以下の記事も参考にして、SPSS Modelerでタイムスタンプ関連のclem関数を使って、よく行う特徴量抽出を行ってみます。そしてその処理をPythonのpandasで書き換えてみます。
日付型については以下の記事で紹介しています。
代表的なものとして以下の加工処理を行っていきます。
- タイムスタンプデータの読み込み
- 文字列や数値からのタイムスタンプデータ生成
- 現在タイムスタンプの取得
- タイムスタンプの年、月、日、時、分、秒の分解
- タイムスタンプの差の計算
- タイムスタンプの大小比較
- タイムスタンプの加算減算
以下の、タイムスタンプ(TS),電力(Power),温度(Temperature),圧力(Pressure),起動時間(Uptime),状態(Status),エラーコード(Outcome)が記録された時系列のセンターデータを使います。毎分のセンサーの値が記録されています。今回はこの中のTSのみを使います。

1m.① 文字列や数値からのタイムスタンプデータ生成 Modeler版
文字列や数値からタイムスタンプ型データを生成してみます。タイムスタンプ演算をするために文字列データから型変換をすることはよくあります。また年、月、日、時、分、秒が別列に分かれて保存されている場合に、それらの列からタイムスタンプ型のデータを作成することもよくあります。
まずModelerのタイムスタンプや時間のフォーマットを確認しておきます。ストリームのオプションの「日付/時刻」の中にあります。YYYY-MM-DDとHH:MM:SSがデフォルトです。
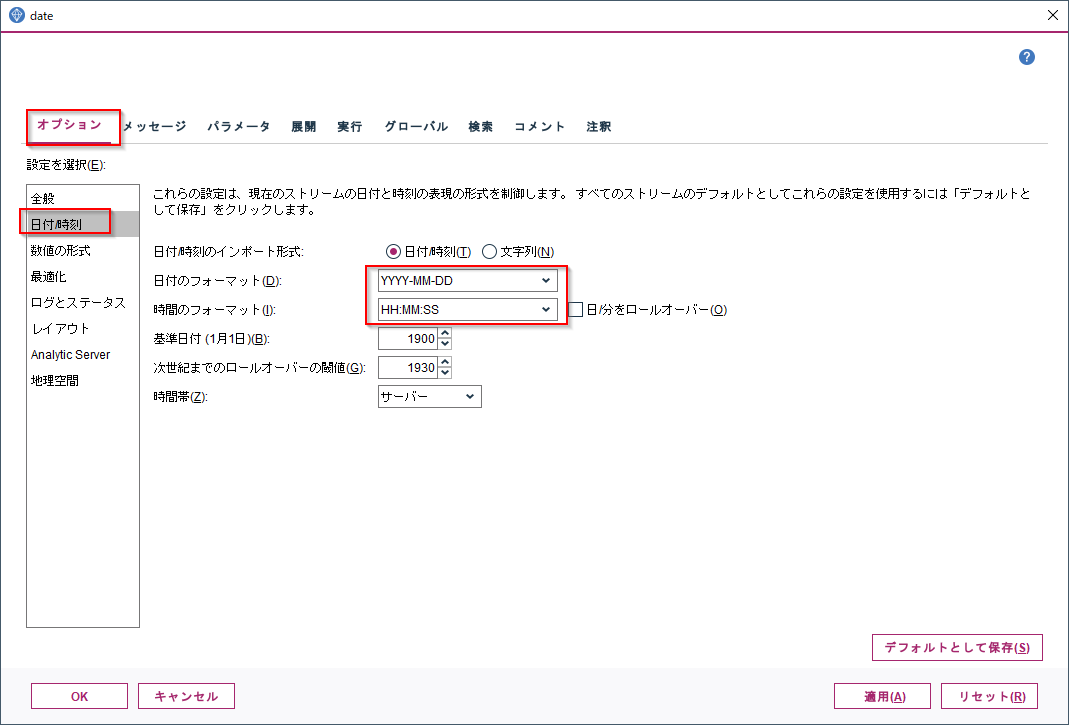
CSVデータを読み込んだ際に、デフォルトでは「自動的に日付と時間を認識します」のオプションが有効になっており、ストリームオプションで指定されていたYYYY-MM-DD HH:MM:SSで解釈できる文字列データはタイムスタンプデータとして読み込みます。


1p.① 文字列や数値からのタイムスタンプデータ生成 pandas版
pythonには以下のような複数のTimestamp型があります。
- datetime.datetime
- numpy.datetime64
- pandas._libs.tslibs.timestamps.Timestamp
#datetime.datetime
dtdt=datetime.datetime(2021, 6, 10, 3, 11, 0)
print(dtdt)
print(type(dtdt))
#numpy.datetime64
npdt=np.datetime64('2021-06-10 03:11:00')
print(npdt)
print(type(npdt))
#pandas._libs.tslibs.timestamps.Timestamp
pddt=pd.to_datetime('2021-06-10 03:11:00')
print(pddt)
print(type(pddt))
表示上はnumpy.datetime64は日付と時間の間に「T」が入っていました。
結果
2021-06-10 03:11:00
<class 'datetime.datetime'>
2021-06-10T03:11:00
<class 'numpy.datetime64'>
2021-06-10 03:11:00
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
この記事ではpandasのデータフレームを使うので、pandasのTimestamp型を使用していきます。
しかし、datetime.datetimeとnumpy.datetime64をpandasの列にいれると自動的にpandas._libs.tslibs.timestamps.Timestampに変換されていました。
dfdt.dtypesでみるといずれもdatetime64[ns]として表示されます。互換性があるようです。
dfdt =pd.DataFrame({'datetime':[dtdt],
'npdatetime':[npdt],
'pddatetime':[pddt]})
print(dfdt.dtypes)
print(type(dfdt['datetime'][0]))
print(type(dfdt['npdatetime'][0]))
print(type(dfdt['pddatetime'][0]))
datetime datetime64[ns]
npdatetime datetime64[ns]
pddatetime datetime64[ns]
dtype: object
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
<class 'pandas._libs.tslibs.timestamps.Timestamp'>

csvファイルからpandasに読むこむときにはデフォルトでは文字列型で読み込まれてしまいますが、パースしてタイムスタンプ型として読み込むこともできます。
parse_datesに列を指定すると、その列がタイムスタンプとして解釈できればタイムスタンプ型データとして読み込まれます。
#現在のタイムスタンプ
df = pd.read_csv('COND2nts.csv', parse_dates=['TS'])
print(df.dtypes)
print(type(df['TS'][0])
以下ではTS列が、文字列としてではなく、datetime64[ns]型で読み込まれています。
TS datetime64[ns]
Power int64
Temperature int64
Pressure int64
Uptime int64
Status int64
Outcome int64
dtype: object
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
- 参考
2m.② 文字列や数値からのタイムスタンプデータ生成 Modeler版
フィールド作成ノードで文字列からタイムスタンプ型データを生成してみます。datetime_dateという関数でストリームオプションで指定されていたYYYY-MM-DD形式で文字列を指定し、datetime_timeという関数でHH:MM:SS形式で文字列を指定します。そしてその日付型データと時間型データをdatetime_timestampでタイムスタンプ型として統合します。
datetime_timestamp(datetime_date('2021-04-01'),datetime_time('03:11:00'))

続いて、数値型データからタイムスタンプ型データを生成してみます。やはりdatetime_dateという関数を使いますが、年、月、日、時、分、秒の数値をカンマ区切りで指定します。
datetime_timestamp(2021,4,1,3,11,00)

データ型ノードをつかって確認してみると、アイコンがカレンダーと時計になり、尺度が連続型になっています。正しくタイムスタンプ型が生成されていることが確認できました。

2p.② 文字列や数値からのタイムスタンプデータ生成 pandas版
あらためて文字列からタイムスタンプ型データを生成してみます。pd.to_datetimeという関数でYYYY-MM-DD HH:MM:SS形式で文字列を指定します。YYYY-MM-DD HH:MM:SS形式以外のフォーマットの場合はformatstrのオプションでフォーマットを指定します。
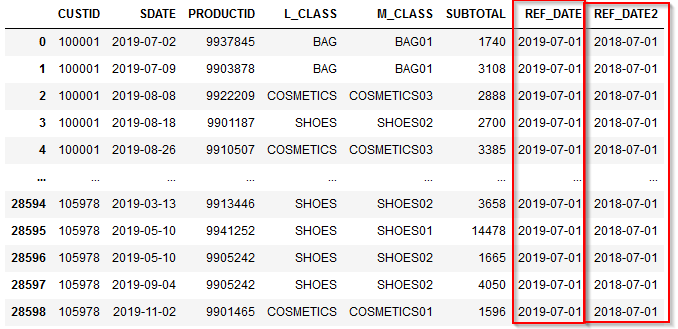
df1['REF_TS']=pd.to_datetime('2021-04-01 03:11:00')
続いて、数値型データからタイムスタンプ型データを生成してみます。いったんdatetime.dateで年、月、日、時、分、秒を数値で指定してdatetime.datetime型で生成します。pd.to_datetimeで変換せずとも自動的にpandas._libs.tslibs.timestamps.Timestampに変換されます。
df1['REF_TS2']=datetime.datetime(2021,4,1,3,11,0)
print(df1.dtypes)
TS datetime64[ns]
Power int64
Temperature int64
Pressure int64
Uptime int64
Status int64
Outcome int64
REF_TS datetime64[ns]
REF_TS2 datetime64[ns]
dtype: object
- 参考
3m.③現在のタイムスタンプの取得 Modeler版
「現在のタイムスタンプ」を取得してみます。現在のタイムスタンプはデータ生成日時の記録などによく使います。
フィールド作成ノードで「datetime_now」という関数を設定します。

現在のタイムスタンプが入ります。

3p.③ 現在のタイムスタンプの取得 pandas版
datetime.date.now()で現在のタイムスタンプを取得します。
なお、np.datetime64('now')でも取得はできましたが、マニュアルにこの記述方法がなかったので、datetimeを使う方法の方が堅いかと思います。
#現在のタイムスタンプ
df2['TODAYTS']=datetime.datetime.now()
#以下でも動作するがマニュアルに見当たらなかった。
#df2['TODAYTS']=np.datetime64('now')
print(df2.dtypes)
TS datetime64[ns]
Power int64
Temperature int64
Pressure int64
Uptime int64
Status int64
Outcome int64
TODAYTS datetime64[ns]
dtype: object

- 参考
4m.④ タイムスタンプの年、月、日、時、分、秒の分解 Modeler版
タイムスタンプから年、月、日、時、分、秒を取得してみます。時間毎のグループ化集計などのために抜き出すことがよくあります。
フィールド作成ノードでdatetime_year,datetime_month、datetime_day、datetime_hour、datetime_minute、datetime_secondという関数をつかって抜き出すことができます。ここではdatetime_minuteで分を抜き出してみます。


4p.④ タイムスタンプの年、月、日、時、分、秒の分解 pandas版
dtアクセサをつかって年year、月month、日day、時hour、分minute、秒secondの分解が可能です。dtアクセサはdayofyear(年初からの日数)やquarter(四半期)なども抜き出すことができます。
ここではdt.minuteで月を抜き出します。結果はintで返ります。
df3['MIN']=df3['TS'].dt.minute
TS datetime64[ns]
Power int64
Temperature int64
Pressure int64
Uptime int64
Status int64
Outcome int64
MIN int64
dtype: object

*参考
5m.⑤ タイムスタンプの差の計算 Modeler版
タイムスタンプ同士の差を計算してみます。あるシグナルとシグナルの時間間隔や傾きをとる場合など、時間差は重要な特徴量になりえます。
フィールド作成ノードでdatetime_in_secondsで秒に変換してから差を取ります。
以下の例だとタイムスタンプ(TS)- 基準タイムスタンプ(REF_TS)の秒数を返します。基準タイムスタンプ(REF_TS)>タイムスタンプ(TS)であればマイナスの値が返ります。
datetime_in_seconds(TS) - datetime_in_seconds(REF_TS)

さらに、分の単位で差をだしたい場合は60秒で割ることで、
( datetime_in_seconds(TS) - datetime_in_seconds(REF_TS))/60
時間の単位で差をだしたい場合は60秒60分で割ることで求めることができます。
( datetime_in_seconds(TS) - datetime_in_seconds(REF_TS))/(6060)
2021-04-01 03:11:00という基準日とタイムスタンプ(TS)の差がTS_DIFF秒、TS_DIFF分、TS_DIFF、に入っています。

5p.⑤タイムスタンプの差の計算 pandas版
まず、以下のように単純にタイムスタンプの入った列の引算を行います。
df4["TS_DIFF_TD"]=(df4["TS"]-df4["REF_TS"])
これは整数ではなく、pandas._libs.tslibs.timedeltas.Timedeltaという特殊な型(df5.dtypesの結果だとtimedelta64[ns])で値を返します。
ややこしいのは、Timedeltaはマイナスの時間を表さない仕様であることです。-1分の場合、-1 days +23:59:00というようなわかりにくい値が返ります(合計するとマイナス1分)。
これを.dt.secondsで秒数に変換してしまうと23:59:00を秒変換するので、86340秒(246060-60)という期待しない値が返ってしまいます。
単なる秒数がほしいので、dtアクセサとをtotal_seconds()メソッドつかって.dt.total_seconds()で秒数に変換します。プロパティではなくメソッドなので()が付くことに注意してください。
df4["TS_DIFF_TD"]=(df4["TS"]-df4["REF_TS"])
print(type((df4["TS_DIFF_TD"])[0]))
#以下は見た目も分かりやすい
df4["TS_DIFF秒"]=(df4["TS"]-df4["REF_TS"]).dt.total_seconds().astype('int')
df4["TS_DIFF分"]=(df4["TS"]-df4["REF_TS"]).dt.total_seconds()/60
df4["TS_DIFF時"]=(df4["TS"]-df4["REF_TS"]).dt.total_seconds()/(60*60)
#以下だとマイナスの時に間違った値が戻る
#df4["TS_DIFF"]=(df4["TS"]-df4["REF_TS"]).dt.seconds
#以下でも計算はできる
#df4["TS_DIFF秒"]=((df4["TS"]-df4["REF_TS"]) /np.timedelta64(1,'s')).astype('int')
#df4["TS_DIFF分"]=((df4["TS"]-df4["REF_TS"]) /np.timedelta64(1,'m'))
#df4["TS_DIFF時"]=((df4["TS"]-df4["REF_TS"]) /np.timedelta64(1,'h'))
print(df4.dtypes)
<class 'pandas._libs.tslibs.timedeltas.Timedelta'>
TS datetime64[ns]
Power int64
Temperature int64
Pressure int64
Uptime int64
...
REF_TS datetime64[ns]
TS_DIFF_TD timedelta64[ns]
TS_DIFF秒 int32
TS_DIFF分 float64
TS_DIFF時 float64
TS_DIFF_TDとTS_DIFF秒の結果は同じですが、TS_DIFF_TDにはtimedelta64[ns]型で格納され、TS_DIFF秒は整数型になっています。そしてマイナス値になるときにはTS_DIFF秒の方が理解しやすい値として返っています。例では-60秒です。

timedelta(Python)のマイナス値表現の謎 - Qiita
pandas.Series.dt.total_seconds
6m.⑥タイムスタンプの大小比較 Modeler版
タイムスタンプの大小比較をしてみます。ある作業工程以降かというようなフラグの特徴量が作れます。
フィールド作成ノードで派生:フラグ型に設定し、条件に以下を入力します。基準日より後の購入日ならフラグを立てるという意味です。
TS>REF_TS

2021-04-01 03:11:00
という基準タイムスタンプ以降の場合にAFTER_REFにTが立っています。

6p.⑥ タイムスタンプの大小比較 pandas版
以下のように単純にタイムスタンプの比較式を代入します。結果はbool型で返ります。
df5["AFTER_REF"]=(df5["TS"]>df5["REF_TS"])
print(df5.dtypes)
TS datetime64[ns]
Power int64
Temperature int64
Pressure int64
Uptime int64
Status int64
Outcome int64
REF_TS datetime64[ns]
AFTER_REF bool
dtype: object
2021-04-01 03:11:00という基準タイムスタンプ以降の売上の場合にAFTER_REFにTrueが立っています。

7m.⑦ タイムスタンプの加算減算 Modeler版
タイムスタンプに加算減算を計算してみます。起動からから3時間後というような計算です。
フィールド作成ノードでdatetime_in_secondsとdatetime_timestampという関数をつかって、タイムスタンプの3時間後を生成してみます。
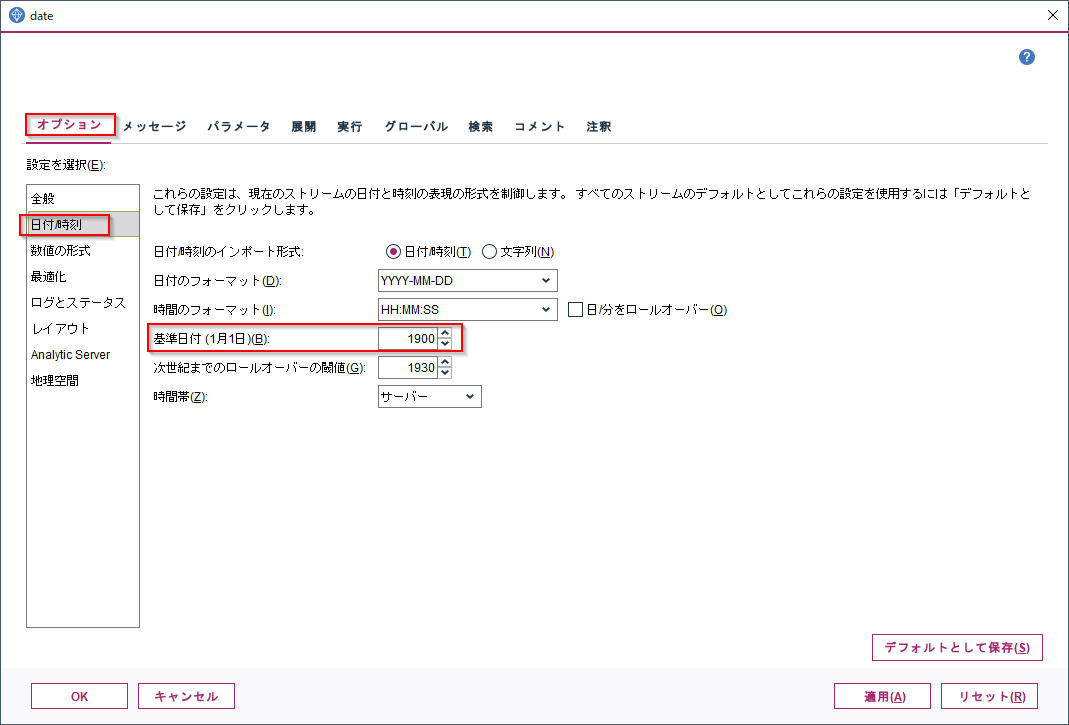
まずdatetime_in_seconds(TS)でタイムスタンプを基準日からの秒数に変換します。
基準日はデフォルトだと1900-01-01です。
次にこの秒数に3時間分の秒数を足します。3時間*60分*60秒です。
そしてこの秒数をdatetime_dateでタイムスタンプ型に変換しなおします。
つまり式としては以下になります。
datetime_timestamp(datetime_in_seconds(TS)+3*60*60)
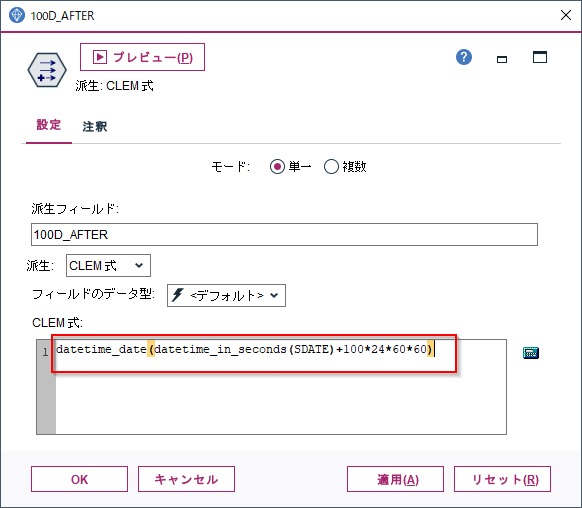
タイムスタンプ(TS)の3時間後のタイムスタンプが3H_AFTERに生成されました。

7p.⑦ タイムスタンプの加算減算 pandas版
datetime.timedeltaをつかって量と単位を指定して加算減算をします。以下の例は時間hoursを3個分足す、つまり3時間分足すという意味になります。hoursの部分を変えると分minutes、秒secondsなど別の単位でも加算減算が行えます。
df5['3H_AFTER']=df5["TS"]+ datetime.timedelta(hours=3)
#以下でも実現は可能
#df5['3H_AFTER']=df5["TS"]+ np.timedelta64(3,'h')
print(df5.dtypes)
TS datetime64[ns]
Power int64
Temperature int64
Pressure int64
Uptime int64
Status int64
Outcome int64
3H_AFTER datetime64[ns]
dtype: object
タイムスタンプ(TS)の3時間後のタイムスタンプが3H_AFTERに生成されました。

8. サンプル
サンプルは以下に置きました。
ストリーム
notebook
データ
■テスト環境
Modeler 18.2.2
Windows 10 64bit
Python 3.8.5
pandas 1.0.5
numpy 1.19.2