SPSS Modelerで、カテゴリデータを統合したり、表記ゆれのあるカテゴリデータを統合したりする「分類ノード」をPythonのpandasで書き換えてみます。
0.加工前のイメージ
■加工前
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータを使います。
L_CLASSにはBAG,COSMETICS,SHOESの3つのカテゴリが含まれています。
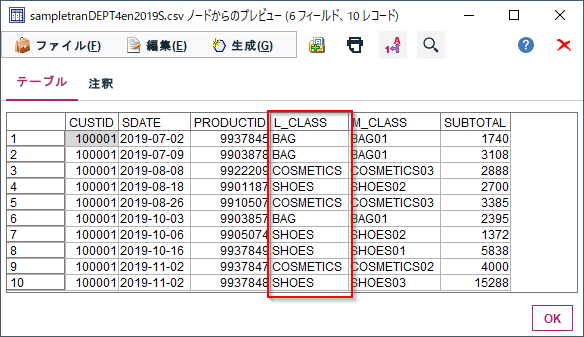
カテゴリが多すぎる場合にいくつかのカテゴリをまとめて一つのカテゴリにしたり、「バッグ」「bag」「鞄」などの表現が複数ある同じカテゴリを一つの「BAG」というカテゴリにまとめたり、ということにこの分類ノードは使います。
1m.①商品カテゴリの統合。Modeler版
■加工後イメージ
商品大分類(L_CLASS)の「BAG」と「COSMETICS」を「雑貨」という一つのカテゴリにまとめます。
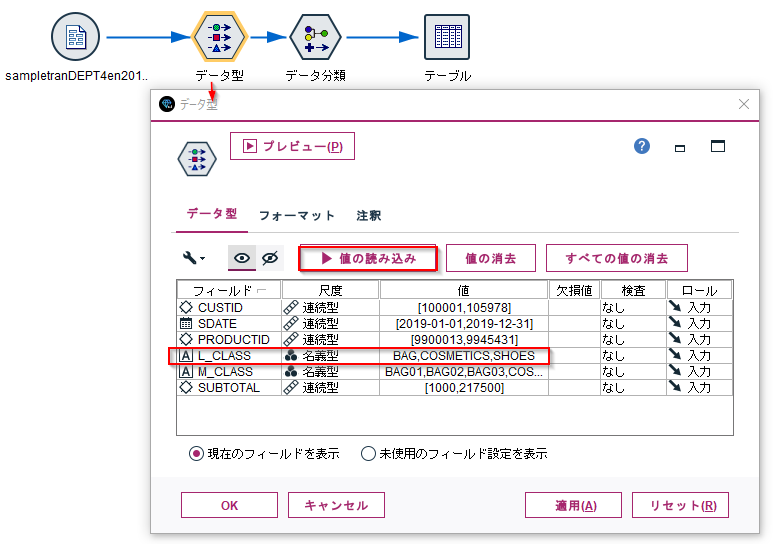
分類ノードを使うためには、まずカテゴリデータを「データ型」ノードでインスタンス化する必要があります。
データ型ノードで「値の読み込み」を行い、L_CLASSにあるカテゴリがBAG,COSMETICS,SHOESであることを読み込みます。
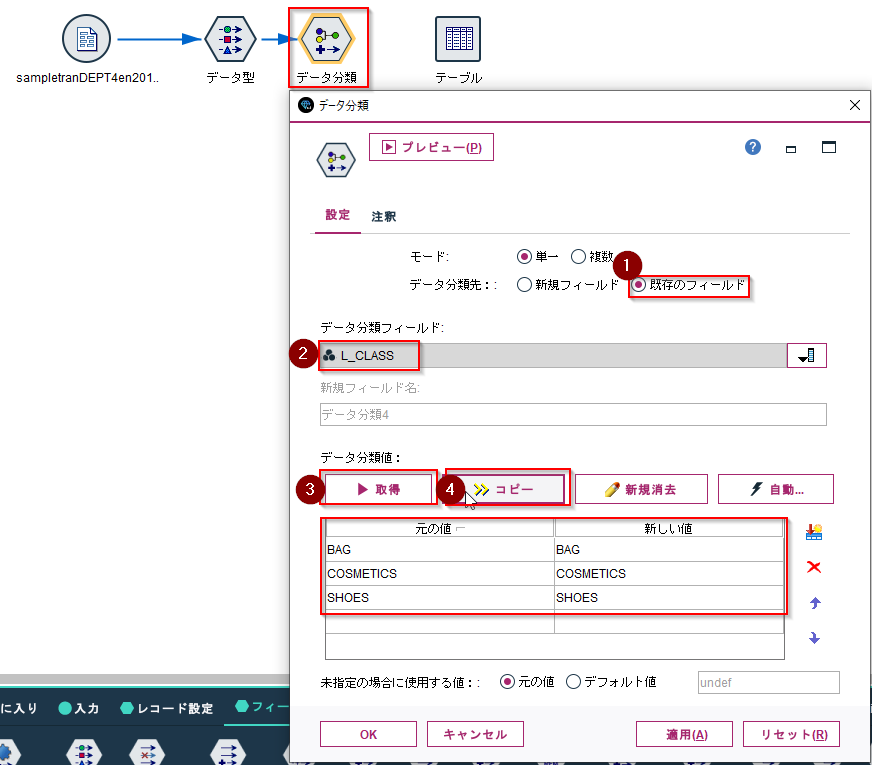
次にデータ分類ノードを接続します。
「データ分類先」は「既存のフィールド」に設定すると既存のカテゴリ列を入れ替えることができます。
「データ分類フィールド」に「L_CLASS」を選択します。
そして「取得」ボタンをクリックし、さらに「コピー」ボタンをクリックします。
そうすると以下のように元の値と新しい値としてBAG,COSMETICS,SHOESが入力されます。
そして、新しい値のBAG,COSMETICSを「雑貨」に書き換えます。
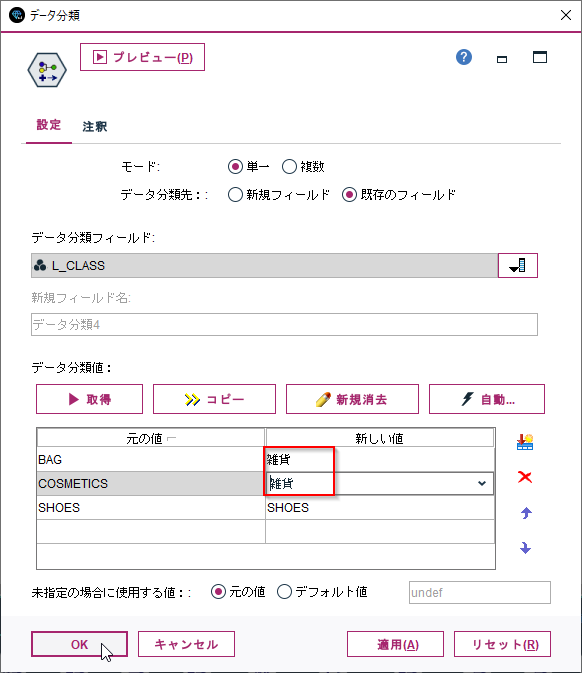
テーブルノードをつないで、再分類した結果を確認します。
BAG,COSMETICSが「雑貨」に変換されていることがわかります。
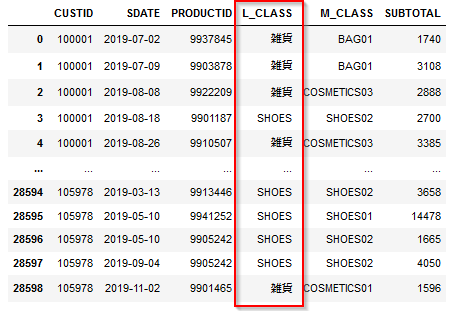
1p.①商品カテゴリの統合。pandas版
pandasでカテゴリ値を置き換える場合はreplace関数を使います。
分かりやすくするために置換するカテゴリ値のマッピングをコレクションで用意します。
そしてreplace関数の引数として、{列名:マッピング・コレクション}を引数として指定します。
mapping={'BAG': '雑貨',
'COSMETICS': '雑貨'}
df1=df.replace({'L_CLASS': mapping})
df1
以下のようにBAG,COSMETICSを「雑貨」に変換されていることがわかります。
replace自体は上記でできるのですが、Modelerのように、既存のカテゴリ値から初期値としてのマッピングのコレクションを作れると便利です。
df['L_CLASS'].unique()でカテゴリ値を抜き出しコレクションを作り、pprintでwidth=1を指定することで元の値と新しい値の組合せの初期値が表示できます。
mapping2={}
for val in df['L_CLASS'].unique():
mapping2[val]=val
import pprint
pprint.pprint(mapping2, width=1)
{'BAG': 'BAG',
'COSMETICS': 'COSMETICS',
'SHOES': 'SHOES'}
この結果からマッピングのコレクションを作れば作りやすいと思います。
2. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/blob/master/reclassify/reclassify.str?raw=true
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/reclassify/reclassify.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/sampletranDEPT4en2019S.csv
■テスト環境
Modeler 18.3
Windows 10 64bit
Python 3.8.10
pandas 1.3.0
3. 参考情報
pandas.DataFrame, Seriesの要素の値を置換するreplace
データ分類ノードのオプション設定 - IBM Documentation