大学でディープラーニングによる動画のフレーム補間を扱っており、その過程で試している実装をアウトプットします。
これからも動画のフレーム補間の実装の続きを投稿していくので、もしよければLGTM&フォローお願いします。
今回やったことは、実際の動画フレームを用いて前後6フレームから中間1フレームを生成するネットワークの構築です。
実装環境
Google Colab
https://colab.research.google.com/notebooks/welcome.ipynb?hl=ja
実装概要
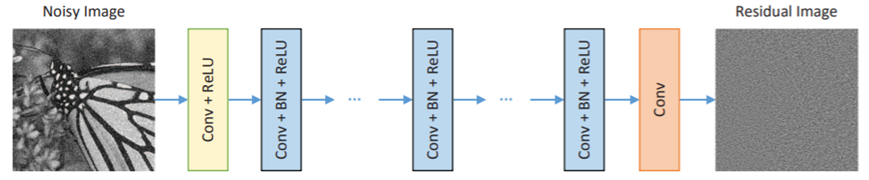
**前後フレーム(前3・後3)から中間フレームを生成するディープラーニング。**ネットワークはDnCNN[1]です。手近にこのネットワークがあったので使用しています。
([1] Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang, “Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising”, https://arxiv.org/abs/1608.03981)

DnCNNのネットワークは次の通りです。本来はノイズ除去を目的としたものです。
入力について、フレームサイズは16090、チャネル数は18チャネル(6フレームRBG)です。
出力について、フレームサイズは同様で、チャネル数は3チャネルです。
青色の中間層のパラメータをいじりました。
層数15、カーネルサイズ3*3、チャネル数72となっています。
データセット
街を撮影したMOT17を使いました。
https://motchallenge.net/
セット数は、train 1320, test 1285 です。
結果
1つ目の画像は、上から前2フレーム、生成した中間フレーム、後2フレームとなります。実際にはもう1フレームずつ入力がありますが、画像が小さくなってしまうので省略しました。

次の画像は、正解の中間フレームとの比較です。

前後に引っ張られていたり、色が変化していたりと、補間できているとは全然言えない結果ですね。
性能評価
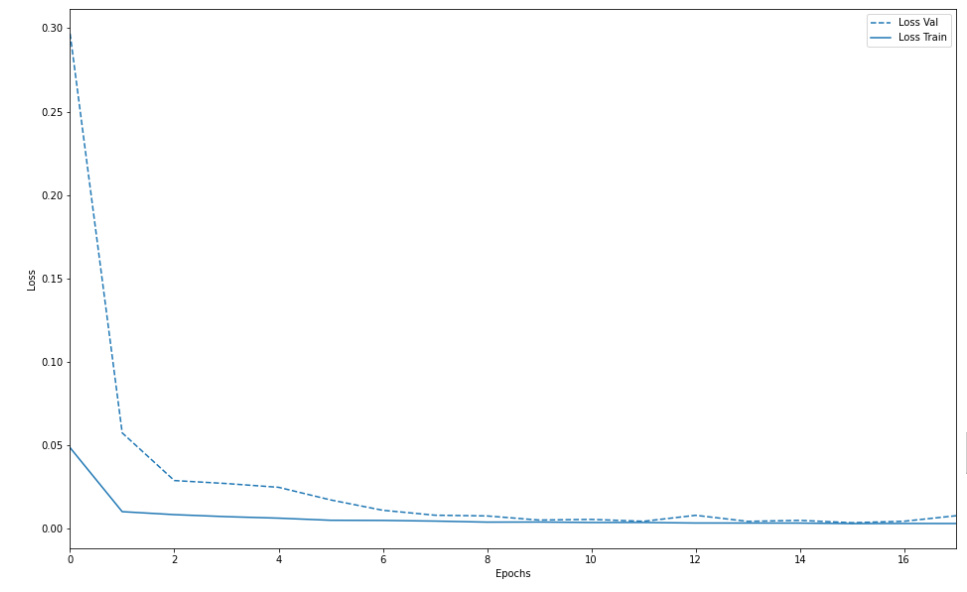
汎化性能のグラフはこちら。近い値を取っているので、ここは問題ないと思われる。
損失値等の数値データはこちら。
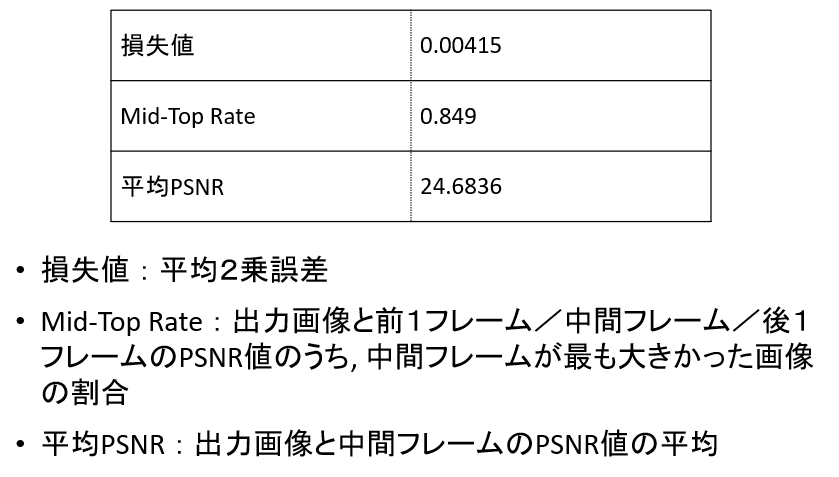
数値上、そこまで悪い値ではない印象です。以前に1画像をトリミングして疑似的なフレーム補間を行ったときの損失値と平均PSNRに近いです。しかし、これは前後画像がほぼ同じ画像であるためと思われます。mid-top rateは低くなっているので、ここを上げる必要があります。
考察
補間できていない理由として、
・データセット数の少なさ
・入力6フレームがうまく機能していない
・ネットワーク(DnCNN)の問題
の3点だと考えています。
訓練・テストデータともに1300セットほどです。元の画像数は多いのですが、1セットで7フレーム消費するのでなかなか量が稼げないです。自作データセットを今作っている最中なので、データセット数に気を付けながら進めたいと思います。
入力6フレームはどうなのでしょうか。。どの論文見ても前後2フレームで補間を行っているので、このまま6フレームでやり続けてうまくいくのか心配です。比較のためにも2フレームに戻したほうがいいと思い始めました。
今後の方針
・自作データセットでセット数を増やす。
※ハイスピードカメラによるデータセット。このデータセットを使って精度が向上するかが研究の目的です。
・入力フレーム数を何枚にするか検証。
・別のネットワークでの検証。
最後に
最後まで読んでいただきありがとうございました。
改善点等ありましたら遠慮なくご指摘ください。
これからもこの系統の投稿をしていくので、よければLGTM&フォローお願いします!