実装との間の検索速度の違いを明らかにすることが目的となります。実験はPython3.6上で行ないます。また、オリジナルのC++実装をPython上で利用するための実装としてはsimstring-python-packageを利用し、Python実装のSimStringとしてはsimstring-pure 1.0.0 を利用します。これら以外にもPython上で動かすことができる実装があるかもしれませんが、今回の調査対象はこの二つに絞ります。
実験をする上での注意点として、これらはいずれもimport simstringで利用することからもわかるように、simstringという同じ名前空間を占有します。したがって、実験に際しては、各ライブラリを利用する環境をDockerで構築しました。
実験環境
実験を行った環境は以下の通りです。最小限のライブラリのみを導入した環境をDocker上に作成しました。
- プロセッサ: 3.5GHz Intel Core i7
- メモリ: 16GB 2133 MHz LPDDR3
- Docker: version 18.06.1-ce
共通設定
SimStringに持たせるデータベースの元となる文字列はipadicの単語のうち名詞のみを抽出したものから、各実験設定に合う条件のものを利用しました。なお、このとき文字化けなどの問題は、nkfを利用して対処しました。また、クエリとなる文字列はこの抽出した単語群からランダムに10万件サンプリングしたものを全ての実験設定で利用しました。この10万件のデータの平均文字列長は3.64756でした。クエリ群の各文字列長ごとのクエリの分布は下記の通りです。
| 文字列長 | クエリ数 | 文字列長 | クエリ数 | 文字列長 | クエリ数 |
|---|---|---|---|---|---|
| 1 | 1008 | 11 | 176 | 21 | 2 |
| 2 | 26208 | 12 | 101 | 22 | 1 |
| 3 | 26541 | 13 | 59 | 23 | 0 |
| 4 | 20615 | 14 | 32 | 24 | 0 |
| 5 | 14129 | 15 | 38 | 25 | 1 |
| 6 | 6960 | 16 | 16 | - | - |
| 7 | 2433 | 17 | 8 | - | - |
| 8 | 980 | 18 | 7 | - | - |
| 9 | 433 | 19 | 5 | - | - |
| 10 | 255 | 20 | 2 | - | - |
実験設定1
データベースに保持する文字列数を増やしたときに、それぞれの検索速度がどのように変化するかを比較します。このとき、データベース内に保持されている各文字列の長さは全て5とし、閾値は0.7としました。
実験設定2
データベースに保持する文字列数を10000件で固定して、データベース内の各文字列の長さを1から6まで長くしたときに、検索速度がどのように変化するかを比較します。このとき、閾値は0.7と固定しました。
問題設定3
検索対象となる文字列の長さを5として、データベースに保持する文字列を10000件としたときに、閾値を0.6から0.9まで0.1刻みで大きくしたときに、検索速度がどのように変化するかを比較します。
準備
C++実装とPython実装それぞれのインストール方法は下記の通りです。いずれもpipで一発で入ります。
C++実装オリジナル版のSimStringのインストール方法
pip install git+git://github.com/vitalco/simstring-python-package#egg=simstring
この実装におけるSimStringの操作方法については、simstring-python-packageのsample.pyが参考になります。
Python実装版のSimStringのインストール方法
RUN pip install simstring-pure
この実装におけるSimStringの操作方法については、simstring-pure・PyPIが参考になります。
実験結果
実験結果を本章で示します。ただし、$wlength$はDB内の各文字列長を、$threshold$は閾値を、そして、$dbsize$はDB内に保持する総文字列数を表すことにします。
実験1の結果
$wlength=5$, $threshold=0.7$, $dbsize \in [10, 100, 1000, 10000]$の時の結果は下記の通りです。
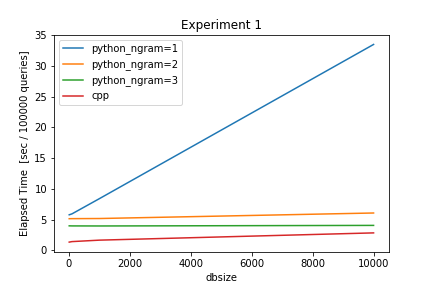
| Method \ dbsize | 10 | 100 | 1000 | 10000 |
|---|---|---|---|---|
| python ngram=1 | 5.7755 | 5.9257 | 8.4002 | 33.4859 |
| python ngram=2 | 5.1389 | 5.1481 | 5.169 | 6.0677 |
| python ngram=3 | 3.9784 | 3.9667 | 3.9567 | 4.0500 |
| c++ | 1.3308 | 1.414 | 1.6507 | 2.832 |
グラフから、$dbsize$に対して線形に計算時間が伸びていることが見て取れます。DB内の要素を全て見に行くことになるため、この結果は自然な結果と言えそうです。また、python実装の方はngramをいくつに設定するかによって、計算時間に大きな差が生まれていることがわかると同時に、やはり、C++実装がPython実装より高速に動作していることもわかります。
実験2の結果
$wlength\in[1,2,3,4,5,6]$, $threshold=0.7$, $dbsize=10000$の時の結果は下記の通りです。
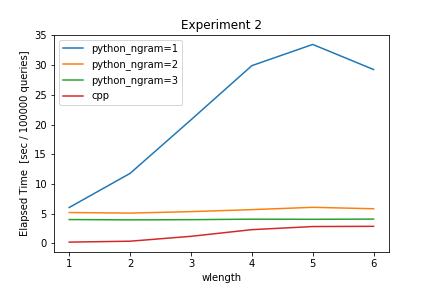
| Method \ wlength | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| python ngram=1 | 6.0381 | 11.7842 | 20.7922 | 29.9160 | 33.4859 | 29.2668 |
| python ngram=2 | 5.1914 | 5.0954 | 5.3429 | 5.6804 | 6.0677 | 5.8280 |
| python ngram=3 | 4.0084 | 3.9546 | 3.9919 | 4.0704 | 4.0500 | 4.0874 |
| c++ | 0.2109 | 0.3644 | 1.1869 | 2.3075 | 2.8316 | 2.8697 |
グラフから、$wlength$が大きくなると、変化の度合いの差こそあれ概ね計算時間が伸びていることがわかります。しかし、python ngram=1とpython ngram=2の結果からは、必ずしも$wlength$が大きいほど計算時間が増えるわけではないことがわかります。これは、あまり直感通りではない気がするため、実際に利用するときに注意する必要がありそうです。また、こちらの結果からも、C++実装がPython実装より高速に動作していることがわかります。
実験3の結果
$wlength=5$, $threshold \in [0.6, 0.7, 0.8, 0.9]$, $dbsize=10000$の時の結果は下記の通りです。
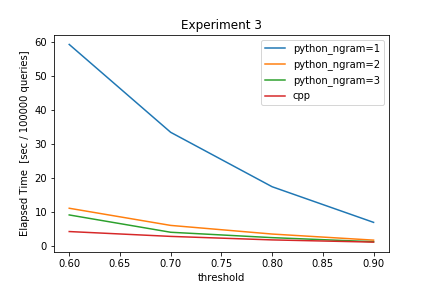
| Method \ threshold | 0.6 | 0.7 | 0.8 | 0.9 |
|---|---|---|---|---|
| python ngram=1 | 59.3648 | 33.4859 | 17.4547 | 6.9612 |
| python ngram=2 | 11.1217 | 6.0677 | 3.5238 | 1.7295 |
| python ngram=3 | 9.1495 | 4.0500 | 2.4658 | 1.2616 |
| c++ | 4.2591 | 2.8316 | 1.7979 | 1.1462 |
グラフから、$threshold$に対して、急激に計算時間が短くなっていることがわかります。$threshold$を大きくすれば、それだけ検索に引っかかる許容範囲が小さくなることから、この結果は当然と言えば当然です。また、この結果からは$threshold$をかなり厳しくすれば、C++実装とPython実装との間の速度の差が小さくなっていることがわかります。
まとめ
今回C++実装のSimStringとPython実装のSimStringを対象に、様々な場面での計算速度について調べました。調べてわかったことは、
- (C++実装/Python実装問わず、) $dbsize$ に対しては、線形に計算時間が伸びること
- (C++実装/Python実装問わず、) $threshold$ に対しては、急激に計算時間が短縮されること
- 場合によっては、$wlength$の長さが長いほど計算時間が短くなることがあること
- 【今回のテーマ】 全てを通してC++実装の方がPython実装より高速であること。また、差が大きい場合で数10倍程度速く、多くの場合約2倍程度は速く動作すること
の4つです。
今回の実験では、Python実装のSimStringの方が速度が遅いという結果になりましたが、こちらの実装はDBをファイルに一度保存する必要がないため、気軽に色々な実験ができるという利点があります。また、C++実装のSimStringは実験から高速であることがわかったため、膨大な数の利用をするときについてはこちらを使った方が良さそうです。
最後に
さて、アドベントカレンダーの時期というタイミングを逃すことなく、疑問を晴らすことができて満足しました。これからも、このように疑問に思ったことは思い切って、アウトプットしていければと思います。