
参考:Finance BI, Power BI: Basket Analysis, November 26, 2019
バスケット分析とは
- データマイニングの代表的な方法
- 購買データの分析により、一緒に購入されやすい商品を明らかにすること
- アソシエーション分析の手法の1つ
4つの指標

支持度(Support)
どれだけ一緒に買われているか
= \frac{同時購入者数}{購入者全体数}
信頼度(Confidence)
商品Xを買う時に商品Yも一緒に買う割合
= \frac{同時購入者数}{商品A購入者数}
期待信頼度(Expected Confidence)
顧客全員のうち、商品Yを購入する割合
=\frac{商品Y購入者}{購入者全体数}
リフト値(Lift)
リフト値が大きいほど、商品Xの購買が商品Yの購買を”持ち上げて”いる。小さい場合は、関連性が低い。
=\frac{商品Xの信頼度}{商品Yの期待信頼度}\\
=\frac{\frac{同時購入者数}{商品A購入者数}}{\frac{商品B購入者数}{購入者数全体}}
元データの整形
元のデータは、レシートごとに1行になっており、商品名が並んでいます。これを集計に使えるよう整形していきます。

まず、列の追加でインデックス列を追加して、レシート番号とします。
作成した列を選択し、その他の列のピボット解除を行います。
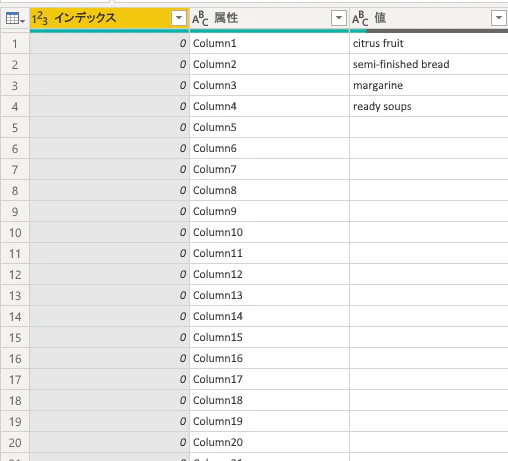
「属性」列の削除、「値」列の空の行の削除、列名の変更を行います。
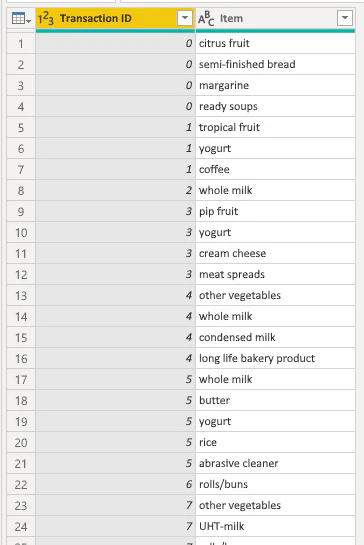
バスケット分析テーブルの作成
元のgroceriesというテーブルを使って、Basket analysisというテーブルを作成していきます。
組み合わせの作成
最初に、商品の組み合わせ表を作成します。
新しいテーブル
Basket analysis =
// Itemのすべての組み合わせを作成
FILTER(
CROSSJOIN(
VALUES(
'groceries'[Item]
),
SELECTCOLUMNS(
VALUES(
'groceries'[Item]
),
"Item2",
'groceries'[Item]
)
),
[Item]>[Item2] // 重複の削除
)
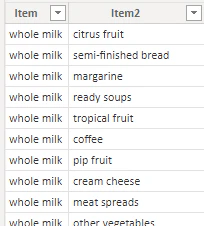
組み合わせ名称の作成
組み合わせを表示する項目を作成します。
支持度(Support)の作成
Support
Support basket = // 支持度の計算
var item1='Basket analysis'[Item] // 列名はテーブル名をつけましょう
var item2='Basket analysis'[Item2]
var transactionsWithItem1 = // Item1のTransaction ID表
SELECTCOLUMNS(
FILTER(
'groceries',
'groceries'[Item]=item1
),
"transactionID",
'groceries'[Transaction ID]
)
var transactionsWithItem2 = // Item2のTransaction ID表
SELECTCOLUMNS(
FILTER(
'groceries',
'groceries'[Item]=item2
),
"transactionID",
'groceries'[Transaction ID]
)
var transactionsWithBothItems = // 2つのテーブルの積
INTERSECT(
transactionsWithItem1,
transactionsWithItem2
)
RETURN
COUNTROWS(transactionsWithBothItems) // Item1とItem2の両方が含まれるレシート数
/
DISTINCTCOUNT(groceries[Transaction ID]) // すべてのレシートの数
信頼度(Confidence)の作成
Confidence1
Confidence Item1 -> basket = // Item1の信頼度
var item1='Basket analysis'[Item]
var item2='Basket analysis'[Item2]
var transactionsWithItem1 = // Item1のTransaction ID表
SELECTCOLUMNS(
FILTER(
'groceries',
'groceries'[Item]=item1
),
"transactionID",
'groceries'[Transaction ID]
)
var transactionsWithItem2 = // Item2のTransaction ID表
SELECTCOLUMNS(
FILTER(
'groceries',
'groceries'[Item]=item2
),
"transactionID",
'groceries'[Transaction ID]
)
var transactionsWithBothItems = // 2つのテーブルの積
INTERSECT(
transactionsWithItem1,
transactionsWithItem2
)
RETURN
COUNTROWS(transactionsWithBothItems) // Item1とItem2の両方が含まれるレシート数
/
COUNTROWS(transactionsWithItem1) // item1のレシートの数
Confidence2
Confidence Item 2 -> Basket = // Item2の信頼度
var item1=[Item]
var item2=[Item2]
var transactionsWithItem1 = // Item1のTransaction ID表
SELECTCOLUMNS(
FILTER(
'groceries',
'groceries'[Item]=item1
),
"transactionID",
'groceries'[Transaction ID]
)
var transactionsWithItem2 = // Item2のTransaction ID表
SELECTCOLUMNS(
FILTER(
'groceries',
'groceries'[Item]=item2
),
"transactionID",
'groceries'[Transaction ID]
)
var transactionsWithBothItems = // 2つのテーブルの積
INTERSECT(
transactionsWithItem1,
transactionsWithItem2
)
RETURN
COUNTROWS(transactionsWithBothItems) // Item1とItem2の両方が含まれるレシート数
/
COUNTROWS(transactionsWithItem2) // item2のレシートの数
リフト値(Lift)の作成
lift
Lift = // リフト値
var item1='Basket analysis'[Item]
var item2='Basket analysis'[Item2]
var transactionsWithItem2 = // Item2のTransaction ID表
SELECTCOLUMNS(
FILTER(
'groceries',
'groceries'[Item]=item2
),
"transactionID",
'groceries'[Transaction ID]
)
RETURN
'Basket analysis'[Confidence Item1 -> basket] // Item1の信頼度
/
(
COUNTROWS(transactionsWithItem2) // Item2のレシート数
/
DISTINCTCOUNT(groceries[Transaction ID]) // 全レシート数
)
ビジュアルの作成
支持度とリフト値を使って、散布図を作成します。
そのままだと、数が多いので、支持度が0.6%以上、リフト値が2以上でフィルターをかけます。クラスターの自動検索を行うと、以下のようになりました。

根菜に注目してみました。
