以下記事は古いバージョンでの動作でした。
numba=0.60.0では常に並列動作するようです。
この記事は一応残していますが、いずれ消すと思います。
Numbaで並列を使おうとして、色々難しかった話
自分用のメモです
他の記事でNumbaで並列を使おうとした際に、シングルスレッドのコードをそのまま使おうとすると、なかなかよくわからない結果になってしまった。
ので、その際に色々検討した結果を自分用のメモとして書いておく
もっといいやり方が絶対あると思うので、誰かに教えて欲しいなあと思ふ。
なお環境は、M1macbookair,16Gbメモリ,
python=3.10.13 , numba=0.57.1 , numpy=1.24.4
なお、これを書いているのはpythonに触れて1.5年くらいの初学者です。
やりたいこと
各データでscoreを取って、それが高い上位100個を保存したいような用途で、マルチスレッドをするとき、上書き問題に直面した。こんなことが並列でしたい
-
func_score(i)でスコアを取得 - 上位100個を保存したい
return_list=np.full((n,2),-1)
for i in range(n):
score=func_score(i)
return_list[i]=np.array([i,score])
return_list[np.argsort(return_list[:,1])]
別に、以下のようにすれば単純に並列化可能
-
range(n)→prange(n)
return_list=np.full((n,2),-1)
for i in prange(n):
score=func_score(i)
return_list[i]=np.array([i,score])
return_list[np.argsort(return_list[:,1])]
のちにわかるがこれは、代入を1箇所に1回しか行わないため。
ただし、これはものすごい回数計算する場合には不向き。
return_list=np.full((n,2),-1)は多分float64になるが、計算回数$\times 2\times 8$byteが必要になる。
他の記事に書いたが、自分は200億回計算をしなければならなかったため、メモリで320 Gbyte必要になる。
ん〜〜ムリ! 俺のM1は8Gbyte !
なので、1回1回sortしてreturn_listに上書きし、メモリの圧迫を解消する必要があった(メモリがあるならしない方が早い、多分)。
- 1回1回sortして
return_listに上書き -
howsaveは何個保存するか、
howsave=100
return_list=np.full((howsave,2),-1)
for i in prange(n):
score=func_score(i)
min_index=np.argmin(return_list[:,1])
return_list[min_index]=np.array([i,score])
return_list[np.argsort(return_list[:,1])]
こんなふうにすればできると思ったら、実行するごとに結果が変わる。
本当にマルチルレッドになってる??
結果を見ていると、極小規模ではうまくいくのに大きくするとダメになることがあった。
ので、計算の重さを変えて結果を見てみる。
本当はsleep()とかがあれば良かったが、numbaでは使えないので、フィボナッチ数列の計算で負荷を変えている。
(for文だらけで汚いけど負荷による違いを見たいだけなので、、、)
from numba import njit,prange,set_num_threads,get_thread_id,get_num_threads
import numpy as np
@njit()
def fibo(n):
a, b = 0, 1
fibolist=np.zeros(n)
for i in range(n):
a, b = b, a+b
fibolist[i]=a
@njit(parallel=True)
def core_check(n,weight,num_threads=get_num_threads()):
set_num_threads(int(num_threads))
num_threads=get_num_threads()
for_ans=np.full(n,-1)
for i in prange(n):
for j in range(weight):
fibo(10000)
for_ans[i]=int(get_thread_id())
return_list=np.full(num_threads,-1)
for i in range(num_threads):
return_list[i]=np.sum(for_ans==i)
return return_list
フィボナッチ数列10000回を一巡として、何回繰り返すかで負荷を調整。
フィボナッチ数列中で謎の代入をしているのは、なるべく重くするため。
今回は自分のpcのcpuコア数が8なので、例えばcore_check_sub(8,1)なら[1, 1, 1, 1, 1, 1, 1, 1]であれば全コア使っていることになる。
core_check_sub(8,1)
->array([3, 1, 1, 1, 0, 1, 0, 1])
core_check_sub(16,1)
->array([4, 2, 2, 2, 0, 2, 2, 2])
core_check_sub(8,1000)
->array([1, 1, 1, 1, 1, 1, 1, 1])
まあ、予想通り、軽い計算だと全コアは使わない。
ただ、さらに厄介なのが、
core_check_sub(16,10)
->array([4, 2, 2, 2, 0, 2, 2, 2])
->array([6, 4, 0, 6, 0, 0, 0, 0])
->array([2, 2, 2, 2, 2, 2, 2, 2])
やってると結果がバラバラ。
見ていると、重い計算でも、何百回に一回くらいで偏りが生じる。
8core全て使ってくれた割合(1000回実行)
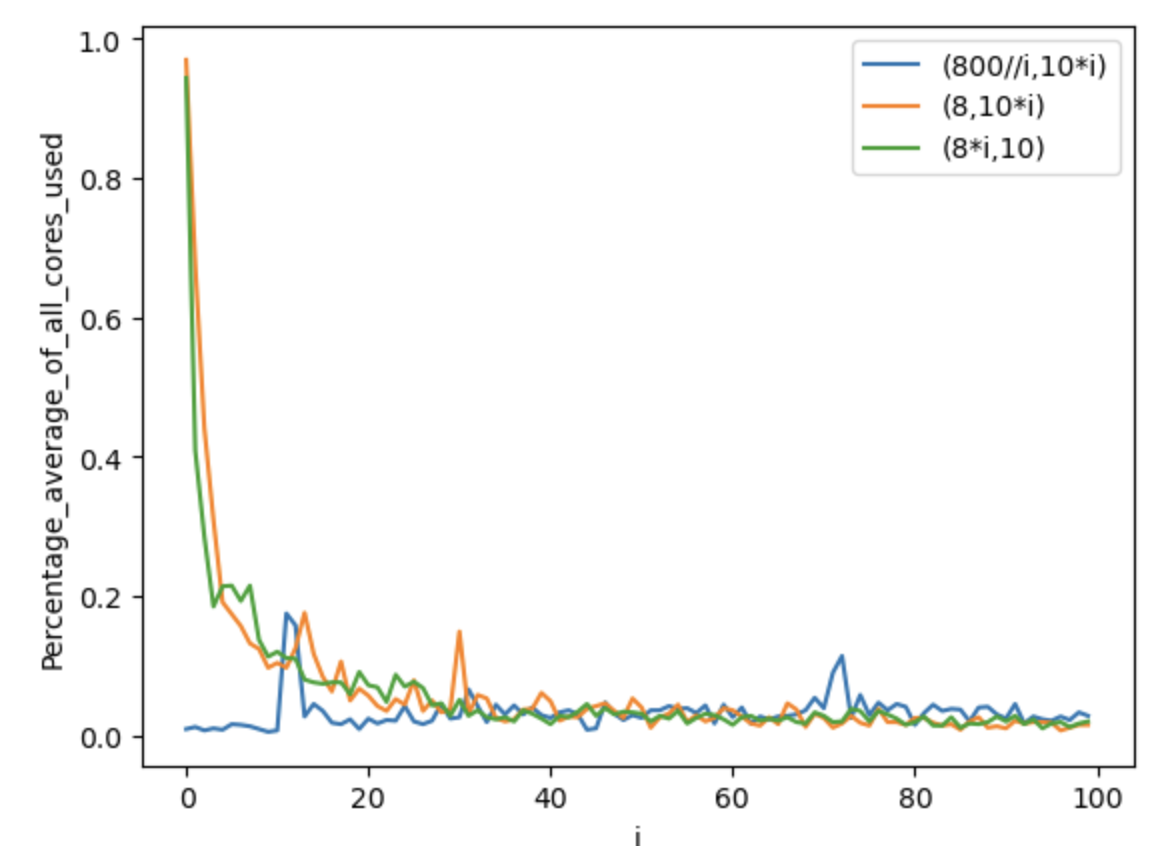
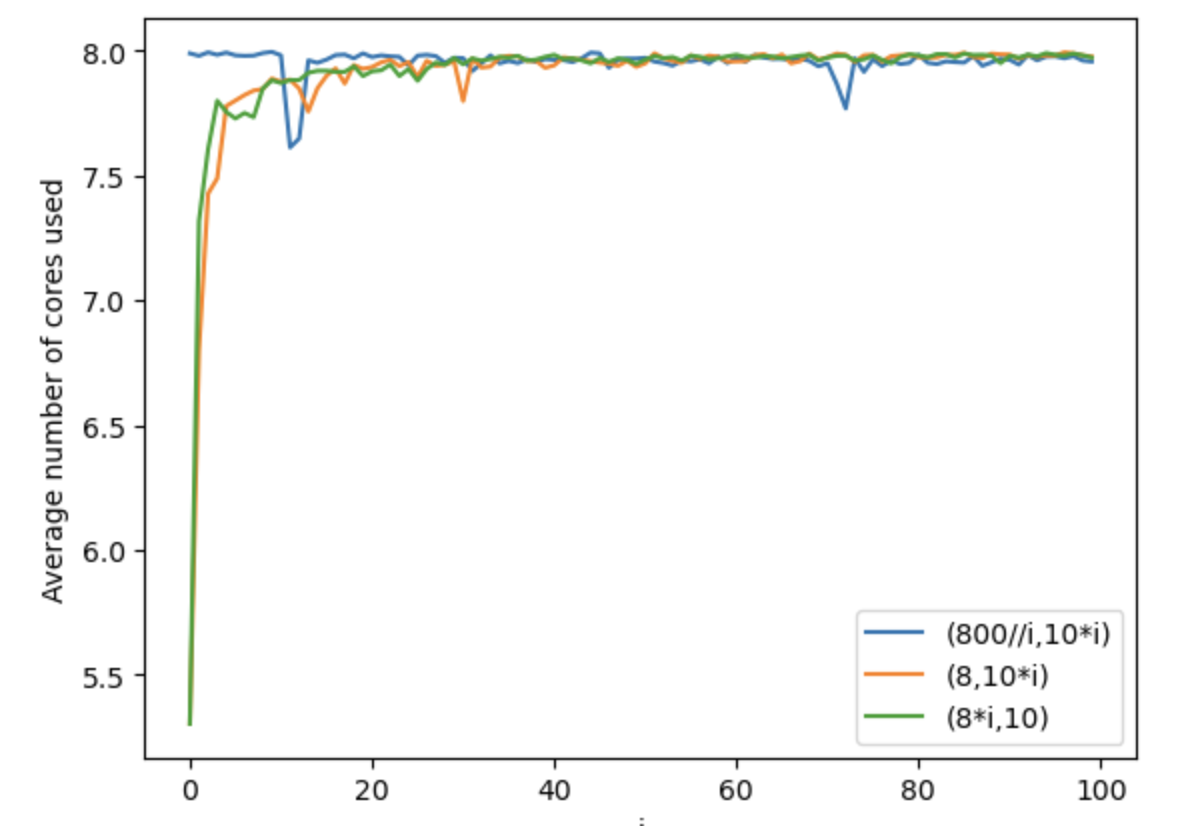
平均何コア使ったか(1000回実行)
平均実行時間(1000回実行)
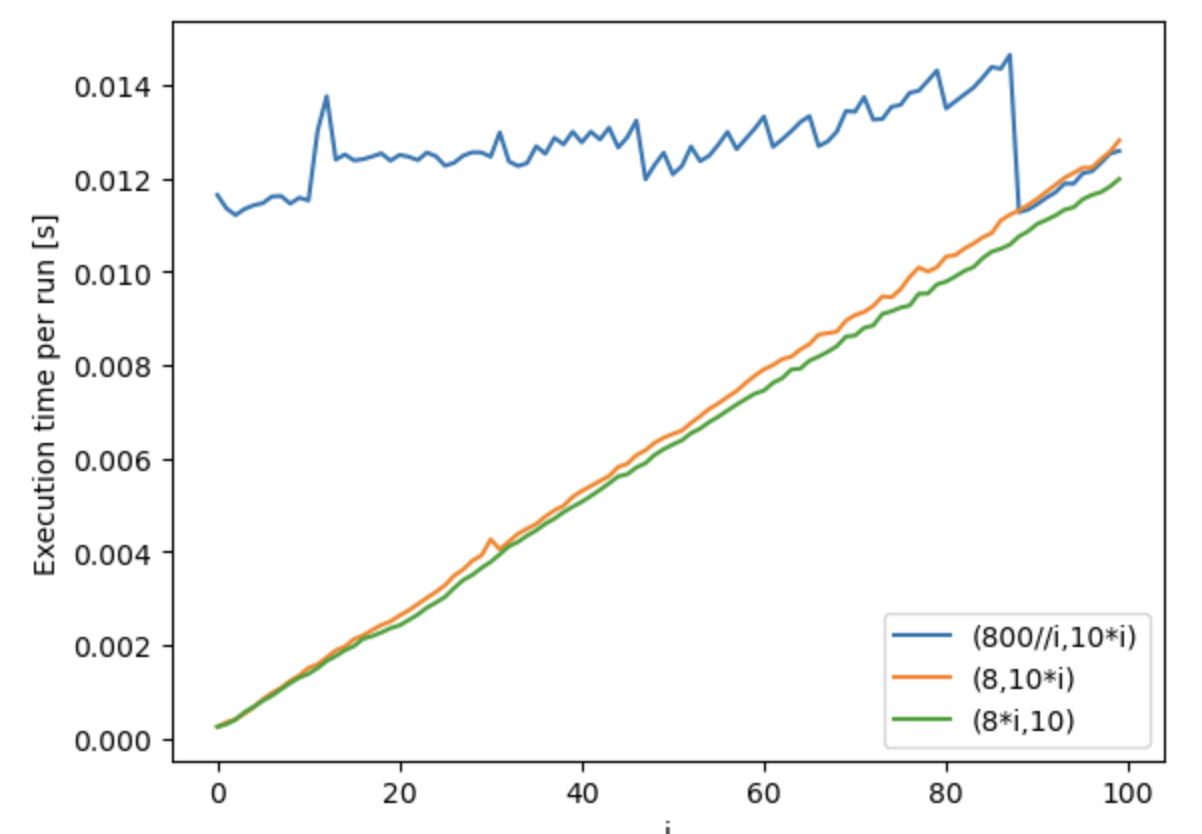
core_check_sub(8,10*i)とcore_check_sub(8*i,10)の比較
あまり差がない。とにかく時間がかかる処理になると使うコア数が増えるが、100%全コア使ってくれたりはしない
core_check_sub(int(800//i),10*i)を1000回実行した時の平均
実行時間がおんなじくらいになるようにして、「1つ1つの実行が重い:並列数が多い」で比べています。
全コア安定して使うためには、1つ1つの実行が重い方がいいのか、並列数が多い方がいいのか、結果を眺めても、よくわからないです。
もうこういうもんだと思って諦めます。
まあ、どうせ1時間ぐらい回し続ける時には多分ほぼ確実に全コア使ってくれるので問題ないということで
上書き問題
@njit(parallel=True)
def threads_checker_1d(n,num_threads=get_num_threads()):
set_num_threads(num_threads)
return_list=np.full(8,-1)
for i in prange(n):
min_index=np.argmin(return_list)
fibo(10000000)
return_list[min_index]=i
return return_list
フィボナッチ数列を使って重くしないと並列にならないので注意
- 結果
threads_checker_1d(16,1)
->array([ 8, 9, 10, 11, 12, 13, 14, 15])
threads_checker_1d(16,8)
->array([14, 11, -1, -1, -1, -1, -1, -1])
0->nで繰り返し、return_listで一番小さいindexに値を入れていく
上のでは、上書きが起こっていない結果が、threads_checker_1d(16,1)の結果
マルチスレッドのthreads_checker_1d(16,8)では、全ての繰り返しでindex=0,1に入れてしまっている。
が、これは別に、スレッドIDごとに入れる場所を分けてあげればいい
prange()の割り振り
ここで、prange()がどんなふうに割り振るかみると、
@njit(parallel=True)
def threads_checker_single(n,num_threads=get_num_threads()):
set_num_threads(num_threads)
return_list=np.full((n,2),-1)
for i in prange(n):
fibo(10000000)
thread_id=get_thread_id()
return_list[i]=np.array([i,thread_id])
return return_list
threads_checker_single(19,4)
で、結果は
print(threads_checker_single(19,8))
->[[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18]
[ 0 0 0 3 3 3 2 2 2 7 7 1 1 6 6 4 4 5 5]]
これは、np.array_split(np.arange(n), num_threads)とおなじ区切りかた。
ただし、スレッドIDは順番に振り分けられるわけではない(ランダム)。
n=19
num_threads=8
loop_list_base=np.array_split(np.arange(n), num_threads)
len_max=np.max([i.shape[0] for i in loop_list_base])
loop_list=np.array([i if i.shape[0]==len_max else np.append(i,-1) for i in loop_list_base])
loop_list
->array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, -1],
[11, 12, -1],
[13, 14, -1],
[15, 16, -1],
[17, 18, -1]])
まあ別に今回は他のスレッドが上書きしないようにしたいだけなので、スレッドIDの順番は関係ない。
一応順序関係なしのスレッドIDは、以下で計算できる
(i-np.min([(i+1)//(n//num_threads+1),n%num_threads]))//(n//num_threads)
def calc_thread_id(n,num_threads,i):
return (i-np.min([(i+1)//(n//num_threads+1),n%num_threads]))//(n//num_threads)
np_calc_thread_id=np.frompyfunc(calc_thread_id,3,1)
np_calc_thread_id(n,num_threads,loop_list)
->array([[0, 0, 0, 0],
[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3],
[4, 4, 4, -1],
[5, 5, 5, -1],
[6, 6, 6, -1],
[7, 7, 7, -1]], dtype=object)
上のスレッドIDを使うと、例えば上の方に書いたように指定したcpu数を使ってくれなかったときでも、問題なく動く
例えば4coreを使うとき、タスクを
[1 1 1 1]
のように一つずつ振り分けたかったのに
[2 1 1 0]
のように少しまとまってしまっても、計算自体は(時間がかかるかもだが)できる。
ただ、[1 1 1 1]のように計算するつもりだと、返り値の格納場所を[1 1 1 1]で用意するだろうから、上書き問題が発生する(index=0に2スレッドが同時に書き込む)。
上のスレッドIDを使うと計算自体は偏って行われるだろうが、格納場所は[1 1 1 1]にならされるため、問題ない。
get_thread_id()
まずは、上書き問題が発生すると思われるget_thread_id()を使った方法
ここでget_thread_id()を使った場合、上であったようにちゃんとスレッドが分かれてくれないことがある問題が原因
@njit(parallel=True)
def threads_checker_get_thread_id(n,num_threads):
return_list=np.full((num_threads,n//5),-1)
for i in prange(n):
thread_id=get_thread_id()
fibo(10000000)
min_index=np.argmin(return_list[thread_id])
return_list[thread_id,min_index]=i
return return_list
threads_checker_get_thread_id(53,4)
->array([[10, 11, 12, 13, 4, 5, 6, 7, 8, 9],
[50, 51, 52, 43, 44, 45, 46, 47, 48, 49],
[24, 25, 26, 17, 18, 19, 20, 21, 22, 23],
[37, 38, 39, 30, 31, 32, 33, 34, 35, 36]])
->array([[10, 11, 12, 13, 4, 5, 6, 7, 8, 9],
[37, 38, 39, 30, 31, 32, 33, 34, 35, 36],
[24, 25, 26, 17, 18, 19, 20, 21, 22, 23],
[50, 51, 52, 43, 44, 45, 46, 47, 48, 49]])
結果としては下の結果が正解
実際にやった感じ、3,4回に一回下の結果になる?
上書き問題の解消
具体的には以下の二種
1. 上の方法で、スレッドIDを被らないように計算し、代入
- 良い点:thread_idを入れて、return_listを1次元広くしてやるだけで動く(と思う)。
@njit
def threads_checker_prange_ans(n,num_threads):
return_list=np.full((num_threads,n//5),-1)
for i in range(n):
thread_id=(i-np.min(np.array([(i+1)//(n//num_threads+1),n%num_threads])))//(n//num_threads)
fibo(1000000)
min_index=np.argmin(return_list[thread_id])
return_list[thread_id,min_index]=i
return return_list
@njit(parallel=True)
def threads_checker_prange(n,num_threads=get_num_threads()):
set_num_threads(int(num_threads))
return_list=np.full((num_threads,n//5),-1)
for i in prange(n):
thread_id=(i-np.min(np.array([(i+1)//(n//num_threads+1),n%num_threads])))//(n//num_threads)
fibo(1000000)
min_index=np.argmin(return_list[thread_id])
return_list[thread_id,min_index]=i
return return_list
実行
threads_checker_prange_ans(53,4)
->array([[10, 11, 12, 13, 4, 5, 6, 7, 8, 9],
[24, 25, 26, 17, 18, 19, 20, 21, 22, 23],
[37, 38, 39, 30, 31, 32, 33, 34, 35, 36],
[50, 51, 52, 43, 44, 45, 46, 47, 48, 49]])
threads_checker_prange(53,4)
->array([[10, 11, 12, 13, 4, 5, 6, 7, 8, 9],
[24, 25, 26, 17, 18, 19, 20, 21, 22, 23],
[37, 38, 39, 30, 31, 32, 33, 34, 35, 36],
[50, 51, 52, 43, 44, 45, 46, 47, 48, 49]])
2. 並列数のみしかprangeを回さなければ、困るはずはない!
- prangeをcpu数のみにして、その中で
for i in rangeで通常のloopを回せば、別に困らないだろうと - 最後にcpu数だけの結果を入れる場所を作ってやれば競合もしない。
- 問題点:@njitつけるだけ!!みたいなnumbaの特徴から外れる。実装がだるいかも
@njit
def threads_checker_range_ans(n,num_threads):
return_list=np.full((num_threads,n//5),-1)
loop_list_base=np.array_split(np.arange(n), num_threads)
for thread_id in range(num_threads):
for i in loop_list_base[thread_id]:
min_index=np.argmin(return_list[thread_id])
return_list[thread_id,min_index]=i
return return_list
@njit(parallel=True)
def threads_checker_range(n,num_threads=get_num_threads()):
set_num_threads(num_threads)
return_list=np.full((num_threads,n//5),-1)
loop_list_base=np.array_split(np.arange(n), num_threads)
for thread_id in prange(num_threads):
for i in loop_list_base[thread_id]:
fibo(1000000)
min_index=np.argmin(return_list[thread_id])
return_list[thread_id,min_index]=i
return return_list
実行
threads_checker_range_ans(53,4)
->array([[10, 11, 12, 13, 4, 5, 6, 7, 8, 9],
[24, 25, 26, 17, 18, 19, 20, 21, 22, 23],
[37, 38, 39, 30, 31, 32, 33, 34, 35, 36],
[50, 51, 52, 43, 44, 45, 46, 47, 48, 49]])
threads_checker_range(53,4)
->array([[10, 11, 12, 13, 4, 5, 6, 7, 8, 9],
[24, 25, 26, 17, 18, 19, 20, 21, 22, 23],
[37, 38, 39, 30, 31, 32, 33, 34, 35, 36],
[50, 51, 52, 43, 44, 45, 46, 47, 48, 49]])
うまく行ってそう、、、