前書き:
日本語はnativeではないため、おかしい表現や誤った文法が結構あると思うので、指摘していただくとありがたいです。
また、個人的なサマリーなので、内容についての指摘も歓迎です。
1.オブジェクト指向とプロセス指向の違い
プロセス指向
**メリット:**クラスを呼び出し時にインスタンス化する必要があり、コストが比較的高く、リソースを消費するため、パフォーマンスはオブジェクト指向より優れています。たとえば、パフォーマンスが最も重要の場合:マイクロコントローラ、組み込み開発、Linux / Unixなどは一般にプロセス指向開発を採用しています。
**デメリット:**オブジェクト指向のようなメンテナンスが簡単、再利用が簡単、拡張が簡単ではありません。
オブジェクト指向
**利点:**保守が簡単、再利用が簡単、そして拡張が容易です。
カプセル化、継承、およびポリモーフィズムのオブジェクト指向機能により、低結合のシステム設計は設計されることができ、より柔軟で保守しやすくといえます。
**デメリット:**パフォーマンスがプロセス指向より低いです。
2. Java言語の特徴は何ですか?
1.学びやすい。
2.オブジェクト指向(カプセル化、継承、多態)
3.プラットフォーム独立性(Java仮想マシンの力で実現)
4.信頼性
5.セキュリティ
6.マルチスレッドのサポート(C++言語にはマルチスレッドメカニズムが組み込まれていないため、マルチスレッドプログラミングの場合はオペレーティングシステムのマルチスレッド機能を呼び出す必要がありますが、Java言語ではマルチスレッドサポートを提供します)。
7.ネットワークプログラミングをサポートし、非常に便利(Java言語自体はネットワークプログラミングを単純化するように設計されているので、Java言語はネットワークプログラミングをサポートするだけでなく便利でもあります)。
8.コンパイルと解釈共存
3. JVM JDKとJREに関する最も簡単な答え
JVM
Java仮想マシン(JVM)は、Javaバイトコードを実行している仮想マシンです。 JVMは、同じバイトコードを使用して同じ結果を得ることを目的として、異なるシステム(Windows、Linux、macOS)に固有かつ対応ができる実装を持っています。
バイトコードとは何ですか?バイトコードを使用する利点は何ですか?
Javaでは、JVMが理解できるコードは
bytecode(拡張子.classのファイル)と呼ばれ、特定のプロセッサ向けではなく、仮想マシン専用です。バイトコードによって、Java言語は、翻訳された言語の移植性を保持しながら、ある程度まで伝統的な翻訳された言語の低効率の問題を解決します。そのため、Javaプログラムの方が実行効率が高く、バイトコードは特定のマシンに固有のものではないため、Javaプログラムは再コンパイルすることなくさまざまなコンピュータ上で実行できます。
Javaプログラムは一般に、実行するためにソースコードから以下の3つのステップを持ちます。
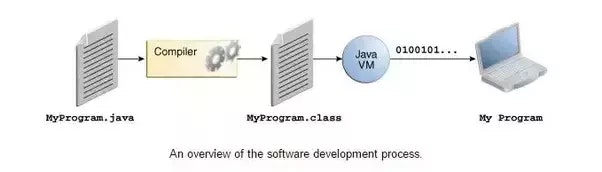
特に注意を払う必要があるのは、.class-> machine codeステップです。このステップでは、jvmクラスローダは最初にバイトコードファイルをロードし、次に実行が比較的遅いインタプリタを通して1行ずつ命令を解釈します。さらに、いくつかのメソッドやコードブロックは、呼ばれることが多いので(ホットスポットコードと呼ばれる)、ランタイムコンパイルであるJITコンパイラはその後導入されました。 JITコンパイラが初めてコンパイルを終了すると、バイトコードに対応するマシンコードが保存され、次回それを直接使用することができます。もちろん、私達は機械語がJavaインタプリタより確かに効率的であることを知っています。これはまた、なぜJavaがコンパイルと解釈と共存する言語であるとよく言われるのかを説明します。
HotSpotはレイジー評価アプローチを使用していますが、2ー8の法則によると、システムリソースの大部分を消費するコード(ホットスポットコード)のごく一部だけが、JITコンパイルが必要なのコードです。 JVMは、コードが毎回実行される方法に基づいて情報を収集し、それに応じていくつかの最適化を行います。そのため、実行回数が多いほど速くなります。 JDK 9ではバイトコードを直接マシンコードにコンパイルする新しいAOT(Ahead of Time Compilation)が導入され、JITウォームアップのオーバーヘッドを回避しています。 JDKは、階層コンパイルとAOTコラボレーションをサポートしています。しかし、AOTコンパイラのコンパイル品質はJITコンパイラに匹敵するものではありません。
概要:Java仮想マシン(JVM)は、Javaバイトコードを実行している仮想マシンです。 JVMは、同じバイトコードを使用して同じ結果を得ることを目的として、異なるシステム(Windows、Linux、macOS)に固有の実装を持っています。さまざまなシステムのバイトコードとJVMの実装は、「一度コンパイルしてどこでも実行できる」というJava言語の鍵です。
JDKとJRE
JDKは、フル機能のJava SDKであるJava Development Kitです。それはJREが持っているすべてのもの、コンパイラ(javac)とツール(javadocやjdbのような)を持っています。プログラムを作成およびコンパイルすることができます。
JREはJavaランタイム環境です。これは、Java仮想マシン(JVM)、Javaクラスライブラリ、javaコマンド、およびその他の基本的な構成要素を含む、コンパイルされたJavaプログラムを実行するために必要なすべてのものの集まりです。ただし、新しいプログラムを作成するために使用することはできません。
Javaプログラムを実行したいだけの場合は、JREをインストールするだけで済みます。 Javaプログラミング作業を行う必要がある場合は、JDKをインストールする必要があります。しかし、これは絶対的なものではありません。コンピュータ上でJava開発を実行する予定がない場合でも、場合によってはまだJDKをインストールする必要があります。たとえば、JSPを使用してWebアプリケーションをデプロイする場合は、技術的にはアプリケーションサーバーでJavaプログラムを実行しているだけです。では、なぜJDKが必要なのでしょうか。アプリケーションサーバーはJSPをJavaサーブレットに変換し、サーブレットをコンパイルするためにJDKを使用する必要があるからです。
4. Oracle JDKとOpenJDKの比較
私のような多くの人は、この問題を見る前にOpenJDKに触れたり使ったりしたことがないでしょう。それでは、OracleとOpenJDKには大きな違いがありますか?私がそれなりの情報を収集したので、多くの人に無視されたこの質問を答えさせてください。
OpenJDKプロジェクトは、主にSunから寄贈されたHotSpotソースコードに基づいています。さらに、OpenJDKがJava 7の参照実装として選択され、Oracleのエンジニアによって保守されています。 JVM、JDK、JRE、およびOpenJDKの違いについては、2012年のOracleブログ投稿でより詳細な回答があります。
Q:OpenJDKリポジトリのソースコードとOracle JDKの構築に使用されたコードの違いは何ですか?
A:非常に近い - Oracle JDKバージョンビルドプロセスはOpenJDK 7に基づいており、OracleのJavaプラグインやJava WebStartの実装を含むデプロイメントコード、そしていくつかのクローズドソースパーティコンポーネントを追加するだけです。例えばグラフィカルラスタライザ、Rhinoなどの一部のオープンソースのサードパーティ製コンポーネント、および添付文書やサードパーティ製のフォントなどの一部の断片的なもの。将来を見据えて、私たちの目標は、ビジネス機能の一部を除いて、Oracle JDKのすべての部分をオーペンすることです。
要約:
- Oracle JDKバージョンは3年ごとにリリースされ、OpenJDKバージョンは3か月ごとにリリースされます。
- OpenJDKは参照モデルであり、完全にオープンソースです。OracleJDKはOpenJDKの実装であり、完全にオープンソースではありません。
- Oracle JDKはOpenJDKよりも安定しています。 OpenJDKとOracle JDKのコードはほぼ同じですが、Oracle JDKにはより多くのクラスといくつかのバグ修正があります。そのため、エンタープライズ/商用ソフトウェアを開発する場合は、Oracle JDKを選択することをお勧めします。これは、徹底的にテストされ安定しているためです。場合によっては、OpenJDKを使用すると多くのアプリケーションがクラッシュする可能性がありますが、問題を解決するにはOracle JDKに切り替えるだけであると言う人もいます。
- Oracle JDKは、応答性とJVMパフォーマンスに関して、OpenJDKよりも優れたパフォーマンスを提供します。
- Oracle JDKは今後のリリースに対する長期的なサポートを提供していないため、ユーザーは最新バージョンに更新することによって毎回最新バージョンのサポートを受ける必要があります。
- Oracle JDKはバイナリコード使用許諾契約に基づいてライセンスされており、OpenJDKはGPL v2ライセンスに基づいてライセンスされています。
5. JavaとC ++の違い
私は多くの人がC ++を学んでいないことを知っていますが、たまに面接で聞かれたことがあります。C ++を学んでいなくても、それを書き留めておく必要があります。
- どちらもカプセル化、継承、およびポリモーフィズムをサポートするオブジェクト指向言語です。
- Javaはメモリに直接アクセスするためのポインタを提供しないので、プログラムメモリはより安全です。
- Javaクラスは単一継承であり、C ++は多重継承をサポートします; Javaクラスは多重継承できませんが、インターフェースはもっと継承できます。
- Javaには、プログラマが未使用のメモリを手動で解放する必要のない自動メモリ管理メカニズムがあります。
6. Javaプログラムのメインクラスとは何ですか?アプリケーションのメインクラスとアプレットの違いは何ですか?
プログラムには複数のクラスが存在できますが、メインクラスは1つのクラスだけです。 Javaアプリケーションでは、このメインクラスはmain()メソッドを含むクラスです。 Javaアプレットでは、このメインクラスはシステムクラスのJAppletまたはAppletから継承したサブクラスです。アプリケーションのメインクラスは必ずしもパブリッククラスである必要はありませんが、アプレットのメインクラスはパブリッククラスである必要があります。メインクラスは、Javaプログラム実行のエントリポイントです。
7. Javaアプリケーションとアプレットの違いは何ですか?
簡単に言うと、アプリケーションはメインスレッド(つまり、main()メソッド)から起動されます。アプレットにはmain方法はありません。主にブラウザページに埋め込まれています(init()スレッドまたはrun()を呼び出して起動します)。ブラウザに埋め込まれたフラッシュゲームに似ています。
8.文字定数と文字列定数の違い
1.正式には、文字定数は一重引用符で囲まれた文字で、文字列定数は二重引用符で囲まれた文字数です。
2.意味は次のとおりです。文字定数は式の演算に使用できる整数値(ASCII値)に相当します文字列定数はアドレス値を表します(文字列はメモリに格納されます)。
3.メモリの大きさ文字定数は2バイトで、文字列定数は数バイト(少なくとも1文字は終了フラグ)を占めます(注:charは2バイトを占めます)。
9.コンストラクタ:Constructorをオーバーライドできるかどうか
継承について話すとき、親クラスのプライベートプロパティとコンストラクタは継承できないので、コンストラクタはオーバーライドできませんが、オーバーロードすることができるので、あるクラスの中で複数のコンストラクタが存在することが可能です。
10.オーバーロードとオーバーライドの違い
**オーバーロード:**同じクラス内で存在し、メソッド名は同じでなければならず、パラメータタイプは異なり、数は異なり、順序は異なります。メソッドの戻り値とアクセス修飾子は異なる可能性があります。
**オーバライド:**親クラスと子クラスで存在し、メソッド名、パラメータリストは同じでなければならず、戻り値の範囲は親クラス以内、スローされる例外の範囲は親クラス以内、アクセス修飾子の範囲は親クラス以上です。クラスメソッドアクセス修飾子がprivateの場合、サブクラスはそのメソッドをオーバーライドできません。
11. Javaのオブジェクト指向プログラミング3つの機能:カプセル化、継承、ポリモーフィズム
カプセル化
カプセル化は、オブジェクトのプロパティを非公開化し、外部からアクセス可能なプロパティのメソッドを提供します。外部からアクセスしたくない場合は、外部アクセス用のメソッドを提供する必要はありません。しかし、クラスが外の世界にアクセスする方法を提供していない場合、このクラスはあまり意味がありません。
継承
継承とは、既存のクラスの定義に基づいて新しいクラスを作成する手法で、新しいデータや新しい関数を追加したり、親クラスの機能を使用したりできますが、親クラスを部分的に選択して継承することはできません。継承を使うことで、コードを非常に便利に再利用できます。
継承について以下の三つのことを覚えておいてください:
1.サブクラスに、親クラスに固有ではないプロパティとメソッドがあります。
2.サブクラスは独自のプロパティとメソッドを持つことができます。つまり、サブクラスは親クラスを拡張できます。
3.サブクラスは独自の方法で親クラスのメソッドを実装できます。 (後で紹介)。
ポリモーフィズム
いわゆる多態性とは、プログラムで定義されている参照変数が指す特定の型とその参照変数によって発行されるメソッド呼び出しが、プログラミング中には決定されず、プログラムの実行中に決定される、つまり参照クラスが指すクラスです。インスタンスオブジェクト、参照変数によって発行されたメソッド呼び出しは、どのクラスに実装されたメソッドであり、プログラムの実行中に決定する必要があります。
Javaには、ポリモーフィックになる可能性がある2つの形式があります。継承(複数のサブクラスが同じメソッドを書き換える)とインタフェース(インタフェースの実装およびインタフェース内の同じメソッドの上書き)です。
12. String StringBufferとStringBuilderの違いは何ですか?なぜStringは不変なのですか?
変動性
簡単に言うと、Stringクラスは文字列を保持するためにfinalキーワードの文字配列 private final char value []を使うので、Stringオブジェクトは不変です。 StringBuilderとStringBufferはどちらもAbstractStringBuilderクラスを継承しています。AbstractStringBuilderでは、文字列は文字列 char [] valueの格納にも使用されますが、finalキーワードでは変更されないので両方のオブジェクトは可変です。
StringBuilderとStringBufferのコンストラクタは、どちらもAbstractStringBuilderによって実装されている親クラスのコンストラクタによって呼び出されます。
AbstractStringBuilder.java
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
int count;
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
スレッドセーフティ
String内のオブジェクトは不変であり、定数およびスレッドセーフとして理解することができます。 AbstractStringBuilderは、StringBuilderとStringBufferの公開親クラスで、expandCapacity、append、insert、indexOfなどの公開メソッドなど、文字列の基本的な操作を定義します。 StringBufferはメソッドや呼び出されたメソッドに同期ロックを追加するため、スレッドセーフです。 StringBuilderは同期ロックをメソッドに追加しないため、スレッドセーフではありません。
パフォーマンス
String型が変更されるたびに、新しいStringオブジェクトが生成され、ポインタは新しいStringオブジェクトを指します。 StringBufferは、新しいオブジェクトを生成したりオブジェクト参照を変更したりするのではなく、毎回StringBufferオブジェクト自体を操作します。同じ状況でStringBuilderを使用しても、StringBufferを使用した場合と比較して10%〜15%のパフォーマンス向上しか達成できませんが、マルチスレッドの不安定さの危険性があります。
3つの使い方のまとめ:
1.少量のデータを操作する= String
2.文字列バッファ内の大量データのシングルスレッド操作= StringBuilder
3.文字列buffer = StringBufferの下にある大量のデータのマルチスレッド操作
13.Autoboxingとunboxing
boxing:基本型をそれに対応する参照型で囲みます。
unboxing:パッケージタイプを基本データタイプに変換します。
14.静的メソッド内で非静的メンバーを呼び出すことが違法なのはなぜですか?
静的メソッドはオブジェクトなしで呼び出すことができるので、静的メソッドでは、他の非静的変数を呼び出したり、非静的変数メンバーにアクセスすることはできません。
15. Javaで何もせず引数も持たないコンストラクタの役割は何でしょう?
Javaプログラムがサブクラスのコンストラクターを実行する前に、super()が親クラス固有のコンストラクターの呼び出しに使用されていない場合は、親クラスの「引数なしのコンストラクター」が呼び出されます。したがって、親クラスでパラメーター付きのコンストラクターのみが定義されていて、子クラスのコンストラクター内で親クラス内の特定のコンストラクターを呼び出すためにsuper()が使用されない場合、Javaプログラムはコンパイル時にエラーになります。引数を持たないコンストラクタが実行のために親クラスで見つかりました。解決策は、親クラスに引数も引数も持たないコンストラクタを追加することです。
16. import: javaとjavaxの違いは何ですか?
当初、JavaAPIが必要とするパッケージはjavaで始まるパッケージでしたが、JavaxはAPIパッケージを拡張するためにのみ使用されていました。ただし、時間が経つにつれて、javaxは徐々に拡張されてJava APIの一部になりました。ただし、拡張機能をjavaxパッケージからjavaパッケージに移動するのは面倒な作業であり、結局既存のコードの大部分を破壊することになります。したがって、javaxパッケージの最終決定は標準APIの一部になります。
したがって、実際には、javaとjavaxは違いはほぼありません。
17.インターフェースと抽象クラスの違いは何ですか?
1.インタフェースのメソッドはデフォルトでパブリックであり、すべてのメソッドはインタフェースに実装できません(Java 8からインタフェースメソッドはデフォルトの実装を持つことができます)、抽象クラスは非抽象メソッドを持つことができます。
2.インタフェース内のインスタンス変数はデフォルトでは最終型ですが、必ずしも抽象クラス内にあるとは限りません。
3.クラスは複数のインタフェースを実装できますが、最大1つの抽象クラスしか実装できません。
4.クラスはインタフェースのすべてのメソッドを実装するためにインタフェースを実装できますが、抽象クラスは必ずしもそうではありません
5.インターフェイスはnewでインスタンス化することはできませんが、宣言することはできます。インターフェイスを実装するオブジェクトを参照する必要があります。デザインパターンのレベルでは、抽象はクラスに対して抽象化、テンプレートデザインであり、インターフェイスは動作の抽象化であり、デザインパターンの一つです。
注:JDK 8では、インターフェースは静的メソッドを定義することもでき、静的メソッドはインターフェース名を使用して直接呼び出すことができます。実装クラスと実装は呼び出しできません。両方のインターフェイスが同時に実装されている場合は、同じデフォルトメソッドがインターフェイスに定義されているため、書き換える必要があります。そうしないとエラーが報告されます。
18.インスタンス変数とローカル変数の違い
1.文法形式から見ると、インスタンス変数はクラスに属し、ローカル変数はメソッドまたはメソッドのパラメータで定義された変数であり、インスタンス変数はpublic、private、staticなどで変更できます。アクセス制御修飾子とstaticによって変更されますが、インスタンス変数とローカル変数の両方をfinalによって変更することができます。
インスタンス変数が staticで変更されていればメンバ変数はクラスに属し、 static修飾子を使わなければインスタンス変数はインスタンスに属します。オブジェクトはヒープメモリに存在し、ローカル変数はスタックメモリに存在します
3.メモリ内の変数の存続時間から。インスタンス変数はオブジェクトの一部であり、オブジェクトの作成とともに存在し、ローカル変数はメソッドの呼び出しで自動的に消えます。
4.インスタンス変数に初期値が割り当てられていない場合:その型のデフォルト値が自動的に割り当てられ(最終的な変更も必要なメンバー変数が割り当てられている必要があります)、ローカル変数は自動的に割り当てられません。
19.オブジェクトを作成するために使用される演算子は何ですか?オブジェクトエンティティとオブジェクト参照の違いは何ですか?
new演算子。newは、オブジェクトインスタンスを作成し(オブジェクトインスタンスはヒープメモリにあります)、オブジェクト参照はオブジェクトインスタンスを指します(オブジェクト参照はスタックメモリに格納されます)。オブジェクト参照は0または1個のオブジェクトを指すことができ(一本のロープはバルーンを付けるとつけない権利がもつ)、オブジェクトはそれをn個の参照を持つことができます(バルーンをn本のロープで結び付けることができます)。
20.メソッドの戻り値とは何ですか?クラスのメソッドにおける戻り値の役割は何ですか?
メソッドの戻り値は、呼び出したメソッドの本体のコードを実行した返す結果です。 (ただし、この方法は戻り値が存在する場合だけ)。戻り値の影響:他の操作に使用できるように結果を受け取ります。
21.クラスのコンストラクタの目的は何ですか?クラスがコンストラクタを宣言しない場合、プログラムは正しく実行できますか?なぜですか?
主な役割は、クラスオブジェクトの初期化を完了することです。実行できます。コンストラクタを宣言しなくても、クラスには引数のないデフォルトのコンストラクタがあります。
22.コンストラクタの特徴は何ですか?
1.名前はクラス名と同じです。
2.戻り値はありませんが、コンストラクタをvoidで宣言することはできません。
3.クラスのオブジェクトが生成されたときに自動的に実行されます。呼び出す必要はありません。
23.静的メソッドとインスタンスメソッドの違いは何ですか?
1.静的メソッドを外部から呼び出す場合は、 "クラス名.メソッド名"メソッドまたは "オブジェクト名.メソッド名"メソッドを使用できます。インスタンスメソッドは後者の方法だけです。つまり、静的メソッドを呼び出すと、オブジェクトを作成する必要がなくなります。
2.静的メソッドは、このクラスのインスタンスにアクセスするときに、静的インスタンスのみ(静的インスタンス変数と静的メソッド)へのアクセスを許可します。インスタンスメンバー変数とインスタンスメソッドへのアクセスは許可しません。インスタンスメソッドはこの制限を持ちません。
24.オブジェクトの一致性とオブジェクトへの参照の一致性の違いは?
オブジェクトが等しいかどうかは、メモリに格納されている内容が等しいかどうかで比較されます。参照が比較するとき、それらが指すメモリアドレスが等しいかどうかで判断します。
25.サブクラスのコンストラクターを呼び出す前に、親クラスのコンストラクターをパラメーターなしで呼び出します。その目的は?
サブクラスが初期設定作業を行うのを助けます。
26. ==と等しい(重要)
==:その目的は、2つのオブジェクトのアドレスが等しいかどうかを判断することです。つまり、2つのオブジェクトが同じオブジェクトかどうかを判断する。 (基本データ型==値比較、参照データ型==メモリアドレス比較)
equals():その役割は二つのオブジェクトが等しいかどうかを決定することです。しかし、それは一般的に2つの用途があります。
- ケース1:クラスはequals()メソッドをオーバーライドしません。クラスの2つのオブジェクトをequals()で比較する場合、2つのオブジェクトを "=="で比較するのと同じです。
- ケース2:クラスはequals()メソッドをオーバーライドします。一般的に、equals()メソッドをオーバーライドして2つのオブジェクトの内容を等しくし、それらの内容が等しい場合はtrueを返します(つまり、2つのオブジェクトは等しいと見なされます)。
例:
public class test1 {
public static void main(String[] args) {
String a = new String("ab"); // a リファレンスは同じ
String b = new String("ab"); // b 内容は同じだが、リファレンスは別
String aa = "ab";
String bb = "ab";
if (aa == bb) // true
System.out.println("aa==bb");
if (a == b) // false,非同一对象
System.out.println("a==b");
if (a.equals(b)) // true
System.out.println("aEQb");
if (42 == 42.0) { // true
System.out.println("true");
}
}
}
注:
- objectのequalsメソッドは比較されるオブジェクトのメモリアドレスであり、Stringのequalsメソッドはオブジェクトの値を比較するため、Stringのequalsメソッドはオーバーライドされます。
- String型のオブジェクトを作成するとき、仮想マシンは作成される値と同じ値を持つオブジェクトの存在を定数プールで調べ、存在する場合はそれを現在の参照に割り当てます。そうでない場合は、定数プールにStringオブジェクトを再作成します。
27. hashCodeと等しい(重要)
面接官は私達に尋ねるかもしれません: "あなたはhashcodeとequalsを書き換えましたか?、equalsを書き換えるときなぜhashCodeメソッドをオーバーライドしなければならないのですか?"
hashCode()はじめに
hashCode()の目的は、ハッシュコードとも呼ばれるハッシュコードを取得することであり、実際にはint整数を返します。このハッシュコードの目的は、ハッシュテーブル内のオブジェクトのインデックス位置を決定することです。 hashCode()はJDKのObject.javaで定義されています。つまり、JavaのすべてのクラスにhashCode()関数が含まれています。
ハッシュテーブルは、キーと値のペアを格納します。これは、「キー」に基づいて対応する「値」をすばやく取得する機能によって特徴付けられます。このときにハッシュコードがつかわれています。 (すぐに必要なオブジェクトを見つけることができます)
なぜhashCodeが必要ですか?
ハッシュコードが含まれる理由を説明するために、例「HashSetとの重複チェック方法」を使用します。
HashSetにオブジェクトを追加すると、HashSetは最初にそのオブジェクトのハッシュコード値を計算して、そのオブジェクトが追加された場所を判断します。また、既に追加されている他のオブジェクトのハッシュコード値を比較します。しかし、同じハッシュコード値を持つオブジェクトが見つかった場合は、equals()メソッドが呼び出され、同じハッシュコードを持つオブジェクトが実際に同じかどうかがチェックされます。両者が同じ場合、HashSetは追加操作を成功させません。異なる場合は、別の場所にハッシュされます。 これにより、equalsの数が大幅に減り、実行速度が大幅に向上します。
hashCode()およびequals()
- 2つのオブジェクトが等しい場合、ハッシュコードは同じでなければなりません
- 2つのオブジェクトは等しいので、equalsメソッドを呼び出して両方のオブジェクトに対してtrueを返します。
- 2つのオブジェクトは同じハッシュコード値を持ち、必ずしも等しいとは限りません。
4.したがって、equalsメソッドをオーバーライドする場合は、hashCodeメソッドもオーバーライドする必要があります** - hashCode()のデフォルトの動作は、ヒープ上のオブジェクトに固有の値を生成することです。 hashCode()がオーバーライドされていない場合、クラスの2つのオブジェクトは、たとえ2つのオブジェクトが同じデータを指していても、等しくなりません。
28.なぜJavaでは値が渡されるだけなのですか?
29.スレッド、プログラム、プロセスの基本概念を簡単に説明 それらの間の関係は何ですか?
スレッドはプロセスに似ていますが、スレッドはプロセスよりも小さい実行単位です。プロセスは実行中に複数のスレッドを生成できます。プロセスとは異なり、同じ種類の複数のスレッドが同じメモリ空間と一連のシステムリソースを共有するため、システムがスレッドを生成したりスレッド間で切り替えたりする場合、その負荷はプロセスよりはるかに小さくなります。そのため、スレッドは軽量プロセスとも呼ばれます。
プログラムは、ディスクまたは他のデータ記憶装置に格納されている命令とデータを含むファイルです。つまり、プログラムは静的コードです。
プロセスは、プログラムを実行するシステムの基本単位であるプログラムの実行プロセスであるため、プロセスは動的です。システム内でプログラムを実行することは、作成から実行、消滅までのプロセスのプロセスです。簡単に言えば、プロセスはコンピュータ内で1つの命令と1つの命令で実行される実行プログラムであると同時に、各プロセスもCPU時間、メモリ空間、ファイル、ファイル、入出力などの特定のシステムリソースを占有します。つまり、プログラムが実行されると、オペレーティングシステムによってメモリにロードされます。
スレッドは、プロセスが分割された小さな操作単位です。スレッドとプロセスの最大の違いは、基本的に各プロセスは独立しており、各スレッドは必ずしも同じではないということです。これは、同じプロセス内のスレッドが互いに影響を与える可能性が非常に高いためです。別の観点から見ると、プロセスはオペレーティングシステムの範囲に属し、主に同じ期間に同時に複数のプログラムを実行できますが、スレッドは同じプログラム内で複数のプログラムセグメントをほぼ同時に実行します。
30.スレッドの基本的な状態は何ですか?
Javaスレッドは、実行のライフサイクル内の指定された時点で、次の6つの異なる状態のうちの1つでなければならないです。
スレッドはライフサイクルの特定の状態に固定されているのではなく、コードの実行時に異なる状態間で切り替えられます。 Javaスレッドの状態遷移を次の図に示します。
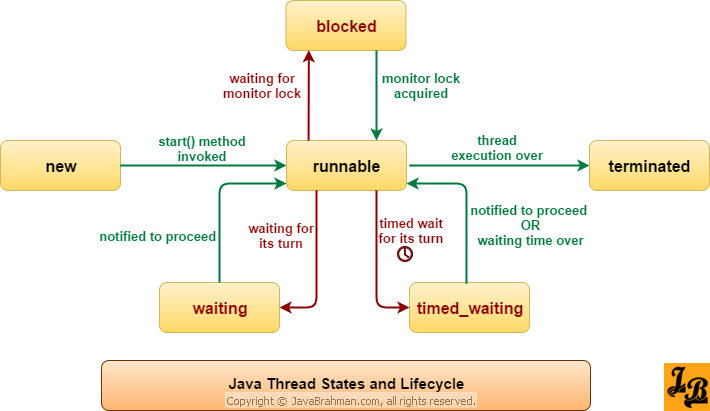
上の図からわかるように:
スレッドが作成されると、スレッドは** NEW(new)状態になり、 start()メソッドが呼び出されて実行が開始され、スレッドは READY 状態になります。実行可能状態のスレッドは、cpuタイムスライスを取得した後、 RUNNING **状態になります。
オペレーティングシステムは、RUNNABLE状態だけを見るJava仮想マシン(JVM)内のRUNNABLE状態とRUNNING状態を隠します(出典:[HowToDoInJava](https://howtodoinjava.com/):[Javaスレッドライフサイクルとスレッド状態] ](https://howtodoinjava.com/java/multi-threading/java-thread-life-cycle-and-thread-states/))したがって、Javaシステムは一般的にこれら2つの状態を** RUNNABLE(実行中)と呼びます。 )**ステータス。

スレッドが wait()メソッドを実行すると、スレッドは** WAITING状態に入ります。待機状態に入るスレッドは、実行状態に戻ることができるように他のスレッドからの通知に頼る必要があります。一方、** TIME_WAITING(timeout wait)状態は、 sleep(long millis)のように、待機状態に基づくタイムアウト制限を追加することと同じです。 methodまたはwait(long millis)メソッドはJavaスレッドをTIMED WAITING状態にします。タイムアウト期間になると、JavaスレッドはRUNNABLE状態に戻ります。スレッドが同期メソッドを呼び出すと、スレッドはロックを取得せずに BLOCKED 状態に入ります。 Runnableの run()メソッドを実行した後、スレッドは TERMINATED状態に入ります。
31 finalキーワードの概要
finalキーワードは主に3つの場所で使用されます:変数、メソッド、クラス。
1.最終変数の場合、それが基本データ型の変数である場合、その値は初期化されると変更できないです。参照型の変数である場合は、初期化後に別のオブジェクトを指すことはできません。
2.finalを使ってクラスをファイナライズするときは、そのクラスを継承できないことを示します。 finalクラスのすべてのインスタンスメソッドは暗黙的にfinalメソッドとして指定されています。
3.finalをメソッドに使用する理由は2つあります。 1つ目の理由は、継承クラスがその意味を変更する場合に備えてメソッドをロックすることです。2つ目の理由は効率性です。初期のバージョンのJava実装では、finalを付けるメソッドはインライン呼び出しに変換されました。しかし、メソッドが大きすぎると、インライン呼び出しによるパフォーマンスの向上は見られないかもしれません(現在のJavaバージョンでは、これらの最適化のためのメソッドにfinalをつかうのは必要ありません)。クラス内のすべてのプライベートメソッドは暗黙的にfinalとして指定されています。
32 Javaにおける例外処理
Java例外クラスの階層図
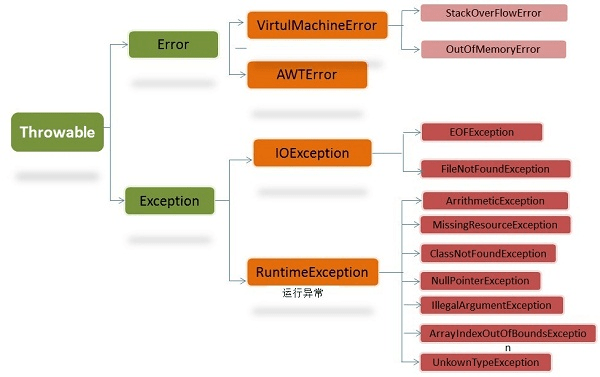
Javaでは、すべての例外は共通の先祖java.langパッケージThrowableクラスを持ちます。
Throwable:ExceptionとErrorの2つの重要なサブクラスがあります。どちらもJava例外処理の重要なサブクラスで、それぞれに多数のサブクラスが含まれています。
エラー:プログラムが処理できないエラー。アプリケーションの実行におけるより深刻な問題を示しています。ほとんどのエラーはコードライターによって実行されるアクションとは関係ありませんが、実行時のJVM(Java Virtual Machine)に関する問題を表しています。たとえば、Java仮想マシンがバグ(Virtual MachineError)を実行し、OutOfMemoryErrorが発生した場合は、JVMに操作を続行するために必要なメモリリソースがなくなったときです。これらの例外が発生すると、Java仮想マシン(JVM)は通常スレッドの終了を選択します。
これらのエラーは、仮想マシン自体で障害が発生したこと、または仮想マシンがアプリケーションを実行しようとしたときに、Java仮想マシンエラー(Virtual MachineError)、クラス定義エラー(NoClassDefFoundError)などが発生したことを示します。これらのエラーは、アプリケーションの制御および処理能力の範囲外であるため検出できません。また、プログラムの実行中はほとんどのエラーが許可されません。うまく設計されたアプリケーションでは、たとえエラーが発生したとしても、本質的にそれによって引き起こされた異常を処理しようとするべきではありません。 Javaでは、エラーはErrorのサブクラスによって記述されます。
例外:プログラム自体が処理できる例外。 Exceptionクラスには、重要なサブクラスRuntimeExceptionがあります。 RuntimeException例外は、Java仮想マシンによってスローされます。NullPointerException(アクセスする変数がどのオブジェクトも参照していない場合は例外がスローされる)、ArithmeticException(整数を0で除算した場合は例外をスローする)およびArrayIndexOutOfBoundsException (インデックスは範囲外の異常です)。
注:例外とエラーの違い:例外はプログラム自体で処理できるが、エラーは処理できません。
Throwableクラスの共通メソッド
- public string getMessage():例外発生時の詳細を返します
- public string toString():例外が発生したときの簡単な説明を返す
- public string getLocalizedMessage():例外オブジェクトの地域対応情報を返します。 Throwableのサブクラスでこのメソッドをオーバーライドすると、ローカライゼーション情報を要求することができます。サブクラスがメソッドをオーバーライドしない場合、メソッドはgetMessage()によって返される結果と同じ情報を返します。
- public void printStackTrace():Throwableオブジェクトのカプセル化に関する例外情報をコンソールに出力する
例外処理のまとめ
- **try block:**は例外を捕捉するために使用されます。キャッチブロックがない場合は、最後にfinallyブロックを続けなければなりません。
- **catchブロック:**はtryによって捕捉された例外を処理するために使用されます。
- finallyブロック: finallyブロック内のステートメントは、例外が捕捉されたか処理されたかにかかわらず実行されます。 tryブロックまたはcatchブロックでreturn文が見つかった場合は、メソッドが戻る前にfinallyブロックが実行されます。
以下の4つの特別な場合、finallyブロックは実行されません。
- finallyステートメントブロックの最初の行で例外が発生しました。他の行では、finallyブロックはまだ実行されるためです。
2.プログラムは、前のコードでSystem.exit(int)で終了しました。 exitはパラメータ関数で、ステートメントが例外ステートメントの後にある場合は、最後に実行されます。
3.プログラムが配置されているスレッドが停止しています。 - CPUをオフにします。
戻り値について:
try文に戻り値がある場合は、tryブロック内の変数の値が返されます。
詳細な実行プロセスは以下のとおりです。
1.戻り値がある場合は、戻り値をローカル変数に保存します。
2.実行するfinally文にジャンプするためにjsr命令を実行します。
3. finallyステートメントを実行した後、以前にローカル変数テーブルに保存された値を返します。
4. try、finallyステートメントにリターンがある場合は、tryのリターンを無視し、finallyのリターンを使用します。
33 Javaの直列化に直列化したくないフィールドがある場合、どうすればいいですか?
直列化したくない変数には、transientキーワード修飾子を使用します。
transientキーワードの目的は、インスタンス内でこのキーワードによって変更された変数の直列化を防ぐことです。オブジェクトが逆シリアル化されると、transientによって変更された変数の値は永続化され復元されません。トランジェントは変数のみを変更でき、クラスやメソッドは変更できません。
34キーボードを使って一般的に使われる入力の方法を2つまとめます。
方法1:Scanner
Scanner input = new Scanner(System.in);
String s = input.nextLine();
input.close();
方法2:BufferedReader
BufferedReader input = new BufferedReader(new InputStreamReader(System.in));
String s = input.readLine();