まえがき
前回書いた、「プログラミング未経験者がpythonを覚えて子ども用計算ドリルを作る」は多くの方に読んでいただくことができました。こんな初心者の大したことがないプログラミングに興味を読んでいただきましてありがとうございます。また、何名かの方にはこうやって書いた方がいいと、アドバイスをいただくことができました。
今回はその続編となります。
やりたいこと
前回は一桁の足し算同士でした。今度は二桁以上の足し算の計算ドリルを作りたいと思います。
前回は1〜9同士の計算だったのですべての配列で81通りでした。しかし今度は二桁だと1〜99で、すべての組み合わせでやろうとすると9801通りあります。この中から81通りをピックアップしたいと思います。
条件としては基本前回と一緒ですが、当然のこととして1枚の計算シートで式の重複が発生しないようにするということです。
注意
コメントに書いていただいているプログラムの方がずっとシンプルでした。私が書いた内容は素人が試行錯誤してやった結果ということで、実用的なのは下のコメントのものです。
前回のパターンでやってみる
excelに書き込む方法などは前回のものを参照していただくとして、今回は配列を作るところだけをやります。
list_ = [[a, b] for a in range(1, 100) for b in range(1, 100)]
random.shuffle(list_)
list_ = list_[:81]
前回書いたあとに、pythonでは配列に対するfor文は1行にできると教えていただきました。そのパターンで今度は二桁ならrange(1,100)とします。そして前回同様にrandom.shuffleを使って配列をバラバラにします。このばらばらにした配列の前から81列目までをピックアップして作るという方法です。
処理にかかる時間
しかし前回は81通りを出すだけでしたが、今回は一旦9801通りを出力しています。こんなことをしていて処理が遅くならないのではないでしょうか?
そこで「【Python】処理にかかる時間を計測して表示」という記事を参考にして、処理時間を計測してみました。
if __name__ == '__main__':
start = time.time()
list_ = [[a, b] for a in range(1, 100) for b in range(1, 100)]
random.shuffle(list_)
list_ = list_[:81]
elapsed_time = time.time() - start
print("elapsed_time:{0}".format(elapsed_time) + "[sec]")
これにかかった時間は0.01064610481262207[sec]でした。0.01秒なら余裕かなと思いましたが、前回の配列を出すのにかかった時間を改めて計測してみました。すると0.00011992454528808594[sec]と約100倍も時間がかかっていることがわかりました。そりゃそうだ。ただ、この方法だと桁数が増えれば増えるほど計算時間がかかってしまいます。お家でやる分には別に何秒だろうがいいのですが、あまり賢い方法ではないと思います。そこで別の方法をやってみることにしました。
列に入れる数字を乱数にする
「Numpyによる乱数生成まとめ」という記事を読んだところ、numpy.randomというモジュールを使うと乱数を生成できるということでした。numpyって機械学習とかでよく使われているモジュールですが、今回は人間の学習のために使います。
from numpy.random import *
list_ = []
while len(list_) <= 81:
a = randint(1, 100)
b = randint(1, 100)
list_.append([a, b])
list_ = list(map(list, set(map(tuple, list_))))
from numpy.random import *でモジュールをインポートしたあとに、whileでlist_に81列まで値が入るようにループをさせることにしました。a = randint(1, 100)で1〜99までのランダムな整数をaに代入します。bも同様の処理をして、list_.append([a, b])でlist_の配列に挿入します。
list_ = list(map(list, set(map(tuple, list_))))がなにかというと、ランダムな値をaとbに代入しているとはいえ、もしかしたら配列の中に同じパターンが入っているかもしれません。今回の意図としては計算式の重複はあってはいけません。1〜99なら確率は相当低いですが、1〜20なら発生するかもしれない。そこで「Pythonで2次元配列の重複行を一発で削除する」をもとに、重複を削除する行を入れました。pythonでは配列の重複はset()で解消できるそうなのですが、[[1,1],[1,2]]みたいなものを2次元配列ではタプル型にしないと使えないのです。また、setにすると配列が自動的に順番通りに並び替えられてしまうため、mapというのを使って元の順番をキープさせています。list(map(listというのはタプル型を元のリスト型に戻すための処理です。
再び処理時間を測る
さてこのプログラムを作ってみて処理時間を測ってみました。
オリジナル :0.00011992454528808594[sec]
9801通りから81通りを抽出 :0.01064610481262207[sec]
乱数を使って81通りを作成 :0.0015819072723388672[sec]
オリジナルよりは10倍時間がかかっていますが、9801通り作るものよりは10分の1の処理速度でできました。しかもこの計算式がいいのは計算式の桁数を上げても処理速度が変わらないということです。もとのパターンでは桁数を上げれば上げるほど足し算のパターンが増えて計算が遅くなっていきます。
多分他にいい方法があると思いますが、とりあえずこうやって解決しました。
これを前回のプログラムの配列作成の部分と置き換えます。
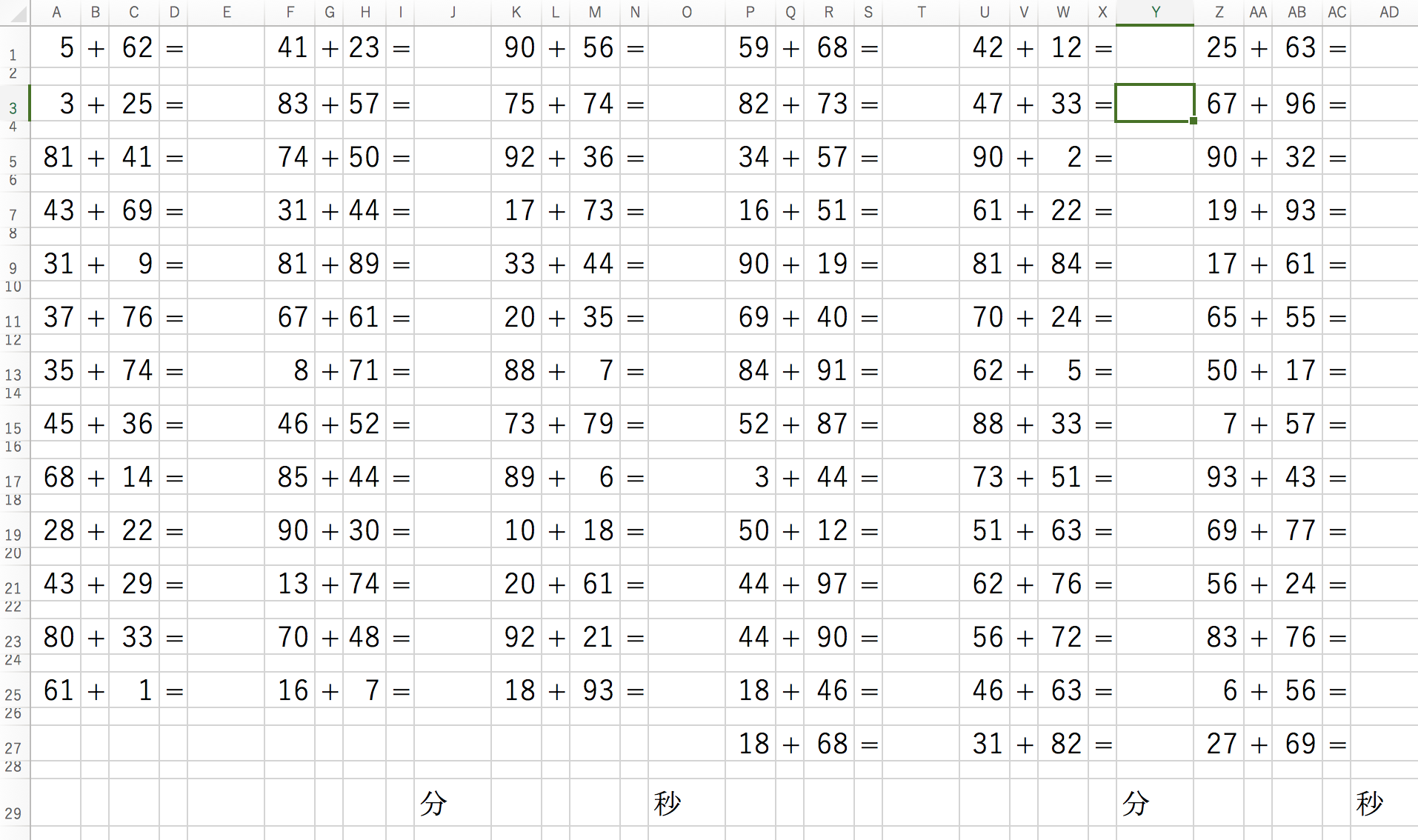
アウトプットの結果
二桁の足し算ならこんなアウトプットでは計算がやりづらいので、そこは検討しないといけませんが、とりあえず欲しいものは出せました。
余談
あれから作った計算ドリルを子どもは毎日ちゃんとやっています。お家でほしいドリルが作れるって本当に便利です。