(注)ここでは最終結果だけでなくエラーの試行錯誤も含めて書いていきます。
また、あくまで参考のため、全件で訓練し、同じデータで学習結果を確認します。
目的
過去4日分を参考に日経平均を予測します。
株価データの読み込み
松井証券のcsvから終値を読み込みます。
# coding: UTF-8
import pandas as pd
stock_data = pd.read_csv('stockchart_20180909.csv')
owarine = stock_data[['終値']]
(メモ)最初「終値」の表記ではダメでした。なぜか再度実行するとOK。理由は・・・なぜでしょう。
successive_data = []
answers = []
for i in range(4, count_s):
successive_data.append([owarine[i-4], owarine[i-3], owarine[i-2], owarine[i-1]])
answers.append(owarine[i])
successive_data:過去4日分の終値
answers:当日の終値
clf = svm.LinearSVC()
n = len(successive_data)
m = len(answers)
clf.fit(successive_data, answers)
デバック
機械学習させるとエラーとなりました。
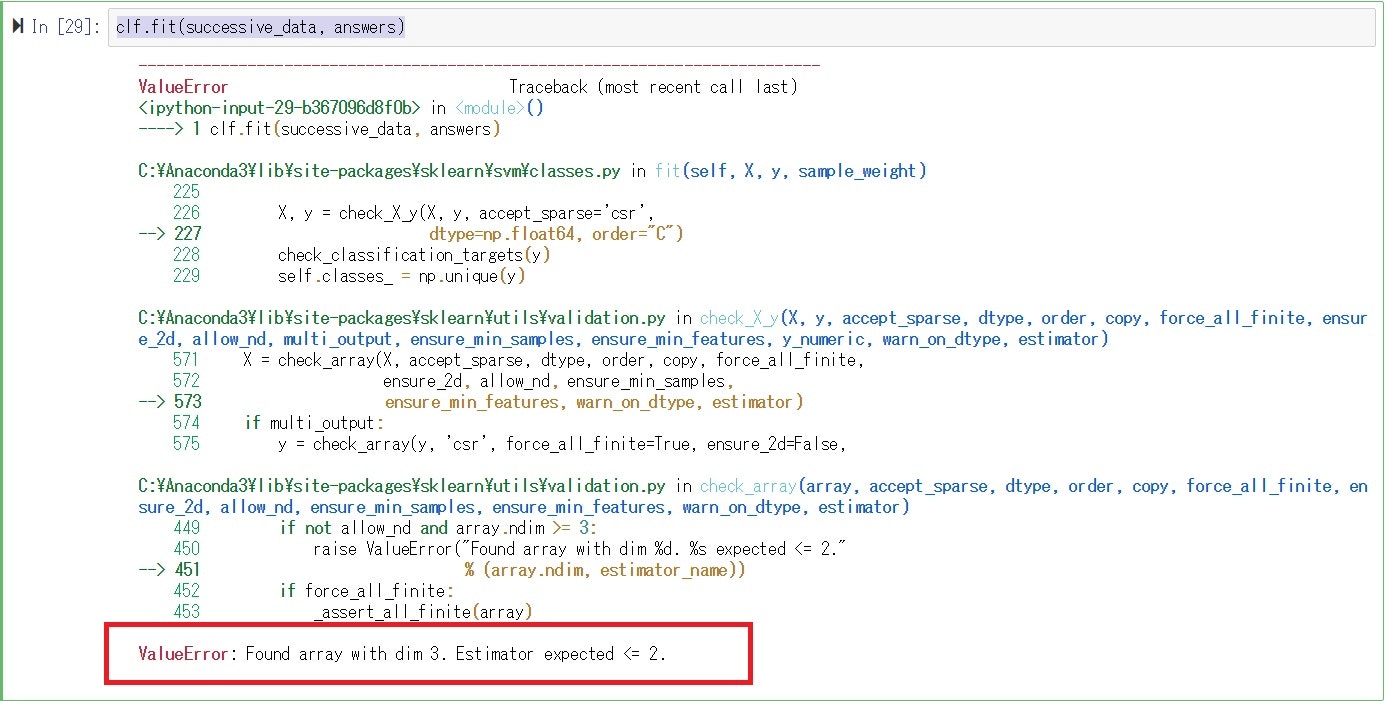
「dim 3」は3次元配列になっているというエラーのようです。
よくよく見るとowarineが変です。

「[~],[~]」となっているため、1つの値の配列の1000個配列の1つのリスト扱いの模様です。pythonでは1つの値の配列ってできるんですね。
owarine = stock_data[['終値']]
↓
owarine = stock_data['終値']
ここの問題でした。pandasの複数列用サンプルそのまま使ったのが問題だったようです。
再度実施したところ別のエラーが発生です。
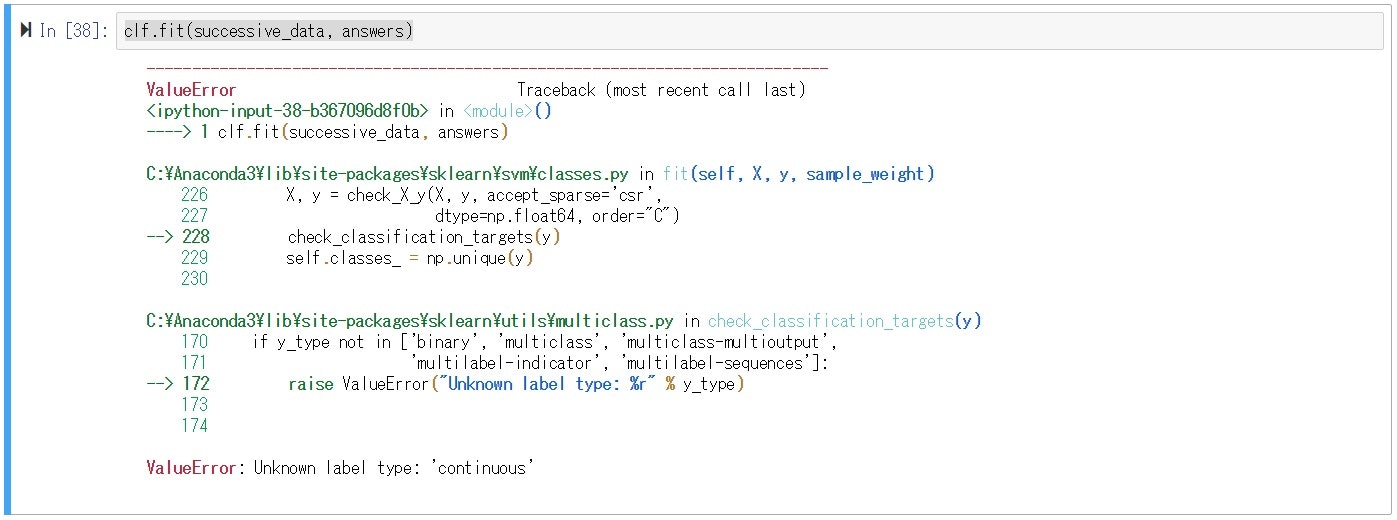
ググってみるとy値は整数でないといけないらしい。
よってanswersは整数にします。
answers.append(owarine[i])
↓
answers.append(round(owarine[i]))

fitが通ったので同じデータで結果を出力します。
predicted = clf.predict(successive_data)
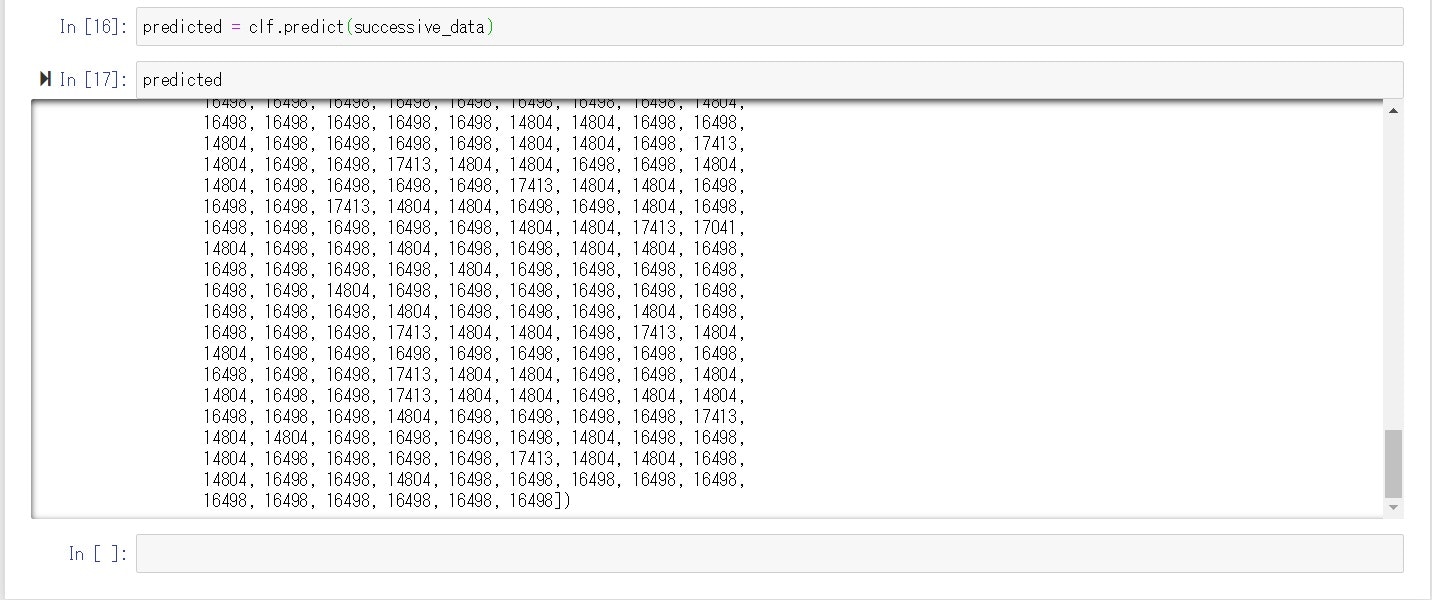
一応学習して数字が出ました。
でも同じ数字が大量に・・・これはSVMで学習したがためのようです。
SVMあくまで分類のため、教師ありの場合のどの値に近いか
出力したためのものです。
※SVMの説明はこちらが簡単で分かりやすそうです。
よってここでは教師データを日経平均ではなく前日との差とします。
ただ前日と比べて上がった/下がったは結構多くの人がやっていますのでちょっと趣向を変え
(日経平均_当日 - 日経平均_前日)÷ 100 を四捨五入した値を使います。
(例)前日から+180円なら+2、-310円なら-3、+30円なら0等。
大きさの幅があった方がリアルっぽくなるのかなと思います。
先ほど直したanswersを再度修正します。
answers.append(round(owarine[i]))
↓
x1 = (owarine[i] - owarine[i-1]) / 100
x2 =round(x1)
answers.append(x2)
学習結果
このまま学習すると
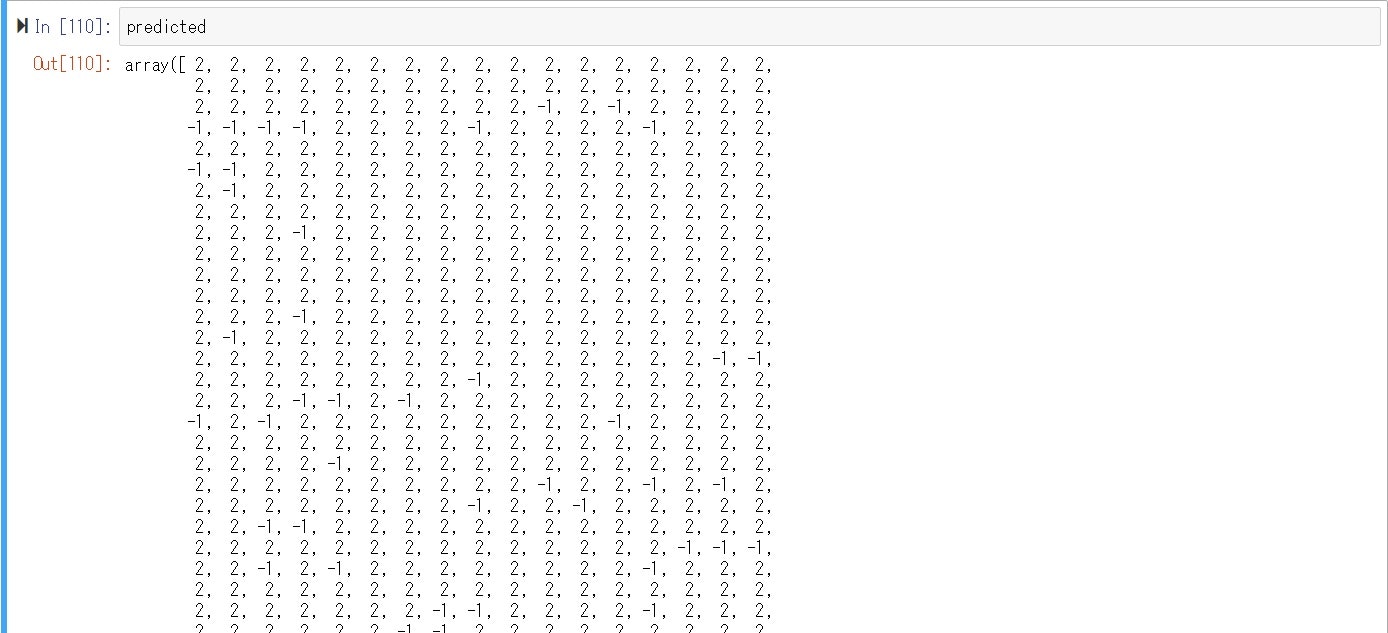
何やら2と-1ばかりで怪しげですが学習ができました。
※何度か試すと結果は変わりました。
まとめ
結果を表示します。
from sklearn.metrics import accuracy_score
accuracy_score(answers, predicted)

あまりよくはないようです。
ソース