様々な車のスペック情報をSPSS Modelerで分析して、クラスタリングによるマーケット分析を行ってみたいと思います。
データと完成版サンプルストリームは以下のzipファイルに入っています。
https://github.com/hkwd/200603AutodataAnalysis/archive/master.zip
データ:cars_data_j.csv
ストリーム:自動車スペッククラスタリング1.str
1. データ
UCI: Automobile Data Setを使います。
https://dataplatform.cloud.ibm.com/exchange/public/entry/view/9704374ab42cdd449b6112a0981dfbe1#
Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
元データは英語だったので、日本語に翻訳したデータcars_data_j.csvを準備しました。
キャンバスにドラッグアンドドロップしておいてください。

出力パレットからテーブルノードを選び、car_data_j.csvに接続し、テーブルノードを選択したうえで、選択内容を実行ボタンを押してください。

まず、26のフィールドがあり、201車種の情報が入っています。
もともとが自動車保険のデータなので、リスクや損失などの情報が最初の2列にあります。
そのほか、メーカー名や燃料タイプ、エンジンの位置、などの車のスペック情報が続き、最後に都市燃費、高速道路燃費、価格があります。

201車種のデータをただ眺めていても、このデータの中にどんな車があるのかを理解することが困難です。クラスタリングはたくさんのデータの中から似たような傾向のデータを持つ数個のグループにまとめることができます。そうやってまとめることでデータの全体像を理解することを助けます。また、自社の製品ラインナップや似たような車種の競合との比較
今回はこれらの様々なスペックを持つ自動車をクラスタリングでグルーピングしてみたいと思います。
右上の赤い×ボタンで閉じてください。
2. クラスタの作成
まず、フィールド設定のパレットからデータ型ノードを選び、cars_data_j.csvにつなぎ、ダブルクリックでプロパティを開きます。

値の読み込みボタンをクリックします。都市燃費のロールを対象としてください。設定ができたらOKボタンで閉じます。

モデル作成パレットでセグメンテーションを選び、その中からK-Meansノードを選び、データ型ノードにつないで選択した状態で、選択内容を実行ボタンを押します。

黄色のナゲットが作成されますので、以下のように場所を少し動かして、これをダブルクリックして内容を確認します。

クラスター1から5までの5つのクラスターが作成されました。ビューをクラスターに変更して、「セルには相対分布を表示」をクリックし、各クラスターのグラフが少し見やすくなるように広げます。
どういうクラスターができたか、それぞれのクラスターの特徴をつかんでラベルを付けていきたいと思います。

クラスター2の燃料タイプをクリックしてください。右のビューにセルの分布が表示されます。すべてがDieselになっています。他のクラスターとはっきりと区別できますので、このクラスターのラベルを「ディーゼル」と入力します。

相対分布でもクラスターの特徴は分かりますが、選択したクラスター間のみの比較を行う機能もあります。
クラスター2以外のクラスターを選択してください。
そうすると右のビューにクラスターの比較が表示されます。数値データは箱ひげ図で分布が表現され、カテゴリー値は最大カテゴリの件数が円のサイズで表現されます。
この結果を見るとクラスター3は2ドアのコンパクトカーが集まっているようです。このクラスターのラベルを「2ドアコンパクト」と入力します。

次にクラスター5に注目すると車両重量が大きく、全長も大きくなっています。このクラスターのラベルを「大型」と入力します。

次にクラスター1に注目します。ボディスタイルのセルをクリックすると「オープンカー」はすべてこのクラスターに分類されています。

またドア数のセルをクリックするとすべて「two」になっています。

これらの傾向からクラスター1はスポーツカーということにします。

最後に残ったクラスター4に注目します。ボディスタイルはワゴンやセダンが多く、価格は低く、燃費もまずまずです。

これらの傾向からクラスター4はファミリーということにします。
このように201車種あったデータを5つの似た傾向にあるグループにまとめることができました。このようにまとめることでデータの全体像を要約して理解しやすくすることができます。

OKで閉じてください。
3. クラスタの分析1:燃費と価格
クラスターのラベルをデータにも反映します。
フィールド設定パレットからデータ分類ノードを選択し、黄色のナゲットに接続し、ダブルクリックでプロパティを開きます。

データ分類フィールドに$KM-K-Meansを選びます。
新規フィールド名には「クラスター」と入力してください。
データ分類値の取得ボタンをクリックするとクラスター1から5が表示されますので、対応するスポーツカー、ディーゼル、2ドアコンパクト、ファミリー、大型と入力し、OKで閉じてください。

出力パレットからテーブルノードを選びクラスターノードのナゲットの後ろに接続して、選択内容を実行ボタンを押してください。

スライドバーを一番右まで動かすと各車種に対応したクラスターのラベルが割り当てられています。

確認ができたら赤い×ボタンで閉じてください。
例えばある顧客が車を購入する際に重視する基準が価格と都市燃費だとします。各クラスターがその基準に照らしてどういう傾向をもっているか見てみます。
グラフ作成パレットから散布図ノードを選びクラスターノードに接続し、ダブルクリックでプロパティを開きます。

Xフィールドに都市燃費、Yフィールドに価格、オーバーレイの色にクラスターを設定し、実行ボタンを押してください。

各クラスターで傾向がはっきり分かれているのがわかります。価格が安くて都市燃費が安いクラスターは2ドアコンパクトやファミリーになります。

確認ができたら赤い×ボタンで閉じてください。
グラフは保存不要なのでいいえで閉じます。

2ドアコンパクトに絞ってメーカーごとの比較をしたいと思います。
テーブルノードを選択して選択内容を実行ボタンを押してください。

右端までスクロールして2ドアコンパクトのセルを選び、生成メニューから条件抽出ノード("AND")を選びます。そして、赤い×ボタンで閉じてください。

(生成)という名前の条件抽出ノードがキャンバスにつくれられていますので、これをダブルクリックでプロパティを開きます。

選択していた、2ドアコンパクトに絞り込む条件が自動生成されています。確認ができたらOKで閉じてください。

(生成)という名前の条件抽出ノードを先ほどの散布図との間にはさみ、散布図を選択して、ダブルクリックでプロパティを開きます。

オーバーレイの形状にメーカーを設定し、実行ボタンを押してください。

2ドアコンパクトのみの散布図が表示されます。また、メーカーによって形を変えて表示しています。
これをみるとhondaは燃費や価格帯に広いバリエーションを持っているように見えます。
このように似た車種のグループ内で比較することで各メーカーのラインナップの傾向を読み取ることができます。

確認ができたら赤い×ボタンで閉じてください。
グラフは保存不要なのでいいえで閉じます。

4. クラスタの分析2:メーカーの戦略比較
次は各メーカーがどの車種グループに力を入れているのかを確認してみます。
レコード設定パレットからレコード集計ノードを選び、クラスターノードに接続します。接続できたらダブルクリックでプロパティを開きます。

キーフィールドに利用可能なフィールドの設定から取得のボタンを押します。

クラスターとメーカーを選び、OKで閉じてください。

キーフィールドにメーカーとクラスターが設定されたことを確認して、プレビューボタンを押します。

各メーカーごとにどんなクラスターの車種を何台作っているかがわかります。

確認ができたら、赤い×ボタンで閉じてください。
OKでレコード集計ノードのプロパティも閉じてください。

今作ったレコード集計ノードを右クリックしてノードをコピーを行います。

空いているスペースで右クリックをして、貼付けをします。

貼り付けられたレコード集計ノードをクラスターノードから接続し、ダブルクリックでプロパティを開きます。

キーフィールドでクラスターを削除し、フィールドにレコード度数を含めるの欄に「総件数」と入力し、プレビューボタンを押します。

今度は各メーカーごとの件数が集計されました。

確認ができたら、赤い×ボタンで閉じてください。
OKでレコード集計ノードのプロパティも閉じてください。

レコード設定パレットからレコード結合ノードを選択し、二つつくったレコード集計ノードを繋ぎます。そして、ダブルクリックでプロパティを開きます。

レコード結合方法でキーを選び、キーの候補でメーカーを選びます。そしてOKで閉じてください。
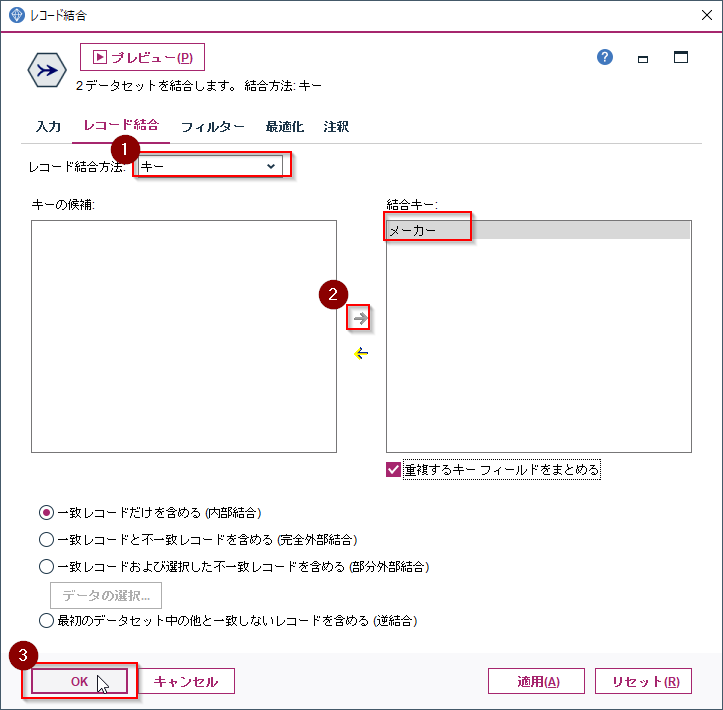
フィールド設定パレットからフィールド作成ノードを選び、レコード結合ノードの後ろにつなぎます。そしてダブルクリックでプロパティを開きます。

派生フィールドに「クラスター比率」と入力し、電卓のボタンで式ビルダーを開きます。

Record_Count / 総件数の入力をします。

プレビューボタンを押してください。

各メーカーのクラスターごとの車種の比率が計算されました。
例えばalfa-romeoは100%がスポーツカーでスポーツカーに特化した戦略をとっていることがわかります。

確認ができたら、赤い×ボタンで閉じてください。
クラスター比率のノードをOKで閉じてください。

グラフ作成パレットからグラフボードノードを選び、クラスター比率ノードの後ろに接続します。そしてダブルクリックでプロパティを開きます。

詳細タブを選び、視覚化タイプにヒートマップを選びます。そして列にメーカー、行にクラスター、色にクラスター比率を設定します。そして実行ボタンを押してください。

各社が力をいれているクラスターが比較できます。先ほどみたalfa-romeoは100%がスポーツカーでしたが、porscheやmercuryも同様です。
一方でmazda、nissan、toyota、volkswagenはファミリーを中心に全クラスターに展開をしています。そしてこの中ではvolkswagenはディーゼルにも力を入れています。

5. まとめ
このようにクラスタリングを行うことによって、201車種の個々のデータを見るだけではわからなかった、各社の戦略やマーケットの全体像が見えてきます。
ただし、このデータは市場のすべてのメーカーのすべての車種を網羅してはいませんので、あくまでもこのデータに限った分析例としてご理解いただければと思います。