Alexaにデバイス(Echo)に登録されている住所、郵便番号、国を取得できる Device Address API が追加されました。
これによって、ユーザーがSkillを実行したデバイスに紐付いている位置情報(住所、郵便番号、国)をSkill側から取得できるようになりました。
今までは郵便番号しか持っていなかったため、細かい位置を知る方法はありませんでしたが、これで個々のSkillで住所を質問するようなIntentを用意する必要がなくなったかと思います。
Echoに住所を紐付ける
住所の情報を取得する場合は、事前にユーザーがAlexa Appでデバイスに住所情報を登録している必要があります。
Alexa Appを開いて、SettingsのDevicesから登録するデバイスを選択します。
http://alexa.amazon.com/spa/index.html#cards
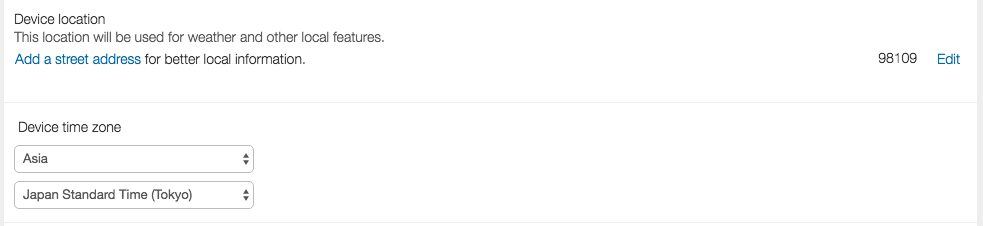
デフォルトの状態だと郵便番号だけが登録されている状態ですので、右側のEditをクリックして入力していきます。
入力した住所に合う候補があると選択することが出来きます。
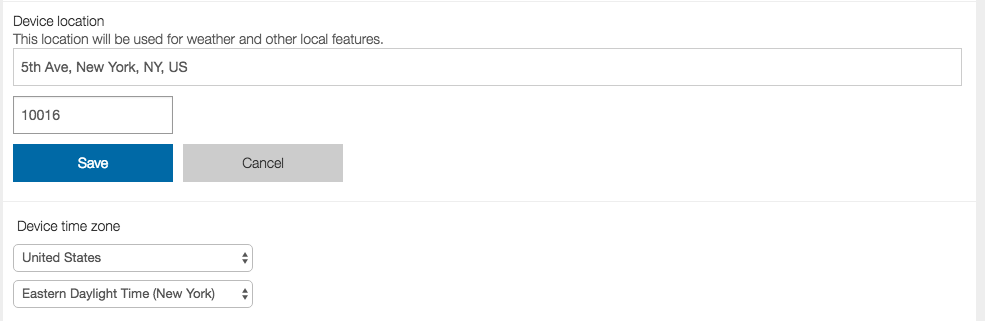
試しにエンパイア・ステート・ビルのの住所を入れてみました。
デバイスの位置情報を取得するSkillを作成
AmazonのデベロッパーコンソールからSkillの一覧を表示して、Add a New Skillをクリックして新規で追加します。
https://developer.amazon.com/edw/home.html#/skills
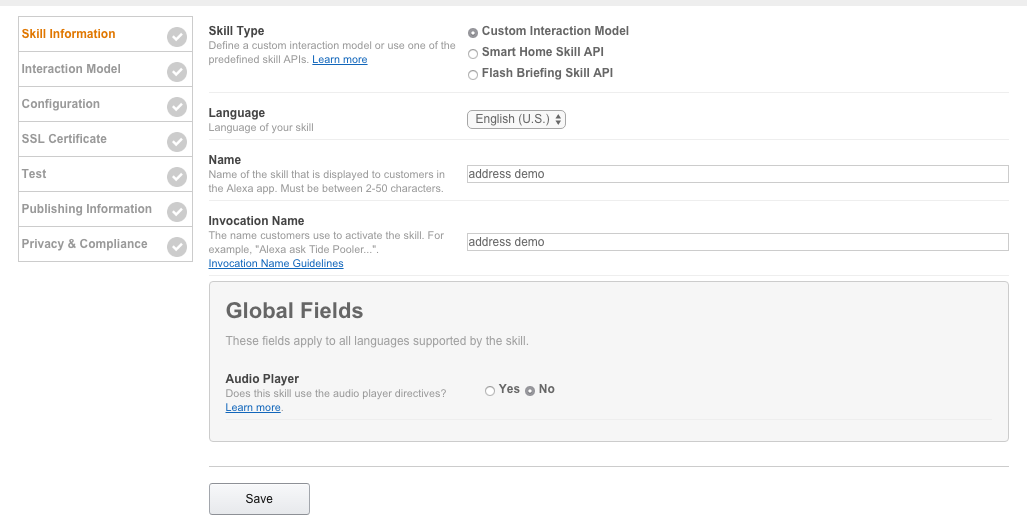
カスタムSkillを選択し、適当な名前を付けます。
この例では Invocation Nameをaddress demoとして登録しました。
Configurationの所に今回試す、Permissionsが追加されているので、Device Addressにチェックを付けてFull Addressを選びます。
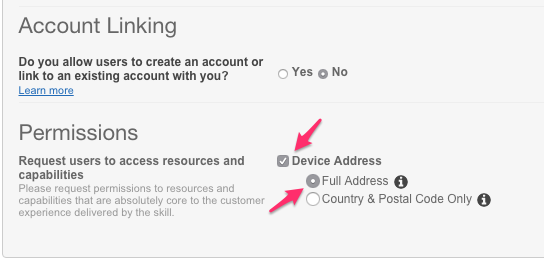
注意)
ここで許可した情報を返すエンドポイントしか利用することが出来ません。
FullAddressを許可したとしても、国、郵便番号のエンドポイントを叩いた場合、403 Forbiddenになります。
Skillの実装
デバイスに紐付けられた住所はSkillに送られてくるわけではなく、送られてきた情報を元に別のAPIを叩いて取得する必要があります。
Alexaから送られてくるJSONは以下のような物
{
"session": {
"new": true,
"sessionId": "some session id",
"user": {
"userId": "amzn1.ask.account.some_user_id",
"permissions": {
"consentToken": "some_token"
}
},
"application": {
"applicationId": "amzn1.ask.skill.some_app_id"
}
},
"version": "1.0",
"request": {
"locale": "en-US",
"timestamp": "2017-04-08T05:52:11Z",
"type": "LaunchRequest",
"requestId": "amzn1.echo-api.request.some_request_id"
},
"context": {
"AudioPlayer": {
"playerActivity": "IDLE"
},
"System": {
"device": {
"deviceId": "amzn1.ask.device.some_device_id",
"supportedInterfaces": {
"AudioPlayer": {}
}
},
"application": {
"applicationId": "amzn1.ask.skill.some_app_id"
},
"user": {
"userId": "amzn1.ask.account.some_user_id",
"permissions": {
"consentToken": "some_token"
}
},
"apiEndpoint": "https://api.amazonalexa.com"
}
}
}
このJSONの中の 以下の項目を利用します
| JSONのキー | 意味 |
|---|---|
| context.System.device.deviceId | device id |
| context.System.user.permissions.consentToken | token |
| context.System.apiEndpoint | api endpoint |
住所全部を取得
この情報を取得する場合のエンドポイントは以下の通りとなっています。
/v1/devices/{deviceId}/settings/address
これで、echosimから Open address demo と話しかけると、取得した住所を答えてくれます。
APIを叩いて取得できたJSONはこんな情報
{
"addressLine1": "5th Ave",
"addressLine2": null,
"addressLine3": null,
"districtOrCounty": "New York",
"stateOrRegion": "NY",
"city": "New York",
"countryCode": "US",
"postalCode": "10016"
}
カードの表示
ユーザーが住所の提供を許可していない場合は、AlexaからのリクエストにconsentTokenが含まれてきません。
そのような場合は、パーミッションを許可してねってカードが新たに用意されたので、Alexaに返すJSONにそのカードを指定してあげます。
'card': {
'type': 'AskForPermissionsConsent',
'permissions': [
'read::alexa:device:all:address'
]
}
国と郵便番号だけの場合は、read::alexa:device:all:address:country_and_postal_codeをpermissionsに指定します。
こんな感じでAlexa Appにカードが表示されます。
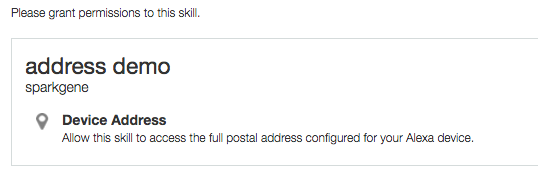
サンプルソース
# -*- coding: utf-8 -*-
from __future__ import print_function
import os
import json
import urllib2
def describe_device_address(api_host, device_id, access_token):
req = urllib2.Request("{}/v1/devices/{}/settings/address".format(api_host, device_id))
req.add_header("Authorization", "Bearer {}".format(access_token))
response = urllib2.urlopen(req)
if response.getcode() == 200:
return json.loads(response.read())
else:
print(response.getcode())
raise Exception(response.msg)
def lambda_handler(event, context):
print(event)
api_host = event["context"]["System"]["apiEndpoint"]
device_id = event["context"]["System"]["device"]["deviceId"]
token = event["context"]["System"]["user"]["permissions"]["consentToken"]
address = describe_device_address(api_host, device_id, token)
print(address)
speech_output = "country is {0}. zipcode is {1}. Address is {2} {3} {4} ".format(
address["countryCode"],
address["postalCode"],
address["addressLine1"],
address["city"],
address["stateOrRegion"]
)
response = build_response(build_speechlet_response(speech_output))
return response
def build_speechlet_response(output):
title = 'Address Demo'
return {
'outputSpeech': {
'type': 'PlainText',
'text': output
},
'card': {
'type': 'AskForPermissionsConsent',
'permissions': [
'read::alexa:device:all:address'
]
},
'reprompt': {
'outputSpeech': {
'type': 'PlainText',
'text': title
}
},
'shouldEndSession': True
}
def build_response(speechlet_response):
return {
'version': '1.0',
'response': speechlet_response
}