pythonでThreadingをプログラミングするには。まずThreadingとはなにかを知らないといけませんね。このWEBには詳しい説明がありここの少し貼り付けます。
「スレッド(thread)」は英語で「糸」の意味がありますが、一本に連なった「議論の道筋」といった意味も持っています。掲示板などで特定テーマで続く一連の議論の流れも「スレッド」と呼ばれます。
同じようにパソコンのプログラムでも、一連の命令が順番に処理されていく流れ(最小の処理単位)のことを「スレッド」と呼びます。
プログラムを効率よくするため、複数のスレッドに分け、同時に処理できるようにしたのが「マルチスレッド」ということになります。
もっと詳しく知りたいのなら↓
https://www.724685.com/word/wd110126.htm
ではまず以下のScriptをみてみよう。あまり難しいこと書いていませんが、timeモジュールをImportし、その中にあるperf_counter()のメソッドで経過時間を測定し、最後は時間をマイナスして実際の実行時間を計算できます。Scriptの中にdo_something()で1秒を待ち機能があります。
import time
start=time.perf_counter()
def do_something():
print('sleeping 1 s..')
time.sleep(1)
print('Wake up!')
do_something()
do_something()
finish=time.perf_counter()
print('finish on {}'.format(finish-start))
では結果はどうになる?言わなくてもわかると思いますが、実行→1秒待ち→終わり
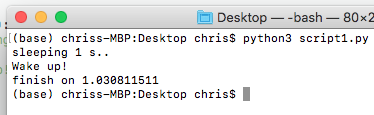
もしこのdo_something()2回を実行したらどうになる?もちろん、実行→1秒待ち→次の実行→1秒待ち→終わり。って感じですね。Time Chatを書いてみましょう。つまりこのdo_something()を2回実行するのに最低限2秒かかります。そしてこの1秒待ってるの間にCPUがなにもせずずっとSleepするだけ。
順次でFunctionを実行するのは同期といいます。英語は”Synchronously”です。
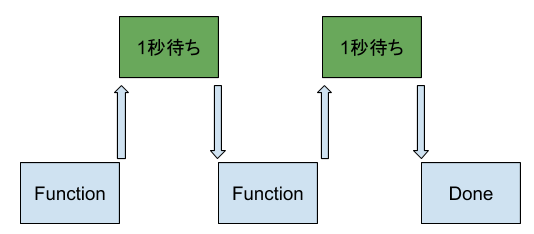
なんとなく効率悪いねーと思いませんか?ここの2つの概念を紹介したいと思います。
CPU Bound TaskとIO Bound Taskです。
- CPU Bound Task:計算などたくさんしCPUに負荷をかけるプログラムです。
- IO Bound Task:いわゆるInput/Outputのオペレーション完成を待ちのプログラム、ネットワークとかFile SystemのFile書き読みなど、CPUにに負荷をそんなにかけないプログラムです。
問題なのはいつもThreadingを使えばええじゃう?と思いませんか?実はそうではありません。ThreadingはIO Bound Taskに対してそういう待ちのオペレーションがメリットがありますが、CPU Bound TaskにThreadingを使うと逆に遅くなる恐れがあります。そういうときはMult-Processingを使うほうがよいでしょう。
もっと詳しく知りたいのなら↓
https://yohei-a.hatenablog.jp/entry/20120205/1328432481
ここでTreadingのコードをみてみよう。ここで注意するにはjoin()はLoopingの中に使えないこと。
import threading
import time
start=time.perf_counter()
def do_something():
print('Sleeping 1 s')
time.sleep(1)
print('Wake up!')
'''
create threading,target is the function that you want to run
'''
t1=threading.Thread(target=do_something)
t2=threading.Thread(target=do_something)
'''
start the threading
'''
t1.start()
t2.start()
'''
make sure that they complete before moving on to calculate the
finish time
'''
t1.join()
t2.join()
finish=time.perf_counter()
print('Finish time:{}'.format(finish-start))
実行結果はこうになります:
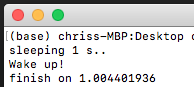
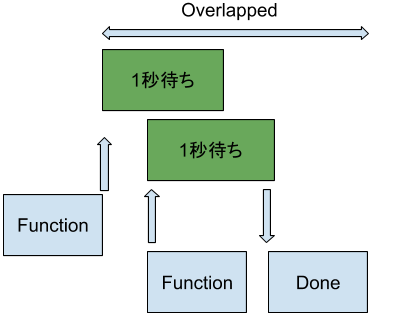
Threadingは本当にコードを同時に実行するようにみえますが、実際は以下のTime Chatのようになります。Functionが待ちポイントになるとコードがもっと前に進め他のコードを実行する。
もしdo_something()を10回実行したいならどうになります?CopyとPasteしてするよりLoopingでやったほうが楽じゃないかな?
import threading
import time
start=time.perf_counter()
def do_something():
print('Sleeping 1 s')
time.sleep(1)
print('Wake up!')
threads=[]
for _ in range(10):
t=threading.Thread(target=do_something)
t.start()
threads.append(t)
for thread in threads:
thread.join()
finish=time.perf_counter()
print("finished at{}".format(finish-start))
結果はこうになります:
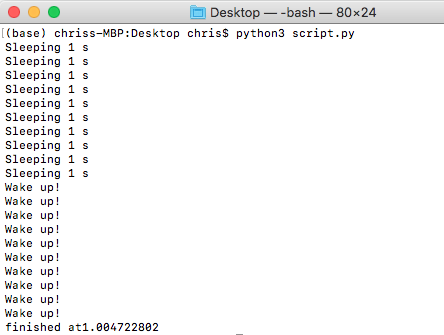
いままでのFunctionにパラメータなにPassしてないが、今度Sleepの秒数をPassしてみましょう。
import threading
import time
start=time.perf_counter()
def do_something(second):
print('Sleeping {} s'.format(second))
time.sleep(second)
print('Wake up!')
threads=[]
for _ in range(10):
t=threading.Thread(target=do_something,args=[1.5])
t.start()
threads.append(t)
for thread in threads:
thread.join()
finish=time.perf_counter()
print("finished at{}".format(finish-start))
実行結果はこうになります:
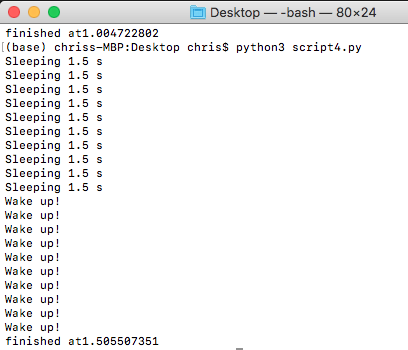
Python3.2からThread pool executorがありまして、それによってもっと簡単で効率的にThreadingを走ることができますし、Taskの状態も調べることができます。
import concurrent.futures
import time
start=time.perf_counter()
def do_something(second):
print('Sleeping {} s'.format(second))
time.sleep(second)
return 'Wake up!'
with concurrent.futures.ThreadPoolExecutor() as executor:
#execute the function 1 time
f1=executor.submit(do_something,1)
f2=executor.submit(do_something,1)
#wait around until the function completes
print(f1.result())
print(f2.result())
finish=time.perf_counter()
print("finished at{}".format(finish-start))
今回はThread pool executorをLoopingしてみますね。
import concurrent.futures
import time
start=time.perf_counter()
def do_something(second):
print('Sleeping {} s'.format(second))
time.sleep(second)
return 'Wake up!'
with concurrent.futures.ThreadPoolExecutor() as executor:
results=[executor.submit(do_something,1) for _ in range(10) ]
for f in concurrent.futures.as_completed(results):
print(f.result())
# get a iterator that we can loop over that will yield the result
# of our threads as they are completed
finish=time.perf_counter()
print("finished at{}".format(finish-start))
結果はこうになります:
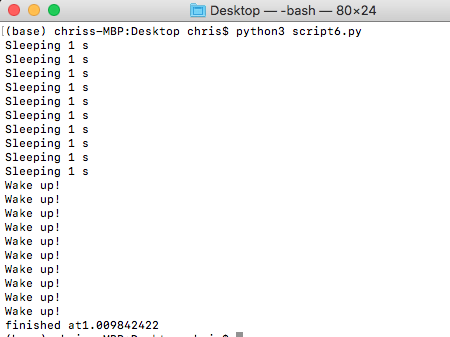
次はまたそれぞれSleepingをいれますね。
import concurrent.futures
import time
start=time.perf_counter()
def do_something(second):
print('Sleeping {} s'.format(second))
time.sleep(second)
return 'Wake up!{}'.format(second)
with concurrent.futures.ThreadPoolExecutor() as executor:
sleep_time=[5,4,3,2,1]
results=[executor.submit(do_something,s) for s in sleep_time ]
for f in concurrent.futures.as_completed(results):
print(f.result())
# get a iterator that we can loop over that will yield the result
# of our threads as they are completed
finish=time.perf_counter()
print("finished at{}".format(finish-start))
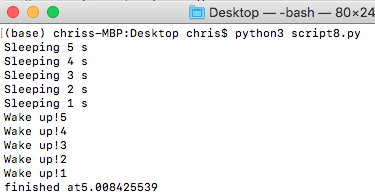
結果はこうになります:
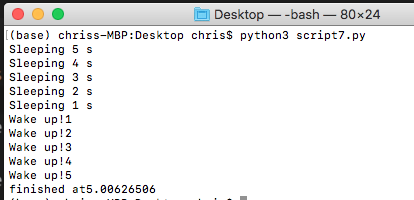
最後はMap()をつかってみましょう。
import concurrent.futures
import time
start=time.perf_counter()
def do_something(second):
print('Sleeping {} s'.format(second))
time.sleep(second)
return 'Wake up!{}'.format(second)
with concurrent.futures.ThreadPoolExecutor() as executor:
sleep_time=[5,4,3,2,1]
results=executor.map(do_something,sleep_time)
for result in results:
print(result)
# get a iterator that we can loop over that will yield the result
# of our threads as they are completed
finish=time.perf_counter()
print("finished at{}".format(finish-start))
結果はこうになりますね:注意するのはこのScript走ったとき5秒くらい待たないといけないこと気がつきましたか?Mapを使うには結果は初StartのThreadingが結果くる前にResult来れませんー
それじゃねー