※この記事は2023年4月5日に書かれています。

Data Wrangler は、VS Code と VS Code Jupyter で CSV や Parquet データのエラー、不整合、欠落を修正するクリーニングのプロセスを簡素化することができます。対話型UIで作業ができるので、作業に集中することができ、また、Pandas ライブラリを使用した Python のコードが作成されるので、保守性も高くなります。
インストールから操作の手順をJeffrey MewのYoutube動画「Data Wrangler Walkthrough」を参考に作成しました。1
1. インストールと設定
- Visual Studio Code - Insiders のインストール2
- Python のインストール (バージョン3.7以上)3
- Visual Studio Code マーケットプレイスから Data Wrangler をインストール4
Data Wranglerは、現時点(2023年4月5日)でプレビューです。通常の Visual Studio Code ではなく、Visual Studio Code - Insidersでないと利用できません。
また、Pythonもインストールします。現時点の最新バージョンは3.11.2です。既にインストール済みの場合は、バージョンを確認してください。3.7以降のバージョンが必要です。
Visual Studio Code - Insiders を立ち上げ、Visual Studio Marketplace から Data Wrangler 拡張機能をインストールします。最初に Data Wrangler を起動すると、各種の拡張機能とPandasのインストールが行われます。
拡張機能等のインストールが終わると、Pythonカーネルに接続できないとメッセージが表示されます。Visual Studio Code - Insiders を終了し、再度立ち上げなおしてください。
Pythonへの接続は、ローカルのPythonインタプリタを使用するか、Jupyter Lab APIに接続するか選択できます。
Anacondaの利用
Pythonのインストールには、Anaconda5を使用することもできます。Anacondaとは、Anaconda社が開発、配布しているPythonディストリビューションです。Jupyter Notebook、JupyterLab、Numpy、pandas、Matplotlib、scikit-learnなど、データサイエンスで使用するライブラリのほとんどが一緒にインストールされるので、非常に便利です。
また、ライブラリのバージョン管理も、一元的にわかりやすく行うことができます。
ただし、無償で利用するには、Anacondaの利用規約(TOS)6を守らなければなりません。現時点での規約には以下のように書かれています。
You may not use Free Offerings for commercial purposes, including but not limited to external business use, third-party access, Content mirroring, or use in organizations over two hundred (200) employees (unless its use for an Educational Purpose) (each, a “Commercial Purpose”). Using the Free Offerings for a Commercial Purpose requires a Paid Plan with Anaconda.
翻訳すると
無料提供物を商業目的で使用することはできません。商業目的には、外部のビジネス目的、第三者のアクセス、コンテンツのミラーリング、または従業員数が200人を超える組織での使用(教育目的である場合を除く)が含まれます。商業目的で使用する場合は、Anacondaの有料プランが必要です。
となっています。変更になる場合もありますので、最新の規約に従ってください。
2. Data Wranglerの起動
(a) チュートリアルから起動
Ctl + Shift + P を押してコマンドパレットから Data Wrangler: Open Walkthrough を選択すると、以下のような画面が表示されます。
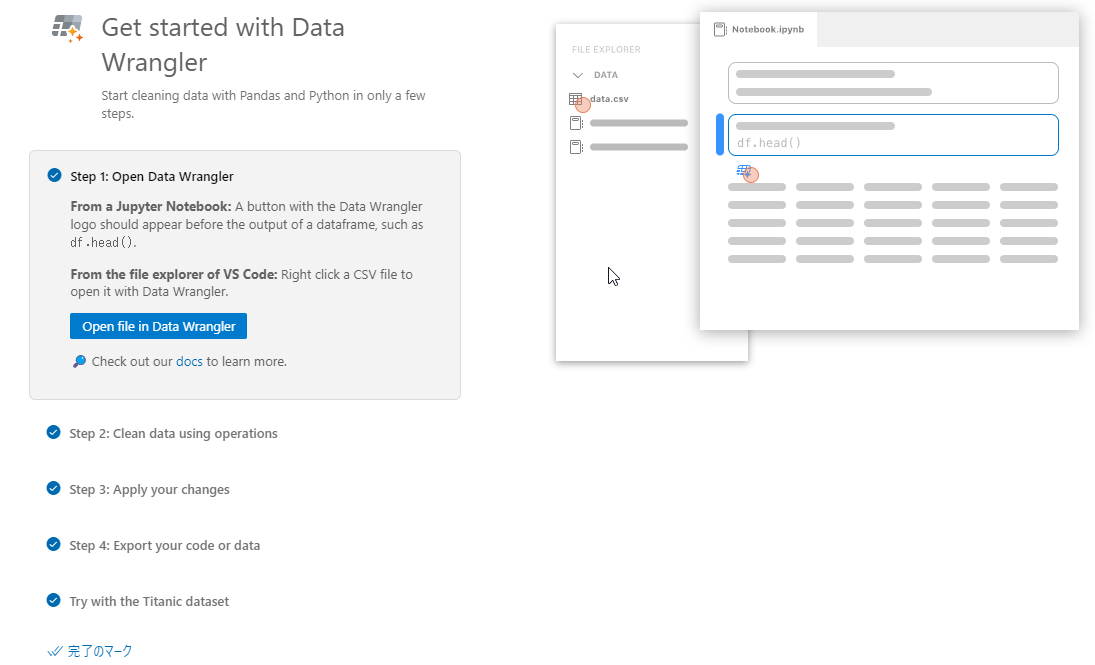
Step 1の Open file in Data Wrangler を使ってデータファイルを読み込みます。
また、Try with the Titanic dataset を開くと、各種チュートリアルで使われることが多いタイタニック号の乗客データを読み込むことができます。

※今回は、Kaggleにあるtrain.csvというデータセットを使用しています。7
| 項目名 | 内容 |
|---|---|
| Survived | 生存したかどうか 0 = No, 1 = Yes |
| Pclass | チケットのクラス 1 = 1st, 2 = 2nd, 3 = 3rd |
| Name | 名前 |
| Sex | 性別 |
| Age | 年齢 |
| SibSp | 同乗していた兄弟や配偶者の数 |
| Parch | 同乗していた親や子供の数 |
| Ticket | チケット番号 |
| Fare | チケット料金 |
| Cabin | キャビン番号 |
| embarked | 乗船した港 C = Cherbourg, Q = Queenstown, S = Southampton |
(b) Jupyter Notebookから起動
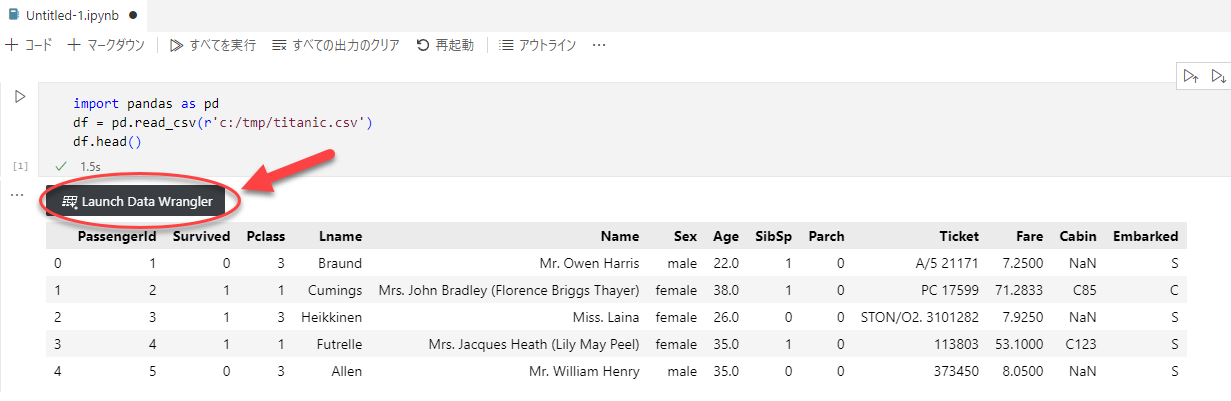
コマンドパレットから Create: New Jupyter Notebook を選択すると、Jupyter Notebookが起動し、セルが表示されます。その中でデータを用意し、head()を実行すると、 Launch Data Wrangler のボタンが表示されますので、ここから起動できます。
(c) ファイルから起動
VS Codeのエクスプローラーからデータファイルを右クリックし、Open in Data Wrangler を選択します。

3. Data WranglerのUI
初期状態で、6つのコンポーネントが表示されます。それぞれのコンポーネントは、位置を変更することができます。

(a) Data Wrangler Grid
データセットの値を確認できます。
(b) Quick Insight
列ごとにデータの型や一意の値、欠損値、データ分布などの情報が確認できます。

(c) Operations Panel
データクリーニング操作が選択できます。
(d) Data Summary Panel
列が選択されていないときは、テーブルの概要が表示されます。

列が選択されているときは、その列の情報が表示されます。

(e) Cleaning Steps Panel
操作した手順ごとにステップとして表示します。
遡って操作を確認することができます。
ステップの削除ができますが、最後の操作に対してしか行えません。
(f) Code Preview Panel
Cleaning Steps Panelで選択した操作の自動生成された Pytnon コードが表示されます。
最後のステップは、パネル内のコードを編集することもできますが、途中のステップのコードの編集はできません。
4. データ操作
Operation Panelからは、以下の操作ができます。
- Find and Replace (検索と置換)
- Drop duplicate row (重複行の削除)
- Drop missing values (欠損値の削除)
- Fill missing values (欠損値の補完)
- Find and replace (検索と置換)
- Format (書式)
- Convert text to capital case (1文字目を大文字に変換)
- Convert text to lower case (小文字に変換)
- Convert text to upper case (大文字に変換)
- String transform by example (文字列を例を使って変換)
- DateTime formatting by example (日時を例を使って変換)
- Split text (文字列の分割)
- Strip whitespace (空白の削除)
- Formulas (演算)
- Multi-label binarizer (区切り記号による分割)
- One-hot encode (カテゴリごとに新しい列を追加)
- Calculate text length (文字列の長さを新しい列に入れる)
- Create column from formula (計算結果を新しい列に入れる)
- Schema
- Change column type (列の型の変更)
- Drop columns (列の削除)
- Rename column (列名変更)
- Select columns (列の選択)
- Sort and filter (ソートとフィルター)
- Filter (フィルター)
- Sort values (ソート)
- Custom operation (カスタム操作)
- Group by and aggregate (グループ化と集計)
- New column by example (例から列の追加)
- Scale min/max values (最大値と最小値の間にスケーリング)
また、カラム名の右にある三点リーダーを使って、ソート、フィルターなどの操作を行うこともできます。

(a) Fill missing values (欠損値の補完)
値の置き換えなどの操作を行う場面では、変更前、変更後の列が並んで表示されるので、変更内容を確認して Apply で操作を適用します。

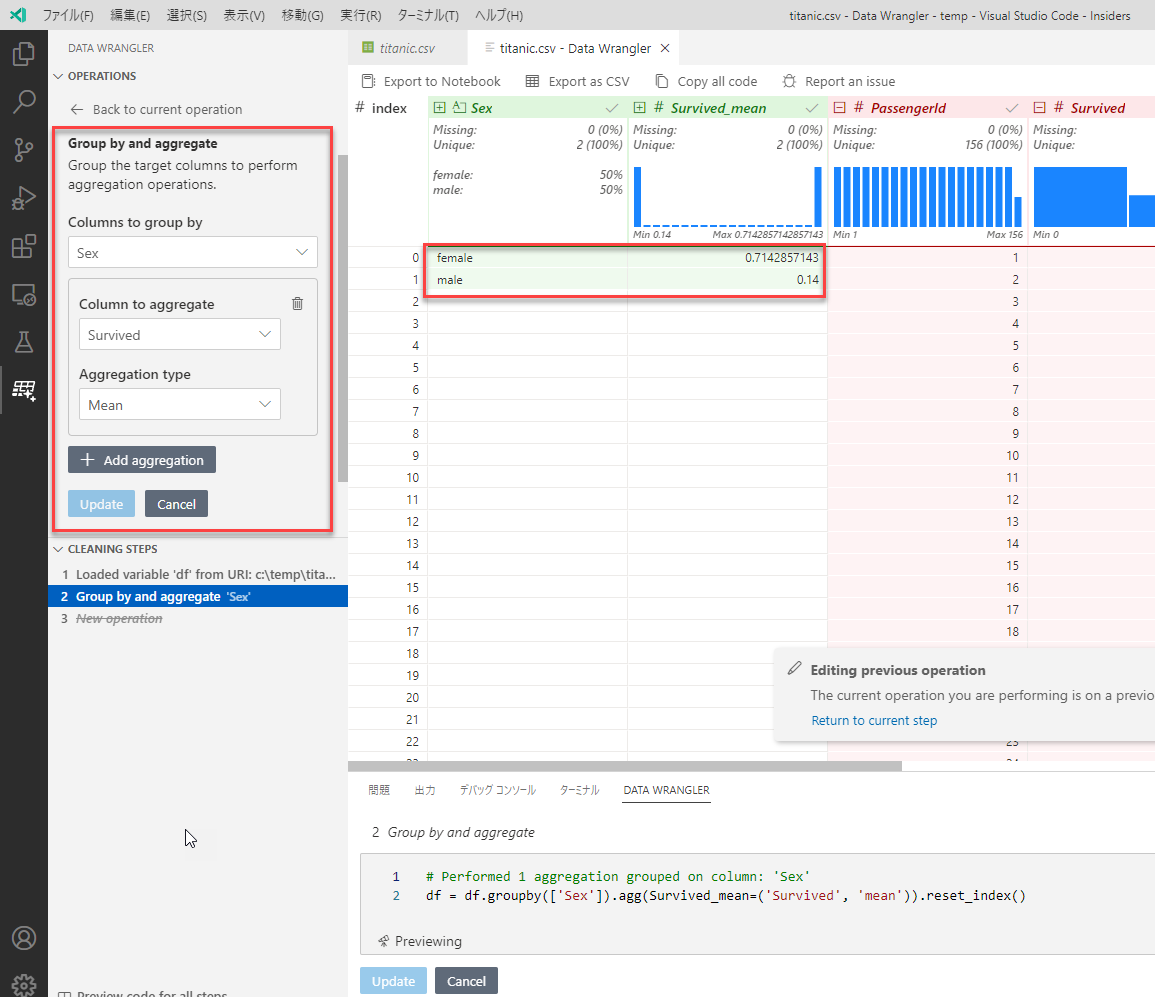
(b) Group by and aggregate (グループ化と集計)
グループ化を使って集計を行うことができます。下の例では、性別でグループ化して生存率を計算しています。男性より、女性の方が遥かに生存率が高かったことが分かります。
(c) String transform by example (文字列を例を使って変換)
式を書かずに、変換する元の列と結果を入力してコードを作成することができます。この機能は、AIを利用したエクセルのフラッシュフィル機能と同じ Microsoft Program Synthesis using Examples (PROSE) が用いられています。
下の図では、Nameの列を使って「Braund, Mr. Owen Harris」の文字列に対して変換結果の「Owen」を入力した結果です。

2行目以降について、自動的に変換結果が埋められていますが、「Laina」については ? が表示され、変換が正しいか確認を求めています。1つの例でうまくいかない場合は、2つ目の例を入力して期待する結果を求めます。
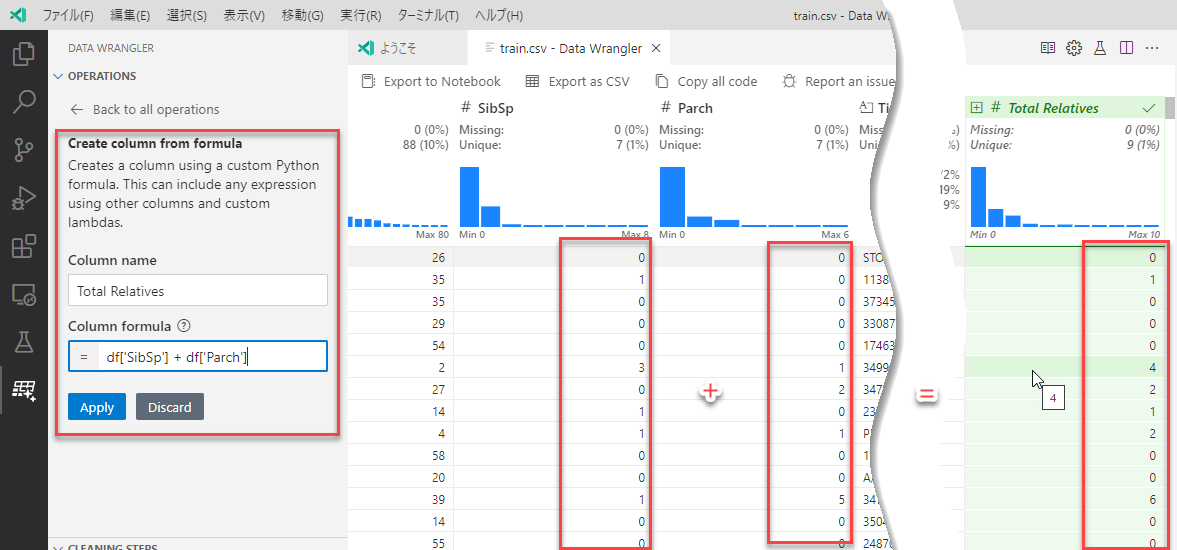
(d) Create column from formula (計算結果を新しい列に入れる)
計算結果を新しい列に入れます。
下の図では、SibSpとParchを足してTotal Relativesの列を作成しています。
5. コードのエクスポート
(a) Preview code for all steps
すべてのコードを見るには、CLEARNING STEPSのパネルの下にある Preview code for all steps を押します。

この操作では、ステップ順に並んだコードが表示されます。
# Loaded variable 'df' from URI: c:\temp\train.csv
import pandas as pd
df = pd.read_csv(r"c:\temp\train.csv")
# Drop column: 'Cabin'
df.drop(columns=['Cabin'], inplace=True)
# Replace missing values with the mean of each column in: 'Age'
df.fillna({'Age': int(df['Age'].mean())}, inplace=True)
# Derive column 'First Name' from column: 'Name'
# Transform "Name" as per the following examples:
# Braund, Mr. Owen Harris ==> Owen
df.insert(4, "First Name", df["Name"].str.split(" ").str[2])
# Created column 'Total Relatives' from formula
df['Total Relatives'] = df['SibSp'] + df['Parch']
(b) Export to Notebook
Export to Notebook をクリックすると、右側にすべてのコードが記述されあtJupyter Notebookが現れます。

この操作と、以下のCopy all codeの操作で得られるコードでは、手順が関数の中に定義されます。
import pandas as pd
def clean_data(df):
# Drop column: 'Cabin'
df.drop(columns=['Cabin'], inplace=True)
# Replace missing values with the mean of each column in: 'Age'
df.fillna({'Age': int(df['Age'].mean())}, inplace=True)
# Derive column 'First Name' from column: 'Name'
# Transform "Name" as per the following examples:
# Braund, Mr. Owen Harris ==> Owen
df.insert(4, "First Name", df["Name"].str.split(" ").str[2])
# Created column 'Total Relatives' from formula
df['Total Relatives'] = df['SibSp'] + df['Parch']
return df
# Loaded variable 'df' from URI: c:\temp\train.csv
df = pd.read_csv(r"c:\temp\train.csv")
df_clean = clean_data(df.copy())
df_clean.head()
(c) Copy all code
Copy all code をクリックすると、クリップボードにすべてのコードがコピーされます。

このコードを別途Jupyter Notebookに張り付け、更に分析を続けることができます。
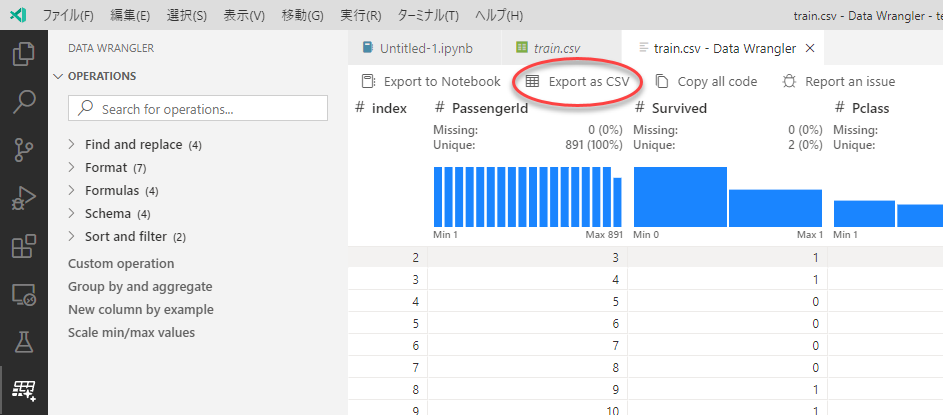
6. データのエクスポート
処理結果のデータをエクスポートするには、Export as CSVをクリックします。
Troubleshooting and providing feedback
-
Data Wrangler Walkthrough, Jeffrey Mew, 2023/3/22, https://youtu.be/KrzcV1c1W1U ↩
-
Download Visual Studio Code Insiders https://code.visualstudio.com/insiders/ ↩
-
Python Downloads https://www.python.org/downloads/ ↩
-
Visual Studio Marketplace https://marketplace.visualstudio.com/items?itemName=ms-toolsai.datawrangler ↩
-
Anaconda https://www.anaconda.com/ ↩
-
Anaconda Terms of Service https://legal.anaconda.com/policies/en/?name=terms-of-service ↩
-
Titanic - Machine Learning from Disaster https://www.kaggle.com/c/titanic/data ↩