C++でYOLOv9を動かします
流れとしては以下のようになります。
- PythonでYOLOv9の動作を確認します
- YOLOv9のモデルをONNX形式でエクスポートします
- C++用のONNXRUNTIMEを使用してモデルを読み込みます
- QtでGUIアプリを作ります
筆者の開発環境
- Arch Linux
- Python 3.12
PythonでYOLOv9の動作を確認する
Pythonの仮想環境を作成する
python -m venv yolov9env
Pythonの仮想環境を有効化する
cd yolov9env
source bin/activate
YOLOv9を準備する
git clone https://github.com/WongKinYiu/yolov9.git
cd yolov9
pip install -r requirements.txt
事前学習済みデータを取得する
wget -P weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt
推論を実行する
python detect.py --weights weights/yolov9-c.pt --conf 0.1 --source data/images/horses.jpg --device 0 --exist-ok
最初は AttributeError: 'list' object has no attribute 'device' というエラーが出ると思います。その場合は、 https://github.com/WongKinYiu/yolov9/issues/11 の記述に従って utils/general.py の903行を以下のように修正します
prediction = prediction[0][0] # select only inference output
修正したら、もう一度推論を実行します。
正常に実行できたら、結果の画像が runs/detect/exp に保存されます。
(yolov9env) soramimi@alice:~/py/yolov9env/yolov9$ ls -ls runs/detect/exp
合計 156
156 -rw-r--r-- 1 soramimi soramimi 157641 5月 4 23:15 horses.jpg
できた画像ファイルを見てみましょう。

YOLOv9のモデルをONNX形式でエクスポート
onnxをインストールします
pip install onnx
推論のためのPythonスクリプトを改造します
cp detect.py saveonnx.py
インポートを追加します
import torch.onnx
# Dataloaderの行から下、def parse_opt():の行の手前までを削除します。
削除した行の代わりに、以下の行を追加します。
torch.onnx.export(model, torch.randn(1, 3, *imgsz).to(device), 'yolov9.onnx')
ONNX形式でエクスポートします
python saveonnx.py --weights weights/yolov9-c.pt --device 0
yolov9.onnxができたら、NETRONで可視化してみましょう。
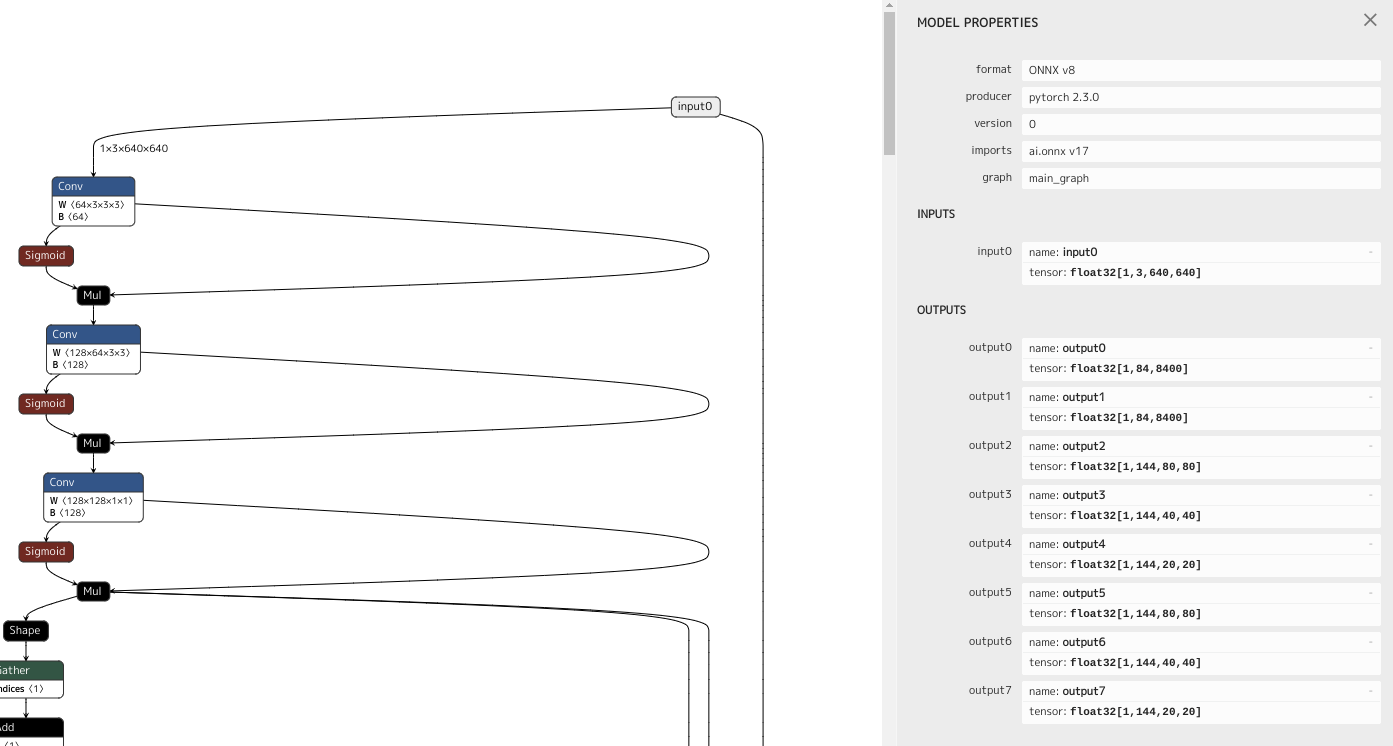
ONNX形式を確認
いちばん上のinput0をクリックすると、右側にモデルの情報が表示されます。入力は[1, 3, 640, 640]のテンソルです。これは、1枚の3チャンネル(RGB)高さ640幅640のデータを入力することを意味します。出力は8つありますが、output0だけ使います。これは[1, 84, 8400]のテンソルを出力します。84要素のデータが8400個あることを示しています(注意点があります:後述)。84要素のデータの中には、検出されたバウンディングボックスの座標(4要素)と、クラス分類数(80)が含まれています。
C++でONNXRUNTIMEを利用するコードを作る
参考
作業ディレクトリを作る
cd ..
mkdir work
cd work
C++のコードを実装します
冒頭部分では、インクルードの指定、結果を格納する構造体の定義、ONNXRUNTIMEで使用する変数などの定義、初期化を行います。
#include <onnxruntime/onnxruntime_cxx_api.h>
#include <memory.h>
#include <iostream>
struct BoundingBox {
int index;
float score;
float x, y, w, h;
};
int main()
{
std::unique_ptr<Ort::Env> env;
std::unique_ptr<Ort::MemoryInfo> memory_info;
Ort::SessionOptions session_options;
std::unique_ptr<Ort::Session> session;
size_t num_input_nodes = 0;
size_t num_output_nodes = 0;
std::vector<char const *> input_node_names;
std::vector<char const *> output_node_names;
std::vector<std::string> input_node_name_strings;
std::vector<std::string> output_node_name_strings;
// ONNX Runtime環境の初期化
env = std::make_unique<Ort::Env>(ORT_LOGGING_LEVEL_WARNING, "test");
memory_info = std::make_unique<Ort::MemoryInfo>(Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU));
// 推論セッションの設定
session_options.SetIntraOpNumThreads(1);
続いて、モデルの読み込みを実装します。ONNXRUNTIMEセッションの作成と、入出力情報を取得しています。
char const *model_path = "../yolov9/yolov9.onnx";
// モデルの読み込み
try {
// セッションの生成
session = std::make_unique<Ort::Session>(*env, model_path, session_options);
// 入出力情報の取得
num_input_nodes = session->GetInputCount();
num_output_nodes = session->GetOutputCount();
// qDebug() << "Number of input nodes:" << num_input_nodes;
// qDebug() << "Number of output nodes:" << num_output_nodes;
Ort::AllocatorWithDefaultOptions allocator;
// 入力ノード名の取得
input_node_names.resize(num_input_nodes);
input_node_name_strings.resize(num_input_nodes);
for (size_t i = 0; i < num_input_nodes; i++) {
input_node_name_strings[i] = session->GetInputNameAllocated(i, allocator).get();
input_node_names[i] = input_node_name_strings[i].c_str();
// qDebug() << "input:" << input_node_names[i];
}
// 出力ノード名の取得
output_node_names.resize(num_output_nodes);
output_node_name_strings.resize(num_output_nodes);
for (size_t i = 0; i < num_output_nodes; i++) {
output_node_name_strings[i] = session->GetOutputNameAllocated(i, allocator).get();
output_node_names[i] = output_node_name_strings[i].c_str();
// qDebug() << "output:" << output_node_names[i];
}
} catch (const Ort::Exception &e) {
std::cerr << "Error:" << e.what() << std::endl;
exit(1);
}
推論処理の実装です。
const int N = 1; // batch size
const int C = 3; // number of channels
const int W = 640; // width
const int H = 640; // height
// 入力データの準備
std::vector<float> input_tensor_values(N * C * H * W);
// ★★★ TODO: ここで画像を読み込んでinput_tensor_valuesに格納する ★★★
// 入力テンソルの生成
std::vector<int64_t> input_tensor_shape = {N, C, H, W};
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(*memory_info, input_tensor_values.data(), input_tensor_values.size(), input_tensor_shape.data(), input_tensor_shape.size());
// 推論の実行
auto output_tensors = session->Run(Ort::RunOptions{nullptr}, input_node_names.data(), &input_tensor, 1, output_node_names.data(), num_output_nodes);
出力テンソルを解読して、バウンディングボックスと推論スコアを取得します。
COCOデータセットによる事前学習データの場合、出力テンソルは [1, 84, 8400] となります。これは、84個のfloat値が8400個あるということです。概念的には以下のような構造体が8400個あるのですが、ここで注意が必要です。
struct Item {
float x;
float y;
float w;
float h;
float score[80];
};
テンソルの形式が [1, 8400, 84] であるならば話は簡単です。しかし実際には [1, 84, 8400] となっています。つまり、8400個毎の間隔で84回値を拾うことで、上記のような構造体が8400個得られます。転置するのも面倒ですし無駄なので、次のようなラムダ式を利用することにします。
const int count = shape[2];
auto Value = [&](int index){
return output_tensor[count * index + i];
};
これを使用すると、次のように値を取得できます。
-
Value(0): X座標 -
Value(1): Y座標 -
Value(2): 幅 -
Value(3): 高さ -
Value(4)〜Value(83): 80分類分の各スコア値
座標データは正規化されておらず、[0, 640]の範囲となっています。スコアは[0, 1]の範囲です。
以上を踏まえて、出力テンソルからバウンディングボックスの情報を読み取る処理を実装します。
// 結果を生成
std::vector<BoundingBox> bboxes;
auto info = output_tensors.front().GetTensorTypeAndShapeInfo();
std::vector<int64_t> shape = info.GetShape(); // e.g. {1, 84, 8400}
const int values = shape[1]; // maybe 84 if coco dataset
const int classes = values - 4; // 80 classes
const int count = shape[2];
float const *output_tensor = output_tensors[0].GetTensorData<float>();
for (int i = 0; i < count; i++) {
auto Value = [&](int index){
return output_tensor[count * index + i];
};
// x, y, w, h, class0, class1, ...
float x = Value(0);
float y = Value(1);
float w = Value(2);
float h = Value(3);
x -= w / 2;
y -= h / 2;
for (int j = 0; j < classes; j++) { // クラス数
BoundingBox bbox;
bbox.score = Value(4 + j);
if (bbox.score > 0.5) { // 一定よりスコアが高ければ
bbox.index = j;
bbox.x = x;
bbox.y = y;
bbox.w = w;
bbox.h = h;
bboxes.push_back(bbox); // 記録する
}
}
}
以上で、推論処理の主要な部分の実装はできました。
画像を読み込んで入力テンソルを作る処理と、推論結果のバウンディングボックスを描画する処理は、QtのGUIアプリで実装します。
ソースコード全体
#include <onnxruntime/onnxruntime_cxx_api.h>
#include <memory.h>
#include <iostream>
struct BoundingBox {
int index;
float score;
float x, y, w, h;
};
int main()
{
std::unique_ptr<Ort::Env> env;
std::unique_ptr<Ort::MemoryInfo> memory_info;
Ort::SessionOptions session_options;
std::unique_ptr<Ort::Session> session;
size_t num_input_nodes = 0;
size_t num_output_nodes = 0;
std::vector<char const *> input_node_names;
std::vector<char const *> output_node_names;
std::vector<std::string> input_node_name_strings;
std::vector<std::string> output_node_name_strings;
char const *model_path = "../yolov9/yolov9.onnx";
// ONNX Runtime環境の初期化
env = std::make_unique<Ort::Env>(ORT_LOGGING_LEVEL_WARNING, "test");
memory_info = std::make_unique<Ort::MemoryInfo>(Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU));
// 推論セッションの設定
session_options.SetIntraOpNumThreads(1);
// モデルの読み込み
try {
// セッションの生成
session = std::make_unique<Ort::Session>(*env, model_path, session_options);
// 入出力情報の取得
num_input_nodes = session->GetInputCount();
num_output_nodes = session->GetOutputCount();
// qDebug() << "Number of input nodes:" << num_input_nodes;
// qDebug() << "Number of output nodes:" << num_output_nodes;
Ort::AllocatorWithDefaultOptions allocator;
// 入力ノード名の取得
input_node_names.resize(num_input_nodes);
input_node_name_strings.resize(num_input_nodes);
for (size_t i = 0; i < num_input_nodes; i++) {
input_node_name_strings[i] = session->GetInputNameAllocated(i, allocator).get();
input_node_names[i] = input_node_name_strings[i].c_str();
// qDebug() << "input:" << input_node_names[i];
}
// 出力ノード名の取得
output_node_names.resize(num_output_nodes);
output_node_name_strings.resize(num_output_nodes);
for (size_t i = 0; i < num_output_nodes; i++) {
output_node_name_strings[i] = session->GetOutputNameAllocated(i, allocator).get();
output_node_names[i] = output_node_name_strings[i].c_str();
// qDebug() << "output:" << output_node_names[i];
}
} catch (const Ort::Exception &e) {
std::cerr << "Error:" << e.what() << std::endl;
exit(1);
}
const int N = 1; // batch size
const int C = 3; // number of channels
const int W = 640; // width
const int H = 640; // height
// 入力データの準備
std::vector<float> input_tensor_values(N * C * H * W);
// TODO: ここで画像を読み込んでinput_tensor_valuesに格納する
// 入力テンソルの生成
std::vector<int64_t> input_tensor_shape = {1, 3, H, W};
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(*memory_info, input_tensor_values.data(), input_tensor_values.size(), input_tensor_shape.data(), input_tensor_shape.size());
// 推論の実行
auto output_tensors = session->Run(Ort::RunOptions{nullptr}, input_node_names.data(), &input_tensor, 1, output_node_names.data(), num_output_nodes);
// 結果を生成
std::vector<BoundingBox> bboxes;
auto info = output_tensors.front().GetTensorTypeAndShapeInfo();
std::vector<int64_t> shape = info.GetShape(); // e.g. {1, 84, 8400}
const int values = shape[1]; // maybe 84 if coco dataset
const int classes = values - 4; // 80 classes
const int count = shape[2];
float const *output_tensor = output_tensors[0].GetTensorData<float>();
for (int i = 0; i < count; i++) {
auto Value = [&](int index){
return output_tensor[count * index + i]; // 最も内側の次元がグリッドセル数(8400)であることに注意
};
// x, y, w, h, class0, class1, ...
float x = Value(0);
float y = Value(1);
float w = Value(2);
float h = Value(3);
x -= w / 2;
y -= h / 2;
for (int j = 0; j < classes; j++) { // クラス数
BoundingBox bbox;
bbox.score = Value(4 + j);
if (bbox.score > 0.5) { // 一定よりスコアが高ければ
bbox.index = j;
bbox.x = x;
bbox.y = y;
bbox.w = w;
bbox.h = h;
bboxes.push_back(bbox); // 記録する
}
}
}
// 結果の表示
for (auto &item : bboxes) {
std::cerr << "class:" << item.index << "score:" << item.score << "x:" << item.x << "y:" << item.y << "w:" << item.w << "h:" << item.h << std::endl;
}
return 0;
}
QtでGUIアプリを作る
以下、QtでGUIアプリを開発するチュートリアル寄りの記事となっています。
Qt CreatorでGUIアプリケーションを開発する手順を説明しますが、最終的に物体検出AIを組み込むと、ソースコードがかなり大きくなりますので、プログラム全体は筆者のGitHubリポジトリから取得してください。
環境構築
pacman(Arch Linux など)やapt(Ubuntu など)で、qtcreatorとQt5またはQt6の開発パッケージをインストールします。パッケージ名はディストリビューションによって異なりますが、qt5-baseとか、qtbase5-devのようなパッケージです。最近のディストリビューションではQt5だけでなくQt6のパッケージが用意されているかもしれません。もちろん新しい方をおすすめします。
Qt関連のパッケージの他には、onnxruntimeが必要ですので、インストールしておきます。
プロジェクトを作成
Qt Creator を起動します。

Qt Creator の左上の Create Project... という緑色のボタンがありますので、これをクリックします。

Qtウィジェットアプリケーションを選択します。

「QtYOLOv9」という名前で新規プロジェクトを作成します。
ビルドシステムは「qmake」と「CMake」が選べます。どちらでもいいと思いますが、筆者は qmake を使用しています。
クラス情報の画面で、MainWindowの名前を指定することができます。変更しないでそのまま進みます。

キットの選択画面では、インストールされているQtのバージョンを選ぶことができます。普通は「デスクトップ」で構いません。「Qt5」だったり「Qt6」だったりすることがあるかもしれません。そういったものが一つも選べない場合は、Qtのインストールが不完全ですので、前述のパッケージが正しくインストールされているか確認します。「Debug」と「Release」を有効にします。「Profile」はあってもなくても構いませんが、多分使いません。
完了ボタンを押すと、アプリケーションの雛形ができます。

画像表示クラスを作る
プロジェクトツリーで右クリックして、「新しいファイルを追加...」を選択します。

「C++ クラス」を選択します。
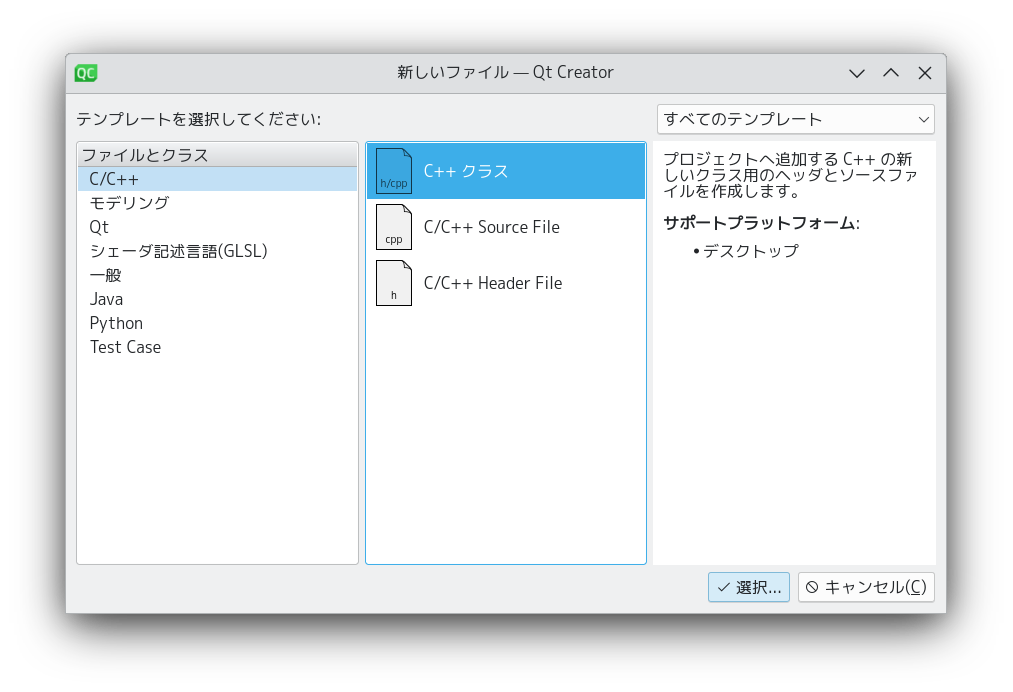
クラス名を「ImageView」、基底クラスを「QWidget」に設定します。
imageview.cpp と imageview.h が生成されます。

imageview.h を開き、class ImageView : public QWidget の行にカーソルを移動して、Alt+Enterを押すとメニューが表示されますので、「基底クラスの仮想関数を追加する」を選択します。

paintEvent(QPaintEvent *) : void という関数を追加します。

追加した関数名 paintEvent の上にカーソルを移動して、Alt+Enterを押すとメニューが表示されますので、「imageview.cpp に定義を追加」を選択します。
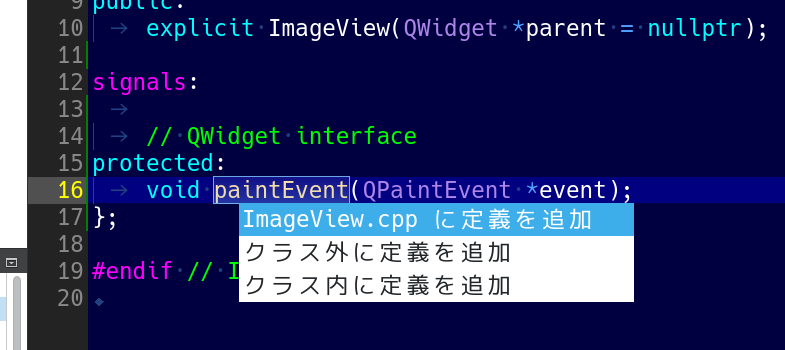
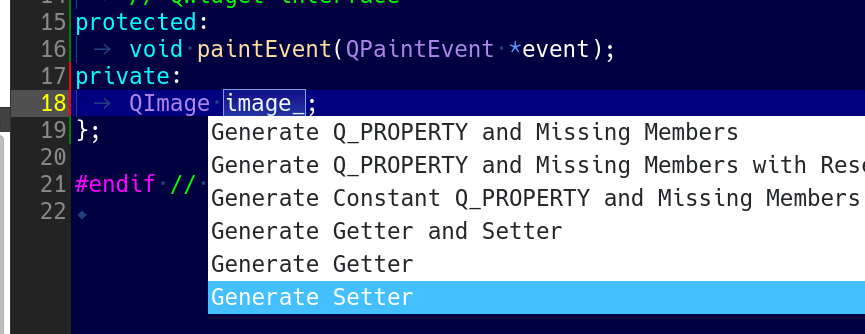
ImageView クラス内に QImage image_; というprivateメンバ変数を追加し、変数名の上にカーソルを移動して、Alt+Enterを押すとメニューが表示されますので、「Generate Setter」を選択します。
ImageView::setImage() 関数に update(); という行を追加します。
void ImageView::setImage(const QImage &newImage)
{
image_ = newImage;
update(); // 追加
}
imageview.cpp にインクルードファイルを追加します
#include <QPainter>
paintEvent 関数を実装します。
void ImageView::paintEvent(QPaintEvent *event)
{
int x = (width() - image_.width()) / 2;
int y = (height() - image_.height()) / 2;
QPainter painter(this);
painter.drawImage(x, y, image_);
}
ここまでで、次のようなコードになっていると思います。
とりあえずビルドしてみる
Ctrl+Bを押してビルドします。まだ実行はしません。エラーが出たら修正してください。ビルドが成功すると、右下に緑のプログレスバーが表示されます。
メインウィンドウを編集
プロジェクトツリーの「フォーム」から、mainwindow.ui をダブルクリックします。


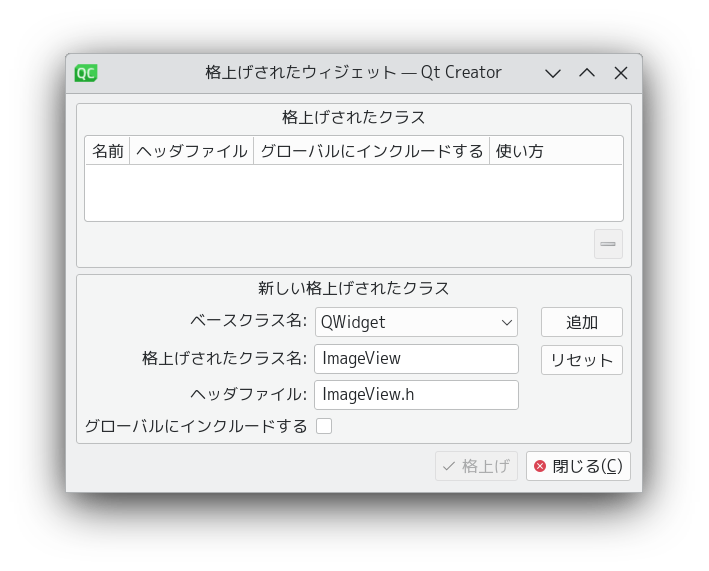
オブジェクトインスペクタの「centralwidget」を右クリックして、「格上げ先を指定...」を選択します。

「格上げされたクラス名」の欄に「ImageView」と入力し、追加ボタンを押します。さらに「格上げ」ボタンを押します。
左上のメニューバーで、「ここに入力」をダブルクリックして、「&File」と入力します。
Fileメニューを開いて、「ここに入力」をダブルクリックし、「&Open...」と入力します。
ここまでで、メニューバーができました。

この Open メニューが選択された時に実行される関数を実装します。

アクションエディタから、メニュー項目を右クリックして、「スロットへ移動...」を選択します。
triggered() を選択してOKを押します。
左のツールバーから「編集」ボタンを押して、ソースコード編集画面に移ります。

mainwindow.cppを開き、void MainWindow::on_action_Open_triggered() 関数を実装します。
void MainWindow::on_action_Open_triggered()
{
QString path = QFileDialog::getOpenFileName(this, "Open Image");
if (path.isEmpty()) return;
QImage image(path);
ui->centralwidget->setImage(image);
}
物体検出のコードを実装
前述の通り、推論機能を実装したアプリケーション全体のソースコードは、筆者のGitHubリポジトリから取得してください。以下、肝心な部分のみ解説します。
この on_action_Open_triggered() 関数の中で、画像を読み込んだら、AIモデルで推論を行い、その結果を描画します。
YOLOモデルの準備がまだなら読み込む
if (!isModelReady()) {
if (!loadModel()) {
QMessageBox::critical(this, "Error", "Failed to load model");
close();
return;
}
}
物体検出
auto bboxes = m->detector.inference(m->image); // inference() は std::optional を返す
ここで、bboxes は、std::optional<std::vector<BoundingBox>> です。optionalオブジェクトなので、推論が失敗したときはstd::nullopt、成功したときはバウンディングボックスのvectorを得られます。
検出結果が有効ならバウンディングボックスを描画する
if (bboxes) {
QPainter painter(&m->image);
painter.setPen(Qt::cyan); // 矩形の色
painter.setBrush(Qt::NoBrush); // 塗りつぶさない
for (auto const &bbox : *bboxes) {
painter.drawRect(bbox.rect); // 矩形を描画
}
}
入力テンソルの作成
最も肝心なコードの実装がまだでした。推論を行う前に、画像から入力テンソルを作成する必要があります。
最初にC++でONNXファイルを読み込むコードを実装したとき、入力テンソルは以下のようなものでした。
std::vector<float> input_tensor_values(N * C * H * W);
これに、画像データを書き込みます。
入力画像を 640 * 640 にリサイズします。
QImage img = image.convertToFormat(QImage::Format_RGB888).scaled(W, H, Qt::IgnoreAspectRatio, Qt::FastTransformation);
画素値を[0, 1]に正規化し、Packed RGB形式からPlanar RGB BGR形式に変換します。
float *B = input_tensor_values.data() + H * W * 0;
float *G = input_tensor_values.data() + H * W * 1;
float *R = input_tensor_values.data() + H * W * 2;
for (int y = 0; y < H; y++) {
uint8_t const *src = img.scanLine(y);
for (int x = 0; x < W; x++) {
R[W * y + x] = src[3 * x + 0] / 255.0f;
G[W * y + x] = src[3 * x + 1] / 255.0f;
B[W * y + x] = src[3 * x + 2] / 255.0f;
}
}
【2025-01-07訂正】 入力テンソルはRGBではなくBGRが正しいです。教えてくださった方ありがとうございます!
最初の推論プログラムにこれを組み込み、GUIアプリと統合し、画像ファイルを開いたときに、推論を実行するようにすれば完成です。
