これは MIERUNE AdventCalendar 2022 23日目の記事です。
昨日は @nokonoko_1203 さんによる 指定した領域のラスタータイルをダウンロードしたりGeoTIFFに変換してくれるPythonパッケージをPyPIで公開しました! - Qiita でした。
概要
-
地名集日本(GAZETTEER OF JAPAN) | 国土地理院
- 国土交通省国土地理院によるデータ
- 4,000以上の地名を収録
- 経緯度や種別も掲載
- 元データはPDF
- → CSV, JSON形式へ変換し公開: sorami/gazetter-of-japan
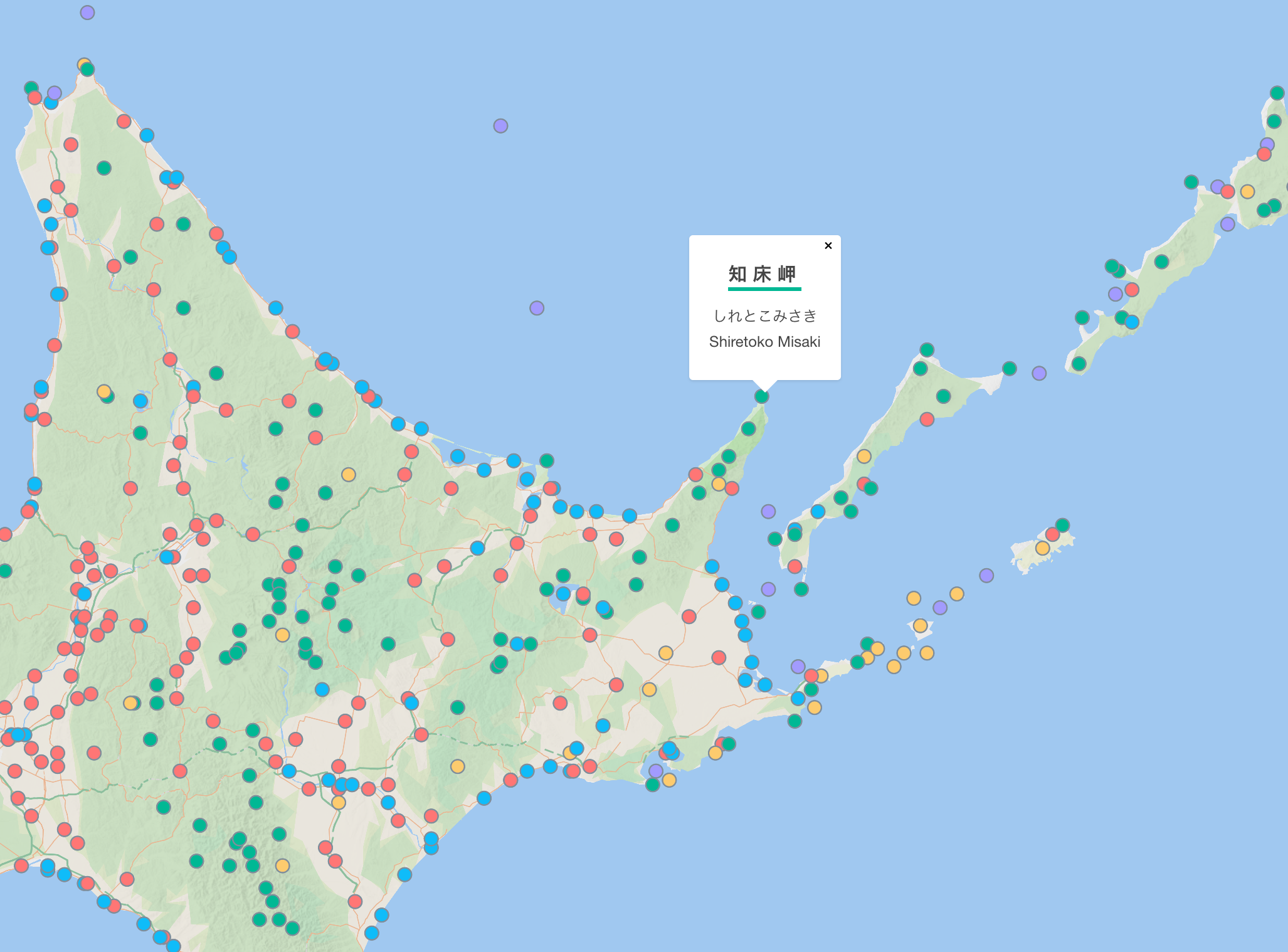
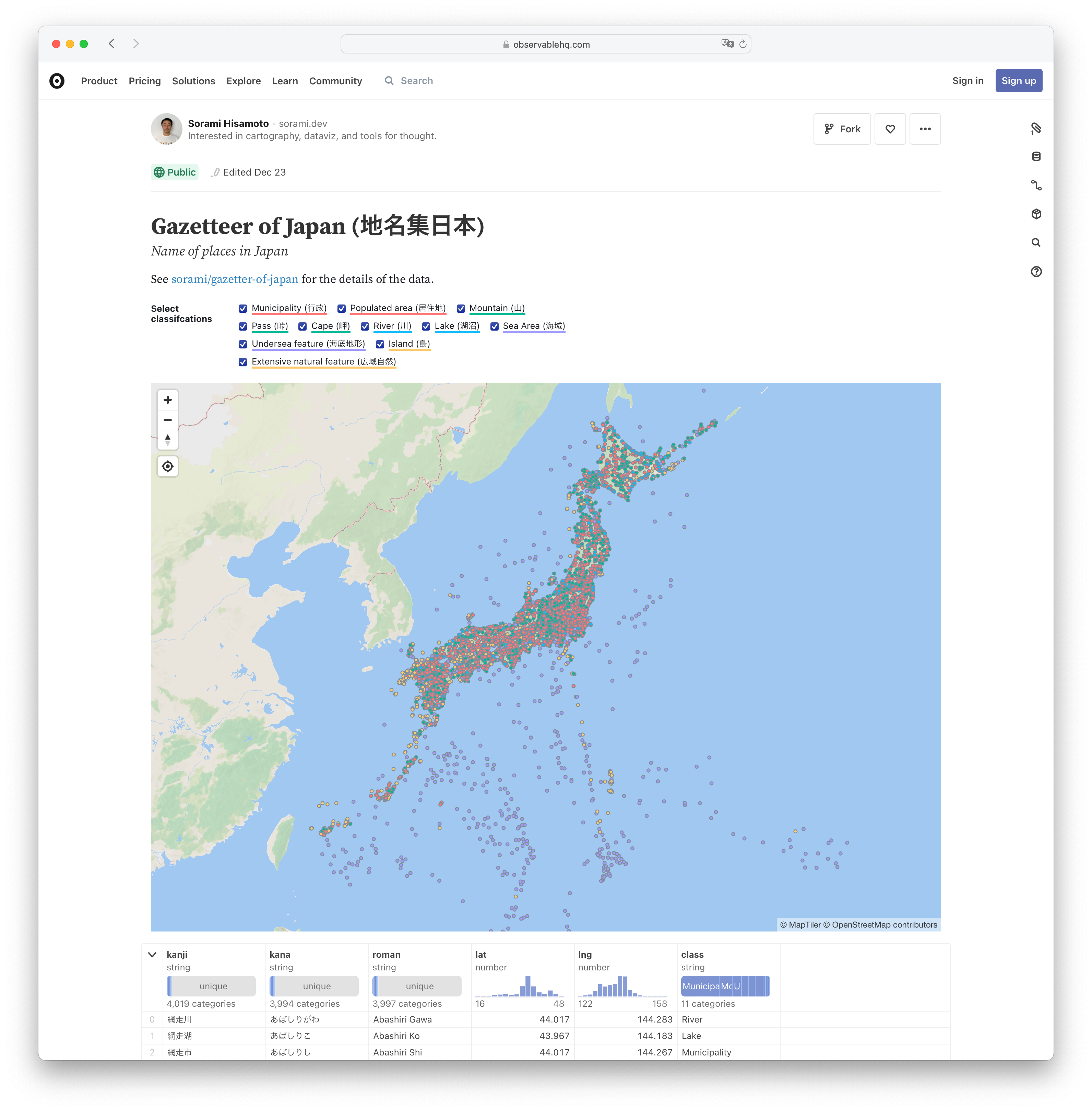
- データと前処理コード: sorami/gazetter-of-japan: Japanese place name dictionary
- インタラクティブな可視化: Gazetteer of Japan (地名集日本) | Observable
当データを利用する際は「出典の記載」「加工した旨の明記」を行なってください。
記載例:
データ: 国土地理院「地名集日本」を加工して作成
出典: https://www.gsi.go.jp/kihonjohochousa/gazetteer.html
詳しくは国土地理院コンテンツ利用規約をご覧ください。
当記事やGitHubレポジトリ自体への言及は必須ではありません(していただけたら喜びます!)。
著者は国土地理院と関連していません。当データと記事の公開については、地理院へ確認しており、上記利用規約へ従えば問題ないという返答をいただいております。
国土地理院「地名集日本」とは
「国土交通省 国土地理院」は、日本の行政機関で、国土の測量などを行なっています。
この国土地理院と海上保安庁海洋情報部により刊行されているのが「地名集日本」です。
これには日本国の行政、居住、自然、海底地形等の標準化された地名情報が総合的にまとめられ、継続的に更新されています。
文書の「概要」には、その内容について以下のように述べられています:
集録されている地名は,国土地理院作成の100万分1国際図及び海上保安庁作成の350万分1国際海図と100万分1海底地形図に記載されている地名を更新したものである。また,国際水路機関とユネスコ政府間海洋学委員会が共同で設置した海底地形名小委員会(SCUFN)で承認された海底地形名等を追加し,約4,100件の地名が集録されている。行政名については,地方自治体が定めた名称を記載した。また,自然地名については,国土地理院と海上保安庁海洋情報部の両機関で設置した「地名等の統一に関する連絡協議会」により標準化されたものが大部分であり,それらについては,その名称を記載した。
文書には地名の表が掲載されており、以下の列で構成されています:
-
Grid: メッシュ・コード- 標準地域メッシュ(第1次地域区画)
- 国土を約80km辺のグリッドに区切ったもの
-
Japanese(Kanji): 日本語表記(漢字) -
Japanese(Kana): 日本語表記(かな) -
Romanized Japanese: ローマ字表記 -
Latitude: 緯度- 60進法表記(度・分)
- 例:
44°01'
-
Longitude: 経度- 60進法表記(度・分)
- 例:
144°17'
-
Classification: 種別- 詳細は文書の表-Bを参照のこと

図: 「地名集日本」 表-B, https://www.gsi.go.jp/common/000238259.pdf, 2022-12-23取得
ちなみに、英称に「Gazetteer(ガゼッティア)」とありますが、これは「地名の辞書」を指す語です(地名集 - Wikipedia, Gazetteer - Wikipedia)。
データの詳細
「地名集日本」は国土地理院ウェブサイトで公開されていますが、これはPDF形式です。
このPDFファイルをパースし、CSV, JSONファイルへ変換しました。いわゆる「餅から米」です。
CSV: gazetteer-of-japan.csv
kanji,kana,roman,lat,lng,class
網走川,あばしりがわ,Abashiri Gawa,44.017,144.283,River
網走湖,あばしりこ,Abashiri Ko,43.967,144.183,Lake
網走市,あばしりし,Abashiri Shi,44.017,144.267,Municipality
安倍川,あべかわ,Abe Kawa,34.933,138.400,River
我孫子市,あびこし,Abiko Shi,35.867,140.033,Municipality
安平町,あびらちょう,Abira Cho,42.767,141.817,Municipality
安平川,あびらがわ,Abira Gawa,42.617,141.733,River
安房峠,あぼうとうげ,Abo Toge,36.200,137.583,Pass
阿武町,あぶちょう,Abu Cho,34.500,131.467,Municipality
...
JSON: gazetteer-of-japan.json
[
{
"kanji": "網走川",
"kana": "あばしりがわ",
"roman": "Abashiri Gawa",
"lat": 44.017,
"lng": 144.283,
"class": "River"
}
]
含まれる列
-
kanji: 日本語表記(漢字) -
kana: 日本語表記(かな) -
roman: ローマ字表記 -
lat: 緯度- 10進法表記, 小数第3位まで
-
lng: 経度- 10進法表記, 小数第3位まで
-
class: 種別MunicipalityPopulated areaMountainPassCapeRiverLakeSea AreaUndersea featureIslandExtensive nature feature
元のデータにある「メッシュ・コード」列は、このデータには含んでいません。緯度経度は把握できるため、必要であればそこから別途、一意に算出することが可能です。
統計値
2022-12-22取得PDFデータをもとにした値です。
総数: 4,149
- 元データの表で4,123行
- 加えて、26の別称(後述)
種別ごとの行数
- Municipality: 1,794
- Mountain: 593
- Undersea feature: 439
- River: 326
- Island: 312
- Cape: 182
- Populated area: 182
- Extensive natural feature: 115
- Sea Area: 105
- Lake: 51
- Pass: 50
重複する名前・読み
例えば、「駒ヶ岳」は7件存在します。
多数あります。一覧は gazetter-of-japan/stats.ipynb をご覧ください。
長い名前
- マーカス・ウエイク海山群
- パレスベラ断裂帯地形区
- エサオマントッタベツ岳
- カムイエクウチカウシ山
- 千島・カムチャツカ海溝
- ...
gazetter-of-japan/stats.ipynb で確認しています、そちらもご覧ください。
前処理の詳細
PDFをパースしCSV,JSONへ出力する全過程(手動での対応含む)は gazetter-of-japan/extract.ipynb で確認できます。
PDFからの情報取得にはPythonライブラリpdfminer.sixを利用しました。表ページは、ある程度の一貫した構造はありましたが、一部のページでは手動対応が必要でした(後述する「異体字などの取り扱い」など)。
緯度経度の変換
「緯度経度」は、元データでは60進法であったものを、10進法へ変換しました。
この時、元は「度・分」までの情報(「秒」はない)だったため、少数第3位で丸めた値になっています(1/60 = 0.0166666667 のため、第3位が妥当と判断)。
例: 44°01' → 44.017
異体字などの取り扱い
いくつかの箇所では、漢字表記が文字列ではない形になっています。これは、その文字が異体字であったりして正しく出力できないためと考えられます。具体的には以下の地名は、行政のウェブサイトなどを参考に、適切と想定される文字へ手動で書き換えて当データへ収録しました:
-
芦屋町 -
芦屋市 -
葛城市 -
御杖村 -
薩摩川内市 -
紗那村
処理の詳細は gazetter-of-japan/extract.ipynb をご覧ください。
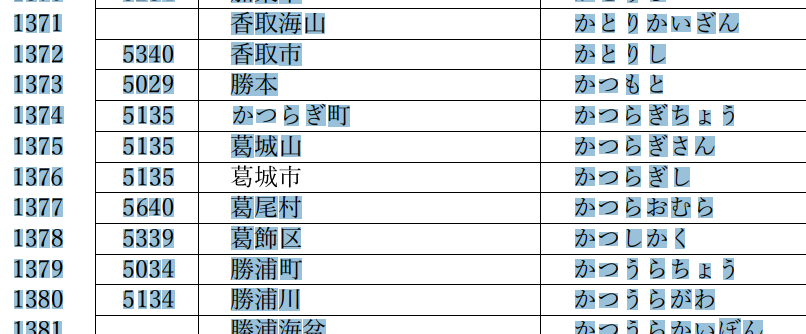
図: 「地名集日本」 p.35, https://www.gsi.go.jp/common/000238259.pdf, 2022-12-23取得
別称の分割
一部の地名は、括弧書きで別称が記載されています。
例: 烏帽子岳(乳頭山), えぼしだけ(にゅうとうざん), Eboshi Dake (Nyuto Zan)
この時、 名称(別称) という形式だけでなく、 火山(硫黄)列島 というように文字列中に別称を含むものや、漢字表記はひとつだが読みが複数あるもの( 蔵王山, ざおうざん(ざおうさん), Zao Zan (Zao San) )もある点に注意が必要です。
当データではこの括弧書きを分割し、それぞれ別エントリとして収録しました。元の併記された形は収録していません。
処理の詳細は gazetter-of-japan/extract.ipynb をご覧ください。
過去の事例
Hidekazu Aoshimaさんにより、地名集日本データが公開されています:
- 地名集日本(GAZETTEER OF JAPAN)|オープンデータ共有&ダウンロード|LinkData
- 地名集日本(GAZETTEER OF JAPAN)(gazetteer) - Linked Data API Navi
これには3,881件が含まれています。当記事と異なるデータ量ですが、これは、元となるデータの時点が違うことや、先述した異体字等で表記されている行を含むページの取り扱いが関連しているようです。他には、先述した括弧書きでの別称は、このデータでは分割はされておらず元データと同じ形式になっています。カラムとして、当記事のデータには含めなかった「メッシュコード」があります(一部の行には無し: 元データで前行と同じ場合は空になっているからだと思います)。加えて、「更新ステータス」「更新日」列も追加されています(修正, 2018-03-06, 削除, 2018-03-06, など)。また、ライセンスがパブリックドメインとなっていますが、これは国土地理院コンテンツ利用規約に合わせて利用の際は注意が必要かと思います。
他の事例としては、muramototomoyaさんによる地図上のプロット例がありました:
おわりに
奈良先端科学技術大学院大学(NAIST)の大内啓樹さんらは、コンピューターで人間の言葉を扱う「自然言語処理」と「地理空間情報」の融合領域を開拓すべく取り組んでおられます。
NAISTと、私の所属する位置情報技術企業MIERUNEは、定期的に勉強会を開催しています。先日、そこで発表するための調査をしているときに「地名地図日本」を知りました。
多くの機械処理にはデータが欠かせません。このデータも、利便性の高い形へ変換し公開することで、より多くの人が利用できるのではないかと思い、餅から米してみました。
「地名地図日本」という貴重なデータが活用されることの一助となれば幸いです。
次のページで、データを地図上でインタラクティブに確認できます: Gazetteer of Japan (地名集日本) | Observable
明日は @Kanahiro さんです!お楽しみにー!