Masked Autoencoders Are Scalable Vision Learners
論文: https://arxiv.org/abs/2111.06377
Peng Zhiliangらによる実装: https://github.com/pengzhiliang/MAE-pytorch
要約
自然言語処理によく使われる「マスク予測タスク」という自己教師あり学習の手法を、視覚データに転用するマスク自動符号化器(Masked Autoencoder、MAE)という手法が何愷明(Kaiming He)らによって提案されました。
このごく簡単な手法はバニラのViT-Hで、公開時点での追加学習データなしのImageNetのSotAとなった(+0.7%で87.8%)。
BEiTという同じく「マスク予測タスク」を使う既存手法に比べて、MAEはそれ以上の精度を持つとともに、学習時間を大幅に削減できる。(16枚V100 32GBの5日 → 128コアTPUV3の15.4時間。エンコーダFLOPsから見ると3.3xくらいの加速)
簡単でスケール可能な手法こそが深層学習の定石なので、このような研究によって、視覚分野の深層学習もやがて(超大型モデルを使った)自己教師あり学習が教師あり学習を超えて、今後の主導的な手法となるのではないかと著者が示唆している。
手法と結果
既存手法としてのBEiTはBERTのように画像のパッチをトークン化して、マスクされてないパッチからマスクしたパッチのトークンを出力するように学習させている手法である。
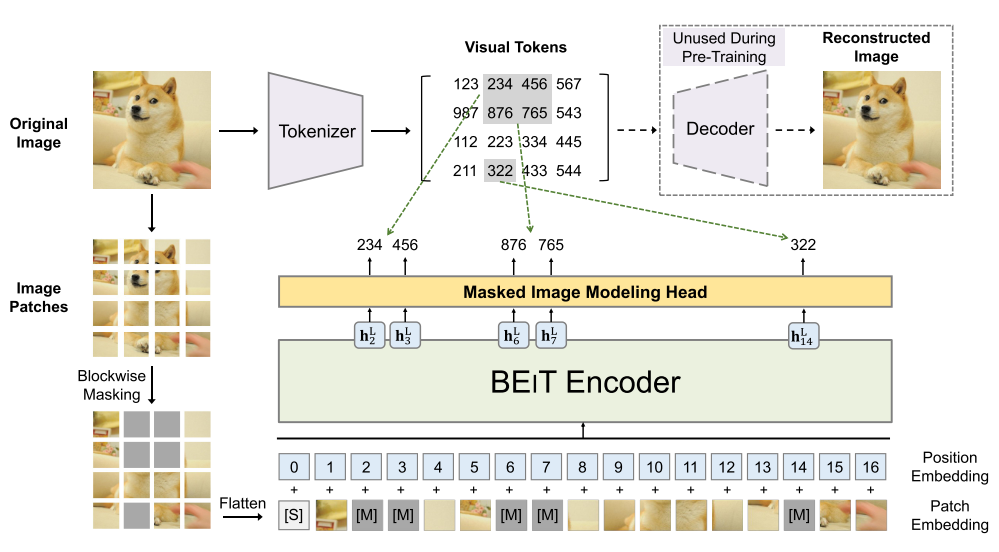
これに比べてMAEには2つの主な改善点がある。
- トークンではなく、エンコードした表現からピクセルを復元させる(事前学習の前にトークナイザーをつくる必要がなくなる)
- マスクしたパッチをエンコードしない(その分計算が減る)
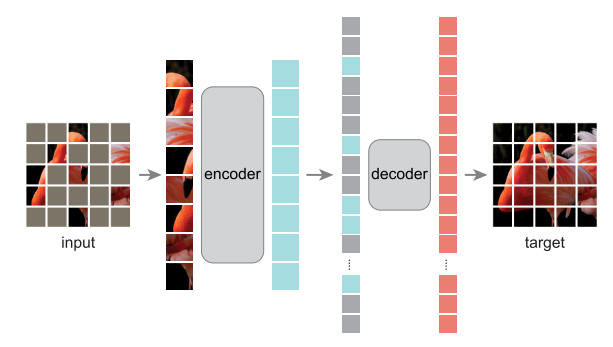
さらに、BEiTなどの既存手法は20%~50%のパッチをマスクするが、MAEではマスク率(Masking Ratio)を75%まで押し上げることができる。
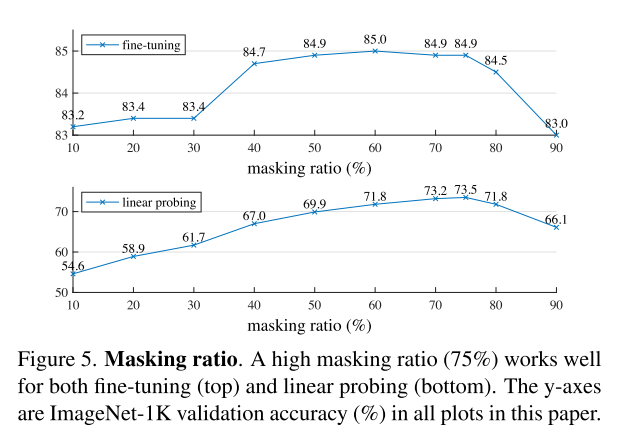
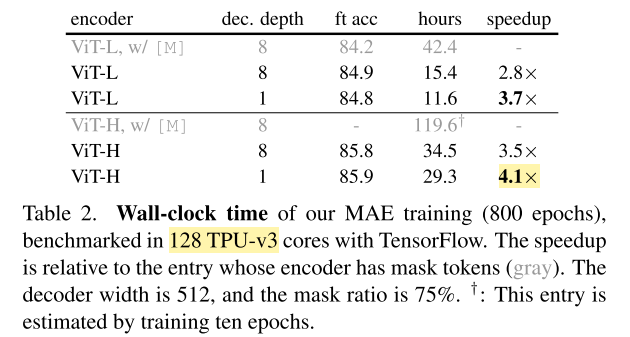
自己注意の複雑度が線形ではなく二次であるため、入力パッチ数を1/4にする(=75%のマスク率)ことによってスピードが4倍以上となること理論上に可能である。実際、デコーダーを小さくする実験に4.1倍のスピードアップを達成できた。
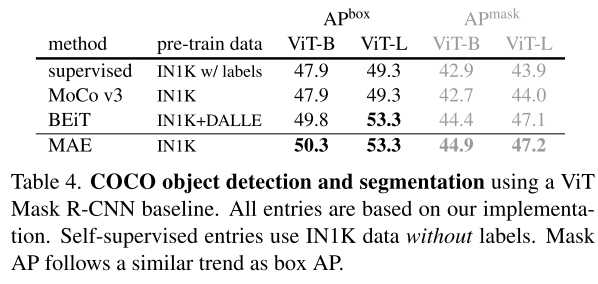
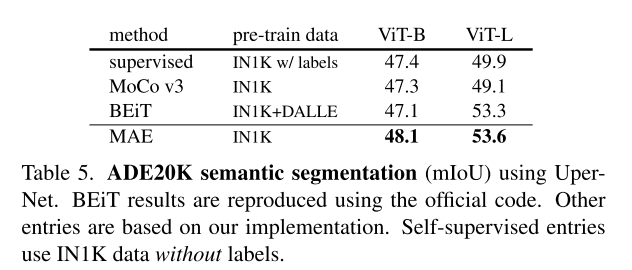
転移学習の実験としてCOCOとADE20Kで、MAEは教師あり学習より**3~4%**を超える精度を出せたことで、学習した特徴が優れていることを証明できた。そして、より少ない事前学習のデータでBEiTと同じ水準の精度を達成できた。
マスクされる画像の再構築の主観的評価として、MAEは近隣のピクセルからの単純な補間を行っているのではなく、全体を見た上で妥当な画像を生成していることが観測される(特にマスク率が85~95%の場合きのこの株の数が減ったり、ひとつの大きいきのこになったり、ピーマンが隠されたら2つのトマトになったりする、ある意味想像力を持った補完と個人的に思う)

この現象は選別されてない画像の再構築からも観測される(マスク率75%)。ここの例では値札がキッチン温度計みたいなものとなってある。

今後の発展への期待
今回公開したImageNet精度はバニラのViTを使っているが、ViT自体も1年の歴史を持つ技術としてどんどん発展している。追加データなしのImageNet精度の元SotAも、構造がより先進的なネットワーク(VOLO)を使っているので、ネットワーク構造の更新でより良いパフォーマンスが出るのではないかと、著者が提示している。
また、学習時にランダムにパッチを取り除いて、ピクセルレベルの再構築を求めることだけで、複雑かつ全体像を持った("complex and holistic")画像の再構築を行えるモデルを学習できた結果に対して、著者はMAE内部の豊かの表現のおかげで、数々の視覚的概念を習得できていると仮説を立てている。これで論文の冒頭に述べた、「自然言語が人間の故意による信号という本質に比べて、視覚信号が高い空間的重複性(spatial redundancy)を持つ」問題の答えになっているのではないのでしょうか。