ネットワーク機器監視には、色々な目的があります。
・障害の早期発見と修正
・パフォーマンスの最適化
・セキュリティの向上
・コスト削減とリソース管理
・法的および規制要件の遵守 など
この記事は、最も一般的である「障害の早期発見と修正」について考察します。
1.監視区分
まず、監視区分としては下記が最低限必要となります。1. 正常監視(Alive監視/死活監視)。
2. 障害監視(異常監視)。
2.障害区分
次に、実際の障害は2種類に分類すべき。1. 既知の障害(Known Error)
2. 未知の障害(Unknown Error)

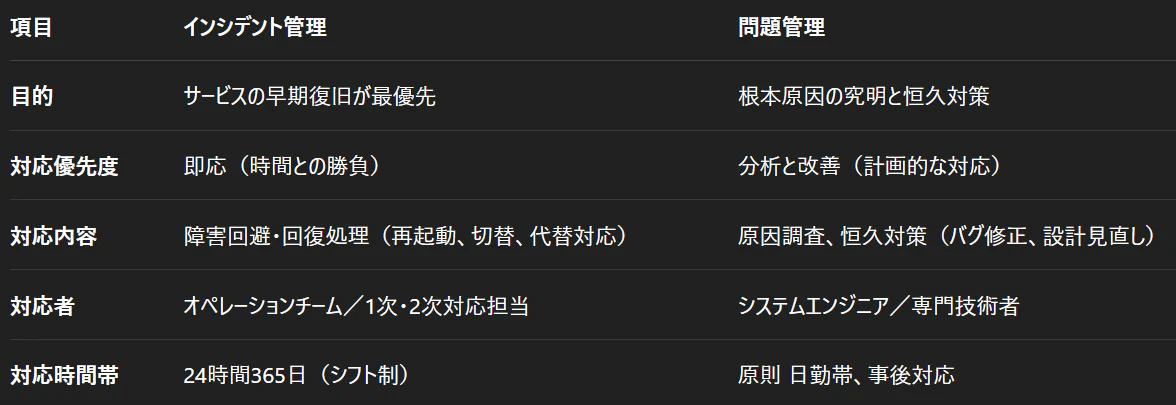
3.障害の管理区分
最後に、各障害区分ごとに担当者を分けるべき。理由は、それぞれの目的が異なり、担当者の稼働時間の性質も変わってくる為。
1. インシデント管理
2. 問題管理
4.実際の障害対応に当てはめて考える
これらの管理区分/項目をもとに、正常確認が確立していている状況で、未知の障害が発生した場合を考えてみます。(1)未知の障害が発生した場合:正常確認あり
・未知の障害が発生した場合、切り分け手順は確立されていない。・インシデント管理は「正常確認」により即時対応の要否を切り分けし、問題管理に報告。
・問題管理は、報告によって対応を判断できる。

次に、仮に正常確認が確立されていない場合はどうでしょうか。
(2)未知の障害が発生した場合:正常確認なし
確認方針を策定できないため、インシデント担当にも手順外の確認対応が多く発生する。結果、未知の障害が発生した際に、インシデント担当、問題管理担当が疲弊してしまう。
また、対応が属人化しやすく、切り分け品質が安定しない。

次に、障害通知が無い場合、Trap通知の損失(サイレント障害)や、アラーム設定が漏れていた場合。
(3)障害通知が無い場合:正常確認あり
障害監視よりは検知に時間がかかりますが、異常検知することができます。
(4)障害通知が無い場合:正常確認なし
検知できず、異常が発生してもクレームが来るまで放置されてしまいます。
5.正常確認の重要性まとめ
監視システムによるオペレータの監視は、監視設計のデザインする際、「監視画面の障害通知を確認する事」に特化する場合が多いですが、決して「正常確認」を忘れてはいけません。正常確認・障害確認の両方が揃って、システムの安定稼働の骨子ができあがるのです。 また、業務効率化が流行っていますが、進め方としては現状の情報/業務の導線をヒアリングし、それを最適化する事を目指すパターンが多いかと思います。しかし、そもそもの監視設計のデザインに欠陥がある場合(本記事では正常確認が確立していない等)は、頑張って業務導線を改善したところで、品質/コスト/スピードの効率化は望めないのです。
まず技術的に監視設計のデザインを確立し、その上で効率化を目指すという流れで、各システムを見直すと発見があるかもしれません。