データを分位数で分けたり、ビン数でわけたりすることをビン化(binning)といいます。SPSS Modeler
SPSS Modelerでこのビン化を行うのがデータ分割ノードです。
優良顧客を判別したり、購入価格帯のボリュームゾーンを探したりすることができます。
このデータ分割ノードを解説するとともに、Pythonのpandasで書き換えてみます。
0.元データ
ここではID付POSデータを対象に行います。
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータを使います。
これを誰(CUSTID)が全部でいくら(SUBTOTAL_sum)購入したかというデータに集計してから使います。

以下のようなデータになります。2744件あります。
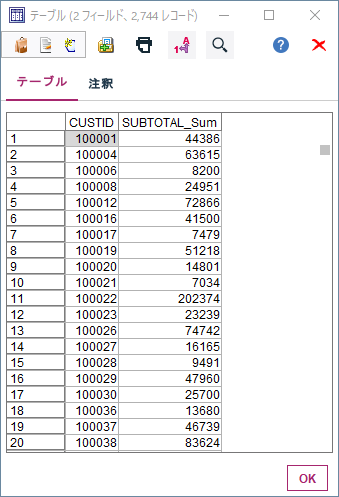
1m.①分位数、デシル分析 Modeler版
売上金額を上位から並べて、同じ人数で分けてみます。ここで10グループ(ビンといいます)に分割する10分位で分割します。2744人いるので1グループ約274人ずつに分けられます。
以下の設定をします。SUBTOTAL_sumを基準に10個のビンに分けるという意味です。
ビンフィールド:SUBTOTAL_sum
データ分割手段:分位(等カウント)
10分位:チェック

以下のようなに総購入金額によって1から10までビンが作られます。

各ビンの閾値はデータ分割ノードのビンの値のタブで確認できます。ビン10の最優良顧客層は112,508円から828,844円の購入を行っています。

10分割したデータで各ビンの特徴を分析をすることをデシル分析といいます。優良顧客とそうでない顧客の違いなどを分析します。
ビンの番号は大きくなるほど優良顧客ということになっていますが、1位のグループのビン番号は1にした方が直感的なので、置換ノードで11からビン番号を引くことで順番を逆順にします。

デシル分析では各ビンを集計して構成比や累積構成比をみることをよく行います。
以下のようにビン(SUBTOTAL_sum_TILE10)をキーフィールドに設定して購入金額(SUBTOTAL_sum)を計算すると各ビンの総購入金額が出せます。
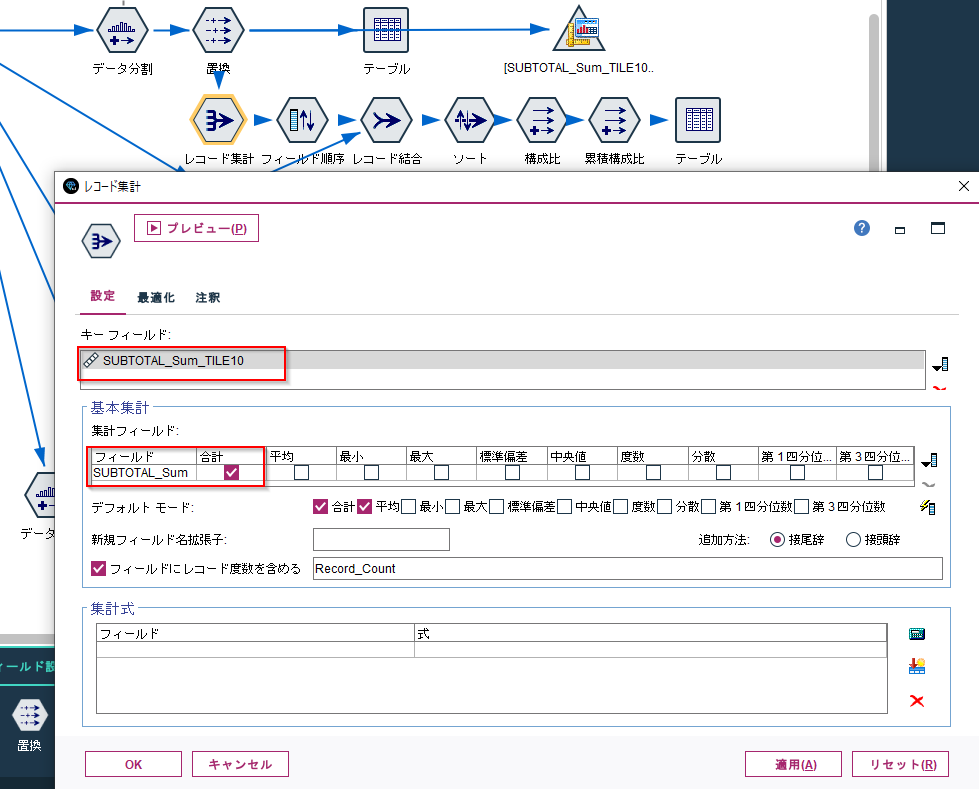
以下のようなデータが作れます。

上からさらに構成比や累積構成比を計算すると以下のようになります。
上位2つのビンで累積構成比が60%になっています。つまり上位20%の顧客で全売上の60%を占めていることがわかります。
こういった優良顧客への偏りはよくあることです。優良顧客がわかれば、優良顧客は他の顧客とどう違うか、どうやって優良顧客の離反を防ぐかなどの分析に進んでいくことができます。
なお、マーケティングでよく使われるRFM分析では、総購入金額(Monetary)だけではなく、回数(Frequency)や最終購入日(Recency)もビン化して要約をします。RFMすべてをビン化する場合は以下のRFM分析ノードを使うのが便利です。

1p.①分位数、デシル分析 pandas版
pandasでも分位数でビンを作ります。
その前にまず、CUSTID毎に購入金額(SUBTOTAL)の総額を集計します。
df_cust_total=df[['CUSTID','SUBTOTAL']].groupby(['CUSTID']).sum()
pandasで分位数でビニングを行う場合はpd.qcutを使います。
最初の引数はビニングの基準にするSeriesデータです。次の引数は分割数です。10分位なので10を設定しています。
labels=Falseでビンに連番を振ります。0-9で振られます。
retbins=Trueでビンの境界値を取得しています。decil_binsにビンの境界値のデータがndarrayで返ります。
10-df_cust['DECIL']で降順で1-10のビン番号を振りなおしています。
df_cust['DECIL'],decil_bins=pd.qcut(df_cust['SUBTOTAL'],10,labels=False,retbins=True)
df_cust['DECIL']=10-df_cust['DECIL']
print(df_cust)
print(decil_bins)
以下のような結果になります。
SUBTOTAL DECIL
CUSTID
100001 44386 4
100004 63615 3
100006 8200 9
100008 24951 6
100012 72866 2
... ... ...
105967 64780 3
105970 245616 1
105972 38744 4
105974 142537 1
105978 25447 6
[2744 rows x 2 columns]
[ 1009. 4924.8 9175. 14156.1 19777.6 27265. 36808.4 49254.
70421.6 112361.1 828844. ]
構成比、累積構成比は以下のように算出できます。
# デシルの構成比
df_decil=df_cust.groupby('DECIL').sum().sort_index()
df_decil['構成比']=df_decil['SUBTOTAL']/df_cust['SUBTOTAL'].sum()
df_decil['累積構成比']=df_decil['SUBTOTAL'].cumsum()/df_cust['SUBTOTAL'].sum()
df_decil

2m.②固定幅:ビン数指定 Modeler版
分位でのビンは件数を同じにしましたが、固定幅のビンは閾値の間隔を等間隔にしたビンを作ります。
度数分布表を作る場合に使います。売上のボリュームゾーンがどこにあるかなどを調べることができます。
以下の設定をします。SUBTOTAL_sumをの最大値と最小値の間を等間隔で10等分したビンを作るという意味です。
ビンフィールド:SUBTOTAL_sum
データ分割手段:固定幅
ビン数:10

以下のようにビン番号が割り振られます。

ビンの閾値は「ビンの値」タブで確認ができます。最小値の1,009から最大値の828,844までを等間隔で区切っています。
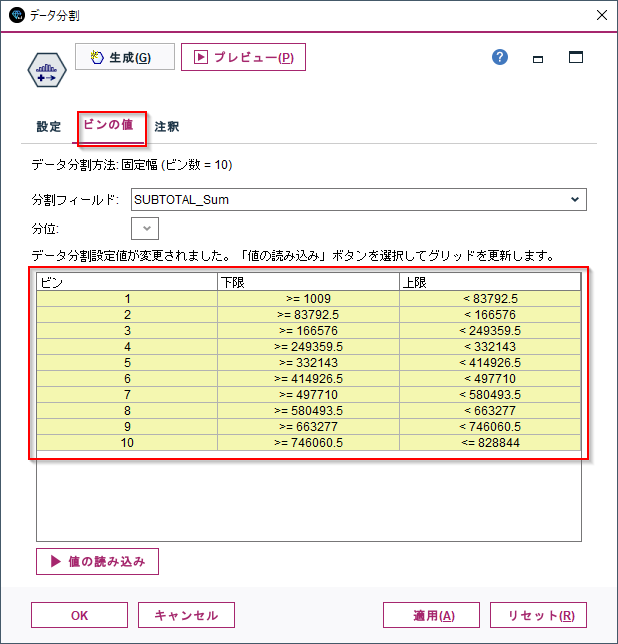
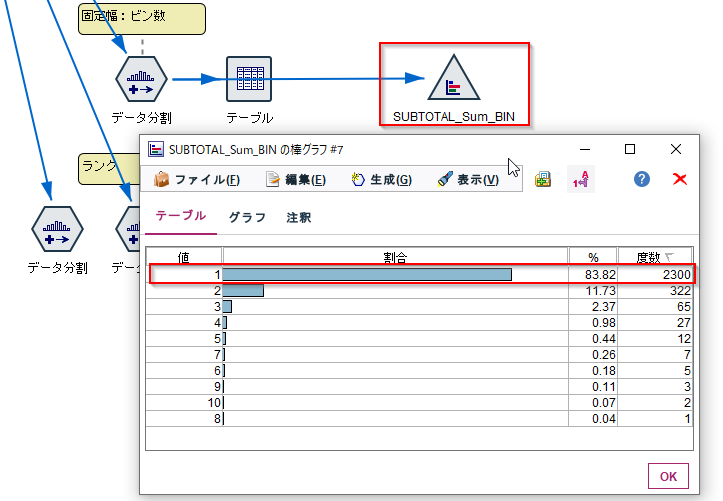
棒グラフノードで度数分布をグラフ化してみると以下のようになります。83792.5未満の購入金額が83%を占めていることがわかります。
2p.②固定幅:ビン数指定 pandas版
pandasで固定幅でビニングを行う場合はpd.cutを使います。
最初の引数はビニングの基準にするSeriesデータです。次の引数は分割数です。10個のビンにわけるので10を設定しています。
labels=Falseでビンに連番を振ります。0-9で振られます。(Modelerと合わせる場合は+1してください)
retbins=Trueでビンの境界値を取得しています。fixed_binsにビンの境界値のデータがndarrayで返ります。
df_cust2['BIN'],fixed_bins=pd.cut(df_cust2['SUBTOTAL'],10,labels=False,retbins=True)
print(df_cust2)
print(fixed_bins)
SUBTOTAL BIN
CUSTID
100001 44386 0
100004 63615 0
100006 8200 0
100008 24951 0
100012 72866 0
... ... ...
105967 64780 0
105970 245616 2
105972 38744 0
105974 142537 1
105978 25447 0
[2744 rows x 2 columns]
[ 181.165 83792.5 166576. 249359.5 332143. 414926.5
497710. 580493.5 663277. 746060.5 828844. ]
なお、ビンの境界値の最小値が181.165になっていました。最小値は1009なので合っていませんでした。181.165以上83792.5未満でも1009は含まれるので実害はありませんが、謎の現象でした。
次に構成比を計算してみます。まずBINでgroupbyしてcountします。count後も列名がSUBTOTALだとややこしいので、COUNTという列名に変更しています。その後df_cust2_bin['COUNT'].sum()で割って算出しています。
やはり83792.5以下で約83%を占めていることがわかります。
df_cust2_bin=df_cust2.groupby(['BIN']).count().rename(columns={'SUBTOTAL':'COUNT'})
df_cust2_bin['構成比']=df_cust2_bin['COUNT']/df_cust2_bin['COUNT'].sum()

3m.③ランク付け Modeler版
ランクは@INDEXを使うような方法が一般的ではありますが、データ分割ノードでも簡単に作成できるので解説しておきます。
売上上位100顧客、100商品などを抽出することに使えます。
以下の設定をします。SUBTOTAL_sumでランク付けをするという意味です。
ビンフィールド:SUBTOTAL_sum
データ分割手段:ランク

ソートも組み合わせることで以下のような売上順のデータを作ることが可能です。_F_RANKや_P_RANKには上位N%に入るかのパーセンテージが入ります。

なお、データ分割ノードでは全レコードでしかランク付けができませんが、カテゴリごとにランク付けをする場合には以下の方法をとる必要があります。
Modelerのデータ分割の方法には分位や固定幅、ランク以外にも以下のデータ分割の方法があります。
- 平均と標準偏差
- カテゴリーの「スーパバイザ」フィールドに関連する最適化
平均と標準偏差はzスコア化して整数化するものです。これは以下の記事のようなデータの準備ノードでも
行えます。
カテゴリーの「スーパバイザ」フィールドに関連する最適化はスーパーバイザフィールドに指定したカテゴリー変数を目的変数のようにあつかって、特徴がでるように閾値を決める機能です。決定木で数値型のデータの境界値をきめるようなロジックになります。ロジスティック回帰の特徴量生成などに応用できます。
pandasでは同様の機能はなさそうでしたので、今回は詳しくは取り扱いません。
3p.③ランク付け pandas版
pythonの場合はrankメソッドを使います。ascending=Falseで売上上位順になります。
上位N%かはlen(df_cust3)でrankを割ることで算出できます。
df_cust3['rank']=df_cust3['SUBTOTAL'].rank(ascending=False)
df_cust3=df_cust3.sort_values(['rank'])
df_cust3['p_rank']=df_cust3['rank']/len(df_cust3)

4. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/raw/master/binning/210811binning.str
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/binning/binning.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/credit_risk.csv
■テスト環境
Modeler 18.3
Windows 10 64bit
Python 3.8.5
pandas 1.0.5
5. 参考情報
データ分割ノード - IBM Documentation
pandasのcut, qcut関数でビニング処理(ビン分割)