概要
StyleGANの潜在空間次元分離性(PPLで表すDisentanglement)を大幅に改善した上に、
1024xの高解像度の画像を生成できるメリットを保つ画像生成手法、ALAE。
これを応用するために必要なことを調べながら一通りやってみました。

論文のFig.9で選ばれたサンプルは実際どう再構築されるのかを知るために生成した画像
ALAEを理解する
応用に関わるいくつの論文を説明します。
Progressive Growing
(Style)ALAEの構造はStyleGANから改善され、StyleGANはさらにProgressive Growingの論文の構造にStyleを入れたものなので、まずProgressive Growingの論文を理解する必要があります。
その名の通りで、Progressive Growingはどんどんネットワークを成長させる手法です。最初は小さい解像度の画像を生成させて、ある程度学習したら層を足して、より大きい画像を生成させ、この過程の繰り返しでやがて大きい (元の) 解像度の画像が生成できる手法です。
ALAEもProgressive Growingを用いて学習するので、外部のデータセットから小さい解像度の学習データを作る前処理が必要となります。
StyleGAN
StyleGANは生成ネットワークの各層の出力特徴マップの平均と分散をAdaINで制御する手法です。
AdaINはもともと画風変換のために開発された論文で、画風(Style)をエンコードできるCNN出力の特徴マップの位置不変性を持つ平均とバリアンスを変えられるオペレーションです。
StyleGANのStyleの使い方は、「画風」を制御するというより生成画像そのものを制御するが、既存研究に合わすためStyleとも呼んでいます。
また、GANでは事前分布に無理やりデータセットの分布で満たされようとする時生じる歪みを改善するため、StyleGANは学習する写像ネットワークで事前分布を中間分布に変換してからStyleに変換することをしています。ALAEでは中間分布の定義が少し違うが、基本的に中間分布とStyleによる生成の制御を引き継いでいますので、StyleGANと同じく高解像度の生成ができますし、Style-mixingなどもできます。
ALAE
ALAEの構造は、識別ネットワークのCNN後の特徴値の分布と、写像ネットワークが出力する中間分布とを近づかせようとするロスを足した手法です。AEは普通、入力画像=出力画像となるように学習するが、潜在空間上にある分布を近づかせようとするので、Latent Autoencoderという言葉を作ったようです。
こうして、推論時は識別ネットワークのCNN部で任意の画像を潜在空間・Styleに変換することもできます。
ALAEを使う
必要なもの
公式コードベース
データセット(例)
中身はこんな感じのものです。かわいいですね。

注意点として、ALAEのコードベースは、著者自作のPytorchでtfrecordを読み込むライブラリーDareBlopyを利用しています。
GCEインスタンス作成
公式コードベースにも各データセットの前処理のコードが書かれてあるが、新しいデータセットに使えないので、自分で前処理スクリプトを実装する必要があります。tfrecordにするならtensorflowがやりやすそうので、前処理はtensorflowを使います。
- 前処理専用に tensorflow + cpu
- 学習用に pytorch + gpu
GCP AI Platform Notebook インスタンスを2つ作りました。
データセットの前処理
公式コードの前処理スクリプトから見ると、ここでやらなければならないことが3つあります:
- 学習時使うGPUの数の整数倍のtfrecordsファイルにする
- 上の各ファイルのprogressive growingのための各解像度段階のtfrecordsファイルも作る
- 指定のルールに従ったファイル名で保存する
データセットをランダムの順番にして、分割して、それぞれtf.keras.layers.AveragePooling2D()で簡単に処理できました。Pytorchだとデータがchannel_firstかchannel_lastかをいつもチェックしないといけないので、そこは少し手間が増えるかもしれません。
データセットの設定作成
公式コードにいくつあったので、コピペ+比べながら中身をいじればできます。少し考える必要があったのは
- データセットの解像度に応じて
MAX_RESOLUTION_LEVELLAYER_COUNTLOD_2_BATCH_8/4/2/1GPUを設定 (猫画像は64x64なので5層のモデルになります) - 投入したい計算リソースに応じて
EPOCHS_PER_LOD(Progressive Growingの最終を除いた各段階のEpoch数),TRAIN_EPOCHSなどを設定
学習
実際コードを動かそうとしたら、最初はなかなかうまくいきませんでした。
aborted
なんと、一単語だけのエラーメッセージ。は?なんで?
と思いながらリポジトリのissueを調べたら他にもこの問題に引っかかった人がいました。
どうやらDareBlopyのC++部のエラー処理にキャッチされてないエラーのようで、#67みたいにfold sizeの問題ではなかったが、とにかくデータセットの設定もう一回りチェックしたら、データセットのパスが間違ったことがわかりました。 これくらいはちゃんとエラー処理しようよ…
更に、新しいバージョンのPytorch (1.8) を使ったせいかもしれないが、
AttributeError: 'WarmupMultiStepLR' object has no attribute 'verbose'
がでて、
に従いWarmupMultiStepLRのコンストラクターに self.verbose=True 足したら解決しました。
この2つの問題を解決したら問題なく学習でき、今回の3万枚ほど64x64の猫画像のデータセットはEPOCHS_PER_LOD = 15とTRAIN_EPOCHS = 120の設定で4GPUのインスタンスで数時間かかりました。
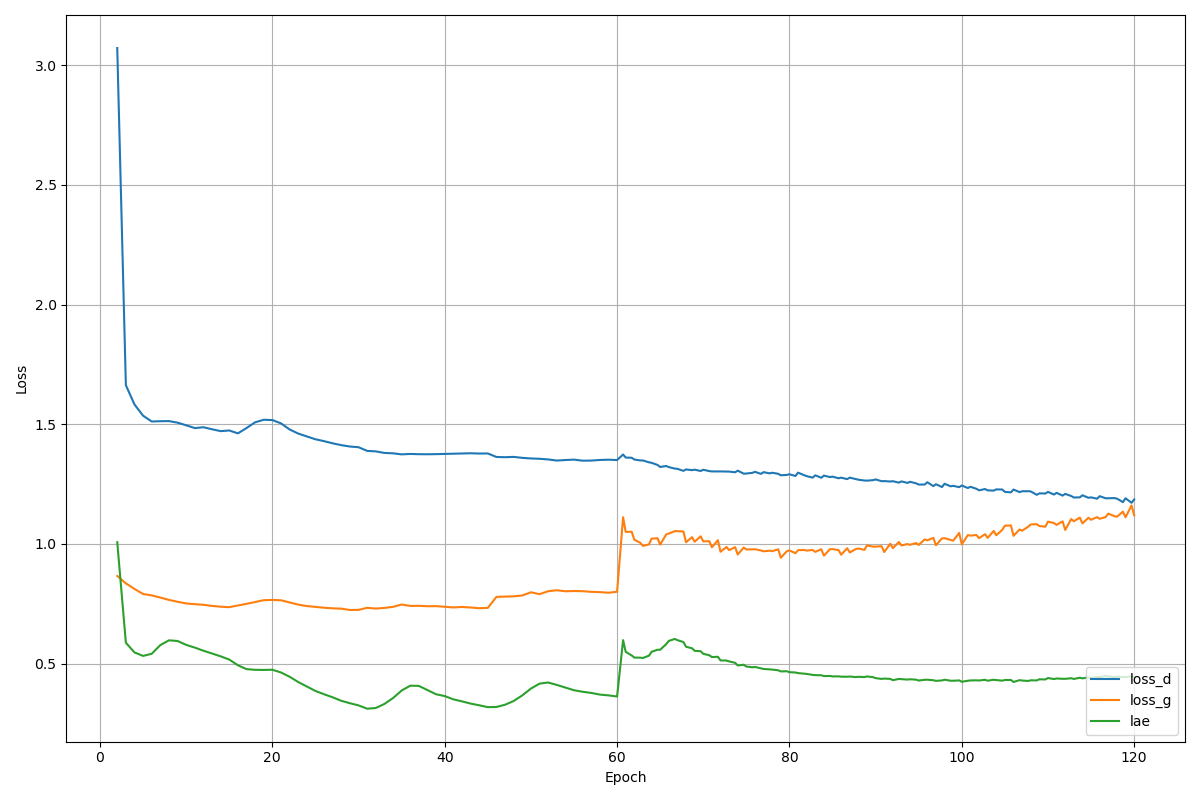
学習カーブ
動くデモを作成
公式リポジトリの手順で論文の公開モデルをダウンロードしてstyle mixを行う際に、training_artifacts/ffhq/last_checkpoint で設定されたデフォルトのモデルが training_artifacts/ffhq/model_157.pth で、論文の結果を再現するためにmodel_submitted.pthにする必要があります。リポジトリに入っている画像を使えば記事冒頭の画像を作れます。
Interactive Demoをjupyter notebookに動かすために、
ここのコメントには、インタラクティブではないけど、Sliderの値を変える結果を一緒に出力してくれる ipython notebook がありました:
このファイルが古くなっているので、そのまま実行できなかったが、いくつの修正を入れたら動きました。ついでに再構築をつけて、Sliderの値を変える間隔も変えました。

最初は論文のデモにあるスライダーが付くものにするつもりだったが、どうやら動かすためにある程度ハードが必要のようで、今回は ipython notebook で動くものにしました。
猫画像データセットで学習したモデルを使う
まずSliderのあるinteractive demoはデータセット自体にラベルがないことで断念しました。GANSpaceなどの手法で作れるかもしれません、今回の範疇から外れています。とにかくStylemixで学習したモデルの各層にどんな特徴が捉えているのかを調べていました。
まず、ffhqの9層モデルのstylemixスキーマを猫画像モデルの5層にする必要があります。

とある層のStyleが:S=Sourceから、D=Destinationから
123456789
SSDDDDDDD
SSDDDDDDD
SSDDDDDDD
DDSSDDDDD
DDSSDDDDD
DDDDSSSSS
元のこの処理をこうすれば以下のイメージを作れました。
12345
SDDDD
SDDDD
DSDDD
DSDDD
DDSSS
DDSSS

実験しやすくするために ipywidgets を使ってクリックするだけで動くipython notebookも作りました。
考察
実際にやってみれば、還元度が高い画像もあれば、低い画像もありました。

論文のTable 3により、StyleALAEのFIDがStyleGANより数倍長いことも書かれているので、ある程度予想がついています。論文ではこの問題の原因を計算が足りないと仮定しています。
Stylemixの結果より、猫画像のデータセットに対してもある程度「最初の層が荒い特徴を扱い、最後の層が細かい特徴や色を扱う」(顔の形->表情、目の開き、毛の模様->毛の色)という傾向が見れますが、論文ほどきれいに分かれていません。これは層の数の問題かもしれません。層の分け方の問題であることもありえます。
StyleALAEはStyleGANのモデルに基づいているので、StyleGANの生成アーティファクト問題に見えるものも実験中に見つけました。多分ベースモデルをStyleGAN2に変えたら良くなるのであろう。

謝辞
この記事の作成にたくさん協力していただいた同社エンジニアの川端さん、今北さん、そして太田さんに感謝の意を表します。
おまけ
遊びで試したら、学習データセットのドメイン以外の画像を入力しても、(失敗する画像もあるが) 再構築できました。
猫ではないものを猫にする:

人間ではないものを人間にする:

こういう評価をいただきました:
「ペットは飼い主に似る」と言いますが、単純に再構築したのはそんな感じ。
「この猫この人に似てますね」って言ったら同意するレベル。
うんうん、確かにそうですね。