表形式のデータを分析や開発に適した構造するとき、既存の Office の機能だけではどうしても加工に時間がかかったり、そもそも想定する加工が難しいことはないでしょうか。
また、時間のないときに限ってこのデータ加工ってどういうキーワードで調べればいいの、と途方にくれたりします。
本記事は筆者がとあるプロジェクトで実施した Excel のデータ加工の方法と、必要な環境の準備手順についてまとめてみました。
同じようなデータ処理をしたい!という人は参考にしてみてください。
なお、業務端末が Windows なので本記事の実施内容は Windows 上で実施した内容です。
やりたかったのは以下の 3 つの処理です。
ワイドフォーマット(横持ち形式)の表データをロングフォーマット(縦持ち形式)にする
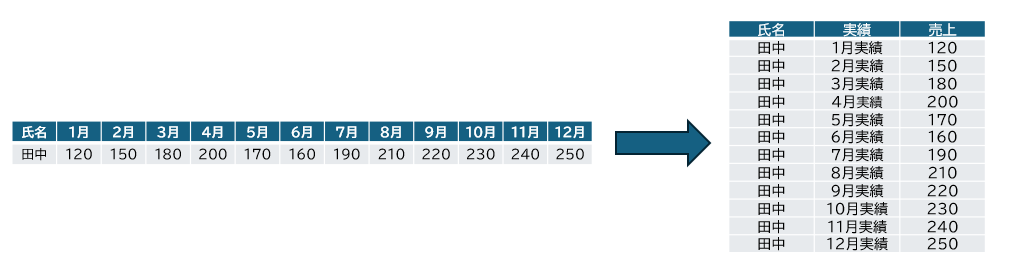
余談ですが、筆者は上記のようなデータの持ち方に名称がついていることを知りませんでした。
記事執筆にあたり調査したところ、文部科学省の情報技術の資料にこの変換について詳しい言及がありました。
情報とデータサイエンス:ロングフォーマットとワイドフォーマット
https://www.mext.go.jp/content/20200702-mxt_jogai01-000007843_004.pdf
文部科学省
https://www.mext.go.jp/
複数の情報が含まれるセルの内容を、行に分割する
下図のように特定の記号 ("," など) で区切られる情報 (資格) のセルを分割、分割されたデータを縦に積み上げて一つの列にまとめる
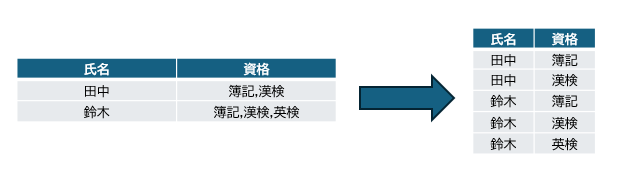
特定の文字列とそれ以外の情報をそれぞれの列に保持する

これらの処理ができるように、まずはWindows 環境上に Python インタプリタや pip ライブラリなどのインストールを実施していきます。
環境準備
Windows 環境に Python をインストール。初心者向けのドキュメントの手順を参考にします。
Windows での Python (初心者向け) | Microsoft Learn
https://learn.microsoft.com/ja-jp/windows/python/beginners
[スタート] - [Microsoft Store] を入力して、
適切なバージョンをインストールする(ここでは 3.13 をインストールしてきます。)
Status of Python versions
https://devguide.python.org/versions/
python --version
Python 3.13.0
pandasをインストールします。そのまま PowerShell で以下のコマンドを実行。
うまくいけば後述の出力例のように依存関係にあるパッケージもインストールされてきます。
pip install pandas
> pip install pandas
Defaulting to user installation because normal site-packages is not writeable
Collecting pandas
Downloading pandas-2.2.3-cp313-cp313-win_amd64.whl.metadata (19 kB)
Collecting numpy>=1.26.0 (from pandas)
Downloading numpy-2.1.3-cp313-cp313-win_amd64.whl.metadata (60 kB)
Collecting python-dateutil>=2.8.2 (from pandas)
Downloading python_dateutil-2.9.0.post0-py2.py3-none-any.whl.metadata (8.4 kB)
Collecting pytz>=2020.1 (from pandas)
Downloading pytz-2024.2-py2.py3-none-any.whl.metadata (22 kB)
Collecting tzdata>=2022.7 (from pandas)
Downloading tzdata-2024.2-py2.py3-none-any.whl.metadata (1.4 kB)
Collecting six>=1.5 (from python-dateutil>=2.8.2->pandas)
Downloading six-1.16.0-py2.py3-none-any.whl.metadata (1.8 kB)
Downloading pandas-2.2.3-cp313-cp313-win_amd64.whl (11.5 MB)
---------------------------------------- 11.5/11.5 MB 2.1 MB/s eta 0:00:00
Downloading numpy-2.1.3-cp313-cp313-win_amd64.whl (12.6 MB)
---------------------------------------- 12.6/12.6 MB 2.7 MB/s eta 0:00:00
Downloading python_dateutil-2.9.0.post0-py2.py3-none-any.whl (229 kB)
Downloading pytz-2024.2-py2.py3-none-any.whl (508 kB)
Downloading tzdata-2024.2-py2.py3-none-any.whl (346 kB)
Downloading six-1.16.0-py2.py3-none-any.whl (11 kB)
Installing collected packages: pytz, tzdata, six, numpy, python-dateutil, pandas
WARNING: The scripts f2py.exe and numpy-config.exe are installed in 'C:\Users\btsonooharu\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.13_qbz5n2kfra8p0\LocalCache\local-packages\Python313\Scripts' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed numpy-2.1.3 pandas-2.2.3 python-dateutil-2.9.0.post0 pytz-2024.2 six-1.16.0 tzdata-2024.2
上記の表示を確認したら、インストールができているか確認してみましょう。
pip list を実行して以下のように依存パッケージも含めてインストール済みのライブラリが表示される場合は、問題ありません。
おめでとうございます。
pip list
Package Version
--------------- -----------
numpy 2.1.3
pandas 2.2.3
pip 24.2
python-dateutil 2.9.0.post0
pytz 2024.2
six 1.16.0
tzdata 2024.2
pip install の実行時に以下のメッセージが出ており、原因特定よりまずはライブラリを使えることを優先したい!という場合は、いったん必要なライブラリをダウンロードしてから、pip install することで回避ができるかもしれません。
Could not fetch URL https://pypi.org/simple/pprint/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with url: /simple/pprint/ (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)'))) - skipping
(うまくいかないとき)必要な whl ファイルをダウンロード、ファイル指定で pip install
オフラインで必要なライブラリをダウンロードして回避します。
pandas · PyPI
https://pypi.org/project/pandas/#files
依存関係などの解決のため、必要だったのは下記のとおり。
pip install --no-index --no-deps .\pandas-2.2.3-cp311-cp311-win_amd64.whl
pip install --no-index --no-deps .\numpy-2.1.2-cp311-cp311-win_amd64.whl
pip install --no-index --no-deps .\pytz-2024.2-py2.py3-none-any.whl
pip install --no-index --no-deps .\python_dateutil-2.9.0.post0-py2.py3-none-any.whl
pip install --no-index --no-deps .\six-1.16.0-py2.py3-none-any.whl
上記で環境変数に下記追加
C:\Users\*********\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\Scripts
そのほか実施したこと
筆者は vscode をインストールして拡張機能だけ導入しました。
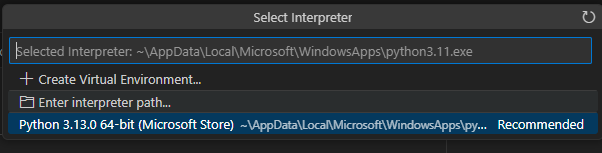
Ctrl + Shift + p でコマンドパレットを開き、"Python: Select Interpriter" を選択すると下記のスクリーンショットのように Microsoft Store でインストールしたインタプリタが見えてきますので、選択しておきましょう。
Download Visual Studio Code - Mac, Linux, Windows
https://code.visualstudio.com/download

Excel ファイルを読み込むためのライブラリ (openpyxl) のインストール
pip で openpyxl を追加インストールします。
pip install openpyxl
> pip install openpyxl
Defaulting to user installation because normal site-packages is not writeable
Collecting openpyxl
Downloading openpyxl-3.1.5-py2.py3-none-any.whl.metadata (2.5 kB)
Collecting et-xmlfile (from openpyxl)
Downloading et_xmlfile-2.0.0-py3-none-any.whl.metadata (2.7 kB)
Downloading openpyxl-3.1.5-py2.py3-none-any.whl (250 kB)
Downloading et_xmlfile-2.0.0-py3-none-any.whl (18 kB)
Installing collected packages: et-xmlfile, openpyxl
Successfully installed et-xmlfile-2.0.0 openpyxl-3.1.5
pandas.read_excel — pandas 2.2.3 documentation
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
データ処理
環境設定が終わったら、テスト用のデータを作成してどこかに配置していよいよデータの処理ができるようになります。
以降のスクリプトでは以下のフォルダに配置がされている前提での内容です。
C:\Users\(username)\Documents\
ワイドフォーマット(横持ち形式)の表データをロングフォーマット(縦持ち形式)にする
qiitatest.xlsx の内容:

import pandas as pd
df = pd.read_excel(r'C:\Users\(username)\Documents\qiitatest.xlsx', engine="openpyxl")
melted_df = df.melt(id_vars=['氏名'], var_name='実績', value_name='売上')
print(melted_df)
結果
氏名 実績 売上
0 田中 1月 120
1 田中 2月 150
2 田中 3月 180
3 田中 4月 200
4 田中 5月 170
5 田中 6月 160
6 田中 7月 190
7 田中 8月 210
8 田中 9月 220
9 田中 10月 230
10 田中 11月 240
11 田中 12月 250
pandas.DataFrame.melt — pandas 2.2.3 documentation
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.melt.html
"," などの区切り文字で複数の情報が含まれるセルの内容を、行に分割する
qiitatest2.xlsx の内容:

import pandas as pd
df = pd.read_excel(r'C:\Users\(username)\Documents\qiitatest2.xlsx', engine="openpyxl")
# 保有資格を分割して新しいDataFrameを作成
df_new = df.set_index(['氏名'])['資格'].str.split(',', expand=True).stack().reset_index(level=1, drop=True)
print(df_new)
列を分割し、特定の文字列とそれ以外の情報をそれぞれの列に保持する
qiitatest3.xlsx の内容:

import pandas as pd
df = pd.read_excel(r'C:\Users\(username)\Documents\qiitatest3.xlsx', engine="openpyxl")
levels = ['大阪府', '東京都']
def split_certification(row):
for level in levels:
if level in row:
return pd.Series([level, row.replace(level, '').strip()])
return pd.Series([None, row])
# 「住所」列を「住所」と「都道府県」に分割
df[['都道府県', '住所']] = df['住所'].apply(split_certification)
print(df)
おわりに
今回は取り急ぎのデータ加工用に作ったスクリプトを、今後ほかのチームメンバーが活用しやすいように記事にまとめてみました。
使用している各機能の詳細な仕様については、別途ライブラリのドキュメントを参照してみてください。
実際の業務では、前述のデータ構造が複合していたり、他の加工が必要になったりしますが、データ加工の足掛かりの一つとして、この記事が誰かの役に立てばうれしいです。