更新履歴
- 2024-02-17: RAG機能を追加しました。ChatGPTにPDFのページを検索させ、その検索結果を参照させながらQAや要約などの任意の生成処理を行わせることができます。
数クリックで要約完了、後は好きに質問を
PDFファイルを与えるとテキストを抽出してくれ、その内容をChatGPTに要約させたり、好きに質問して読み解かせたりできるアプリを公開します(下図参照)。
最大の特徴は、アプリ用のサーバーを立てる必要がないことです。
アプリを使うには1個のHTMLファイルをブラウザで開くだけ。そう、ただそれだけ。(Apple風)
HTMLファイルの置き場所はデスクトップでもいいですし、どこかのサイトでも。
アプリを自分用に改造することもしやすいでしょう。
- 数クリックで、PDF論文を落合フォーマットに従って要約させた例:

特徴:
- PDFファイルからのテキスト抽出機能
- 抽出したテキストを用いた対話型チャット機能
- いわゆるRAG機能(ChatGPTにPDFのページを検索させ、その検索結果を参照させながらQAなどを行わせることができる)
- OpenAI APIまたはAzure OpenAI Serviceをバックエンドとして利用可能
- URLにチャット履歴を保存可能(デフォルトではオフ)
- 1ファイルからなるシンプルさ。アプリサーバー不要。自分用に改造しやすい。MITライセンス。
- ChatGPT APIにアクセスする以外は、全てブラウザのメモリ内で処理が行われる(セキュアである)。
準備
それでは本アプリの使い方を説明していきます。
まずは準備です。次の2つを用意するだけです。
- ChromeブラウザかEdgeブラウザ(アプリの動作確認済みブラウザ)
- 次のどちらかのChatGPT APIサービス(有償)のAPIキー
- OpenAI APIキー(sk-...という形式のアレ)
- Azure OpenAI ServiceのAPIキーとアクセス情報
使い方
1. アプリの起動
次のいずれかの方法でアプリを起動します。
- 本アプリのHTMLファイルを下記からダウンロードしてローカルにおきChromeかEdgeで開く。
- 本アプリのHTMLファイル: https://github.com/sonoisa/chatpdf/blob/main/chatpdf.html の右上あたりにあるDownload raw fileボタンをクリックすればダウンロードできます。
- または、同HTMLが置かれた下記のサイトをChromeかEdgeで開く。
-
https://huggingface.co/spaces/sonoisa/chatpdf
※注意: huggingface spaces版ではチャット履歴保存機能は動きません。 - https://sonoisa.github.io/chatpdf/
-
https://huggingface.co/spaces/sonoisa/chatpdf
アプリの起動には40〜60秒かかりますので、しばしお待ちください。
(後で解説するようにGradio Liteの起動待ちです)
次の画面(設定画面)が表示されたら起動完了です。
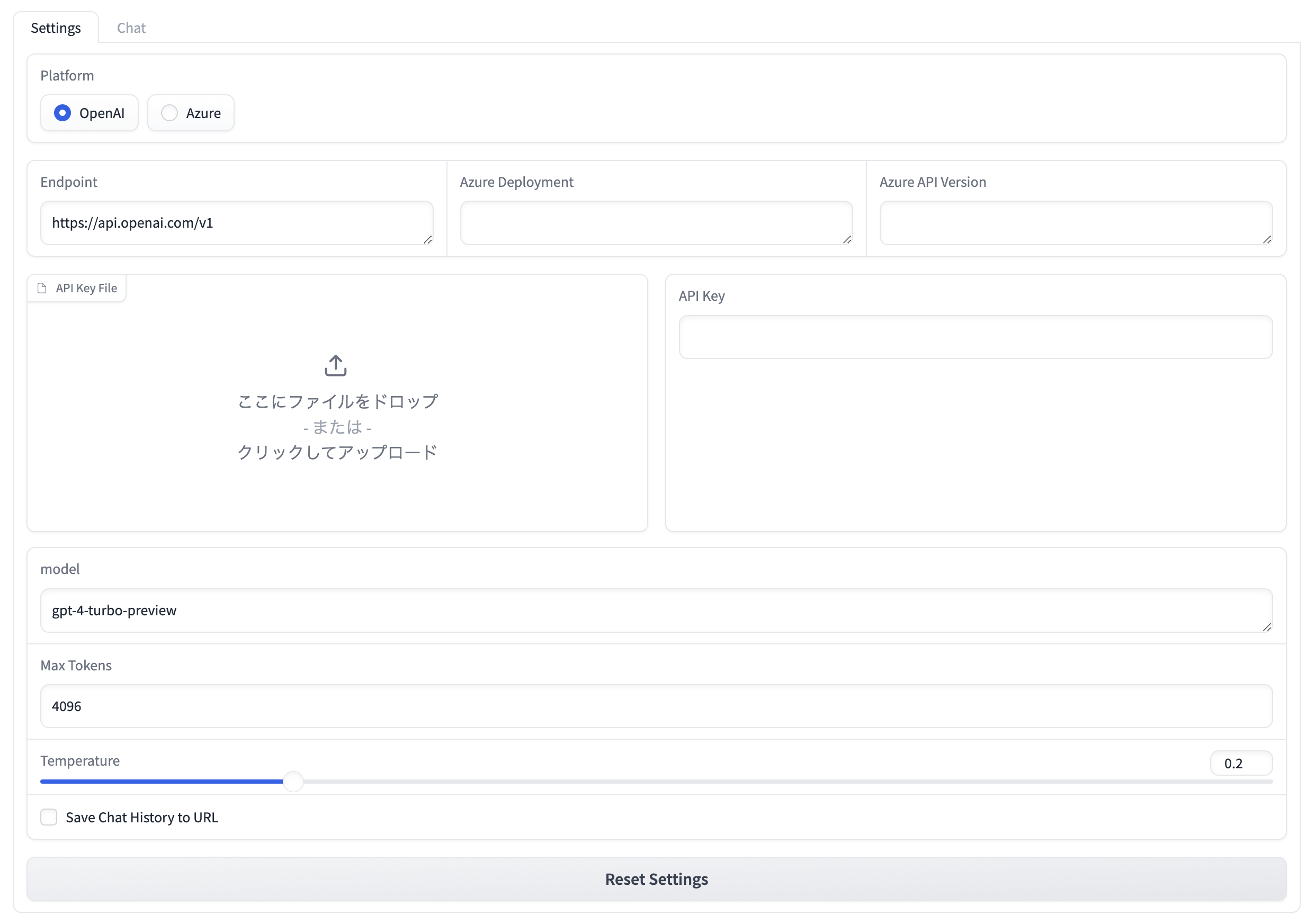
2. APIキー等の設定
まずAPIを利用するための設定を行います。
OpenAI APIを利用する場合は、APIキーの設定をすればあとはデフォルトのままで大丈夫です。
各設定項目の意味は下図の通りです。
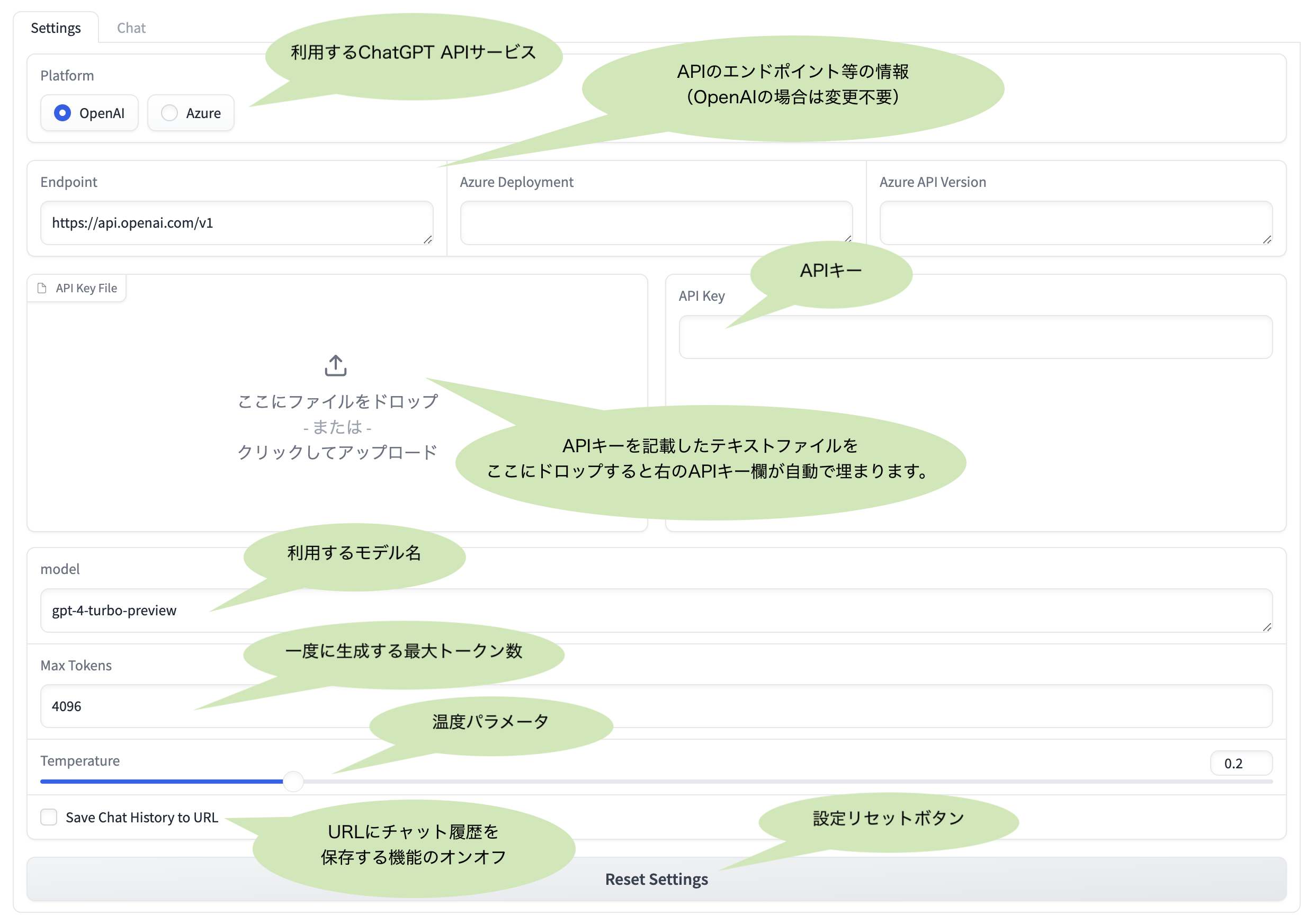
(設定項目のMax TokensとTemperatureの意味はOpenAI APIの説明をご参照のこと)
APIキーの設定方法:
- OpenAI APIを利用する場合は、"API Key"の欄にAPIキーを入力するか、APIキーを記載したテキストファイル(例えばopenai_api_key.txt)を"API Key File"にドロップして下さい。
- Azure OpenAI Serviceを利用する場合は、"API Key"の他に、"Endpoint"と"Azure Deployment"と"Azure API Version"にお使いの設定を入力して下さい。
例えば、OpenAIを利用する場合、APIキーを設定すれば、次のような画面になっているはずです。
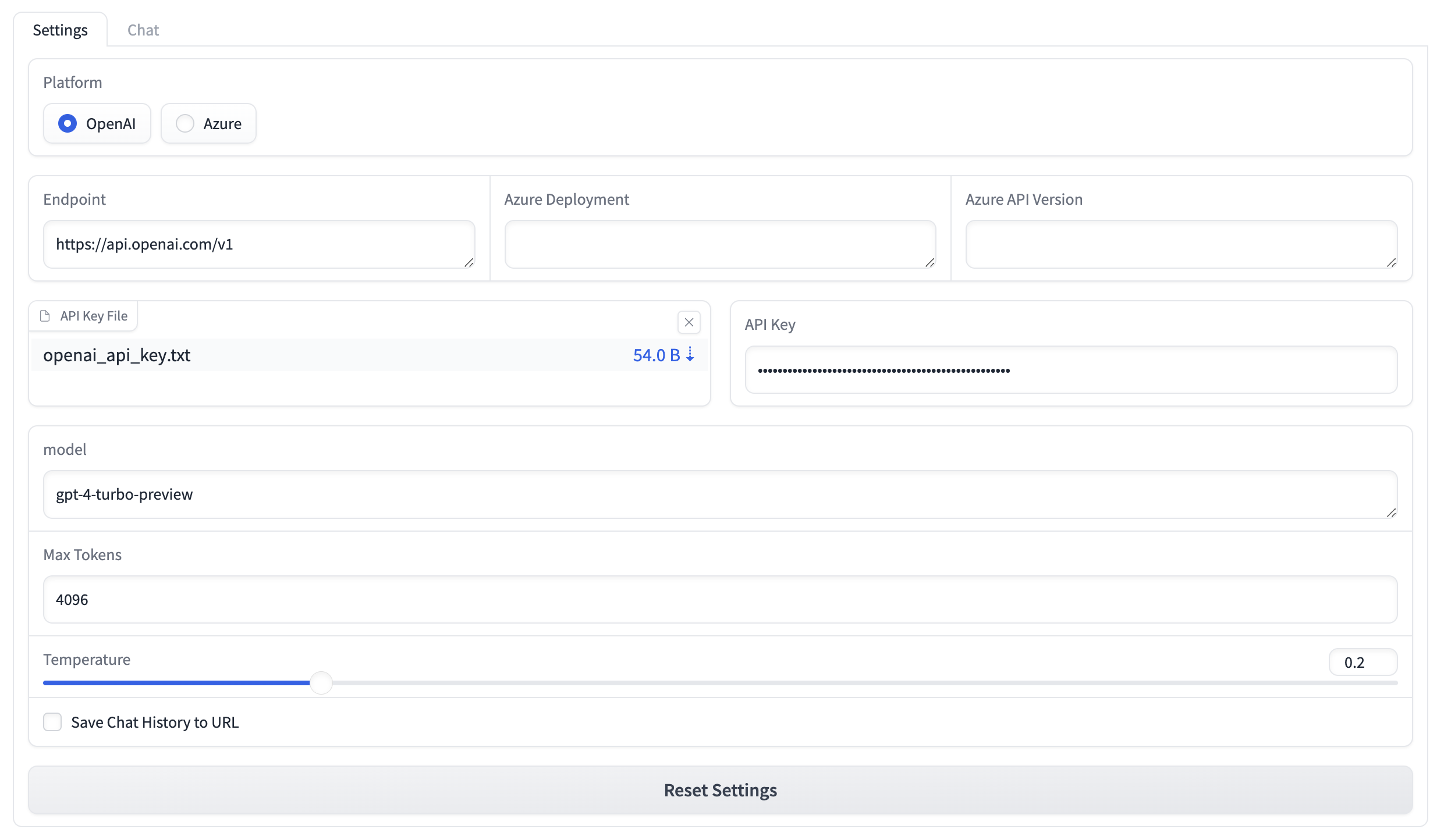
なお、APIキー以外の設定値はブラウザ(localStorage)に記憶されますので、次回起動時はAPIキーのみ設定するだけで済みます。
3. PDFを読み込み、要約など任意のチャット
アプリの一番上にある"Chat"をクリックすると下図のチャット画面に切り替わります。
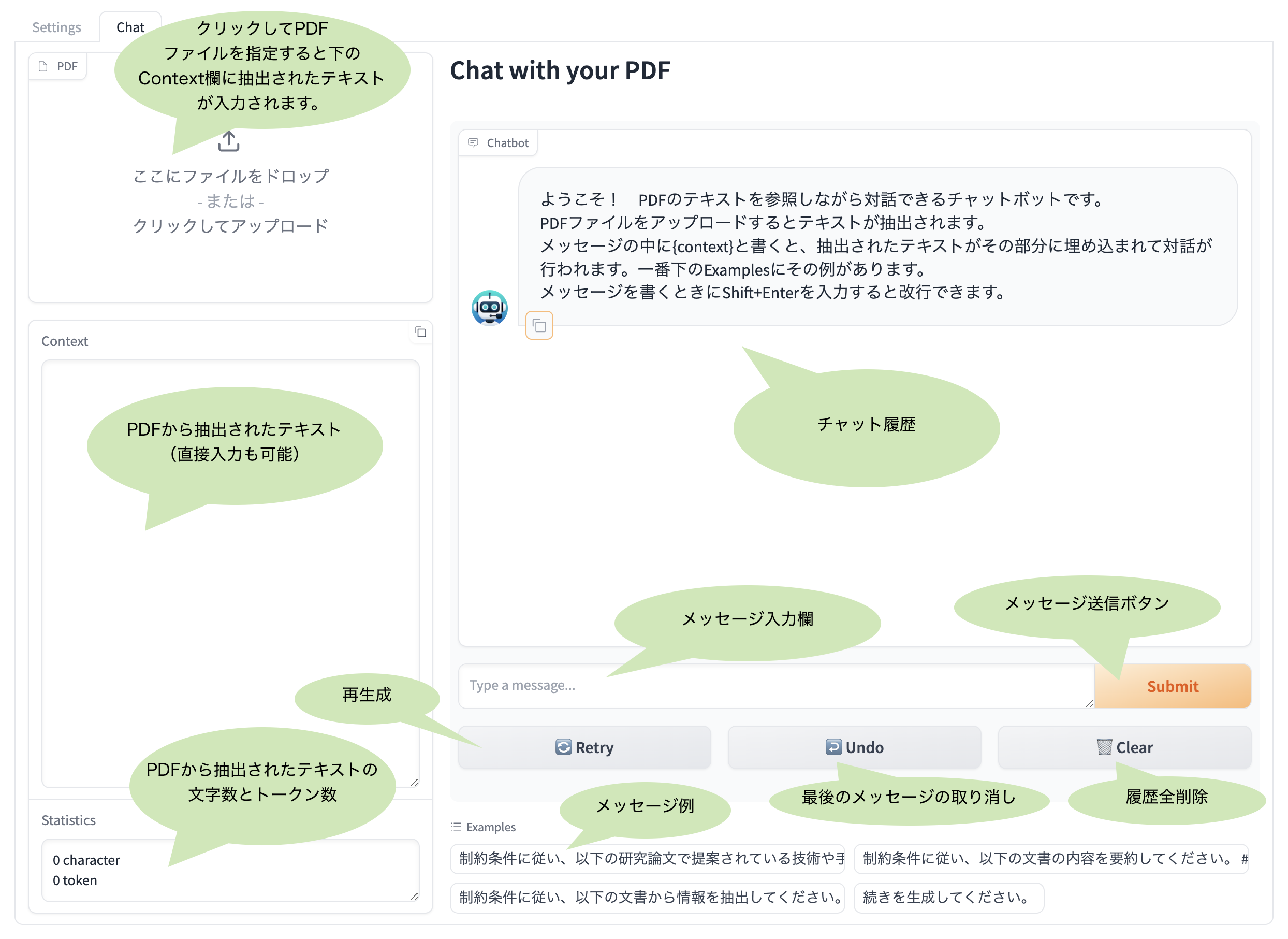
あとは直感で使えるでしょう。
まず、PDFからテキストを抽出します。
左上の"PDF"のエリアをクリックして、PDFファイルを選択すると下図のように"Context"欄に抽出されたテキストが表示されます。なぜかPDFファイルを直接ドロップする方法が機能しないので、エリアをクリックする方法を用いてください。
この抽出処理はブラウザのメモリ内で全て行われます(仕組みの解説は後述)。
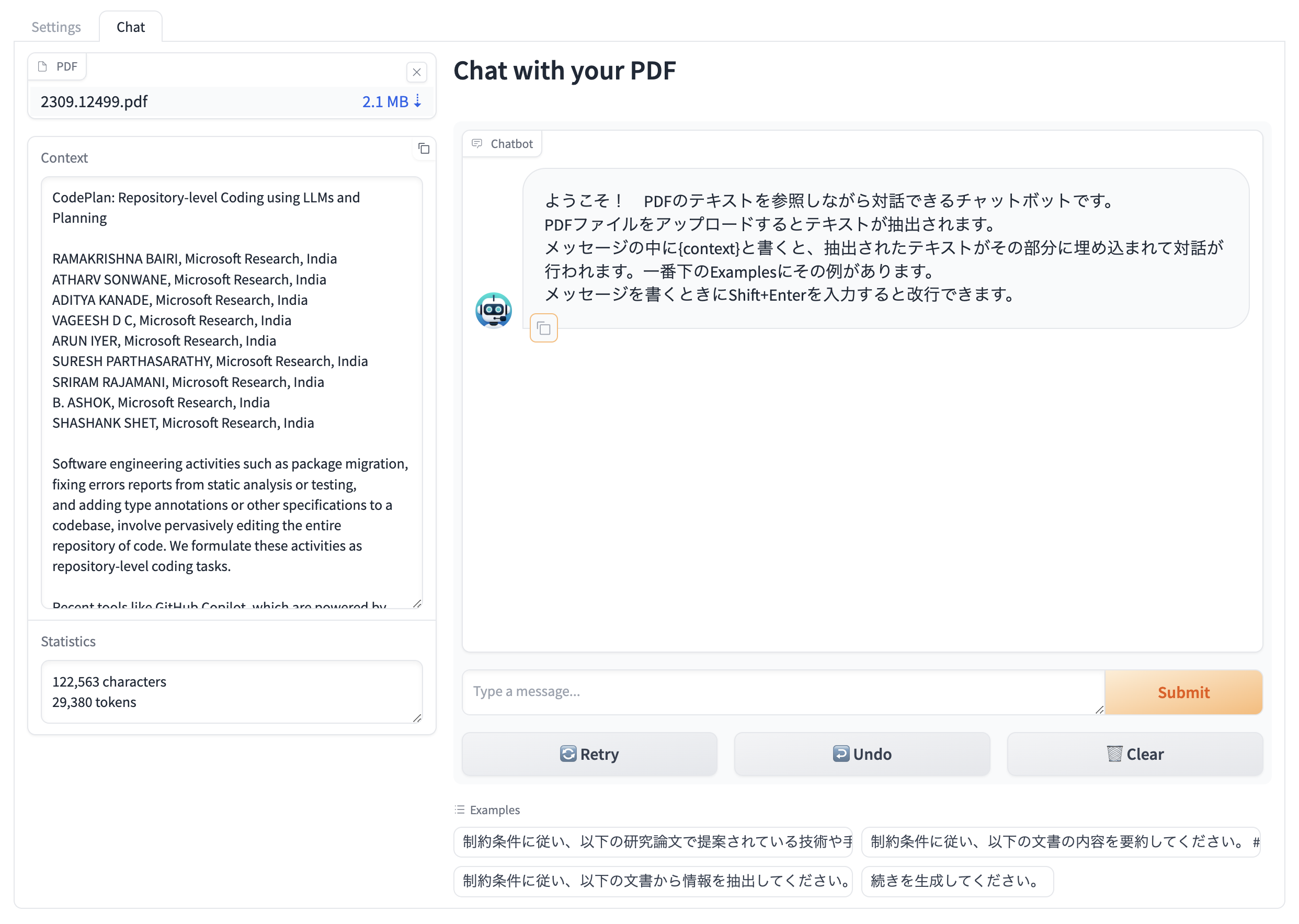
(PDFファイルの出典: CodePlan: Repository-level Coding using LLMs and Planning)
試しに、この論文を落合フォーマットに従って要約させてみましょう。
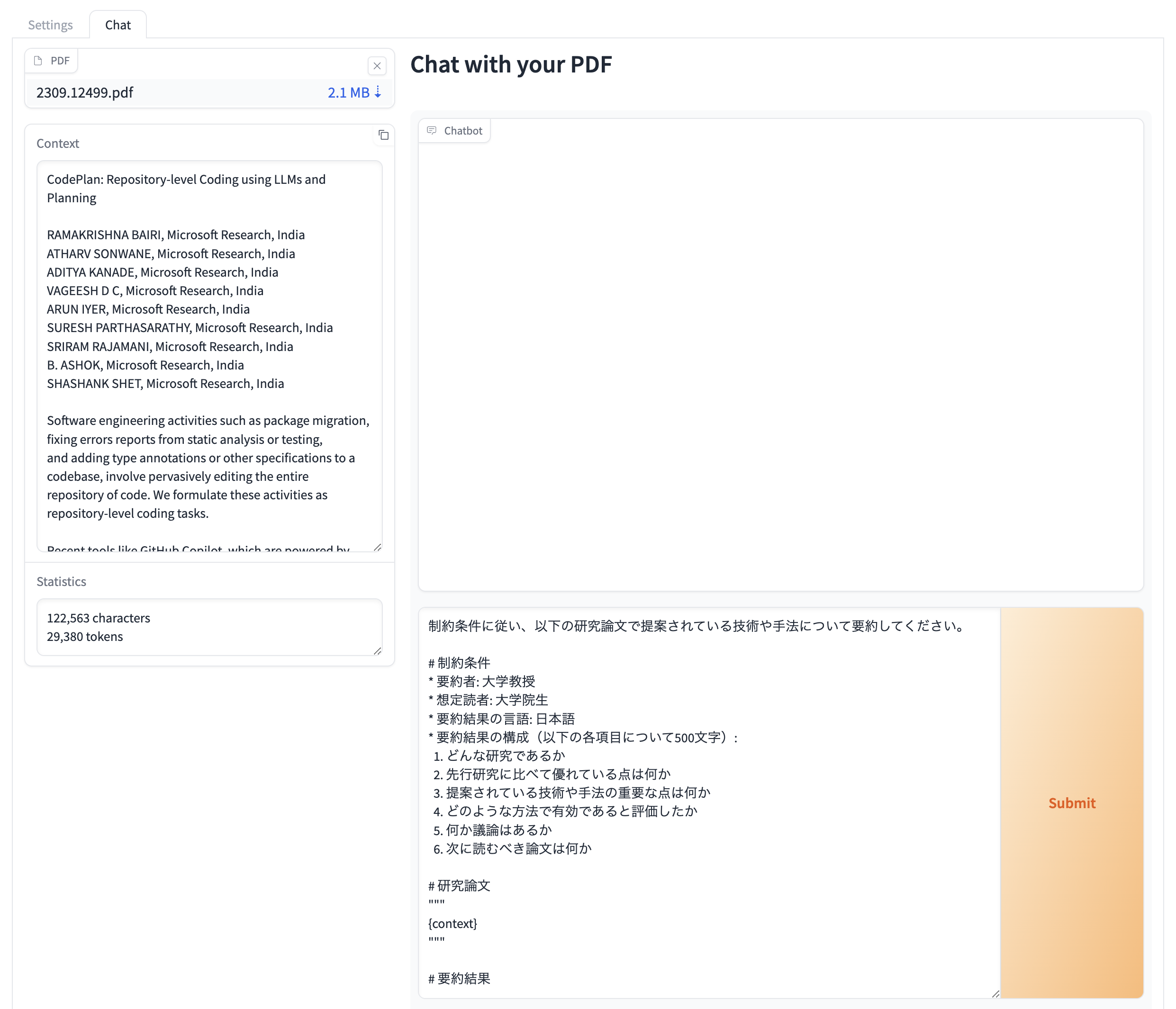
画面の一番下にある"Examples"の1個目が落合フォーマットに従った要約用のプロンプトになっていますので、それをクリックすると(下図のように)自動的にメッセージ入力欄に入力されます。
プロンプト中に"{context}"という文字列を書くことで、先ほどPDFから抽出したテキストがここに埋め込まれて処理が行われます。 プロンプトが読み書きしやすくなりますね。
注意
ユーザーからは見えませんが、プロンプトの"{context}"部分にはPDFファイルから抽出されたテキスト全文が埋め込まれて、ChatGPTに渡されて処理されます。つまりPDFファイルのテキストが長ければ長いほど処理するトークン数が増えるため、よりお金と処理時間がかかります。モデルがサポートするトークン数の上限を超える長さである場合はエラーが発生します。
あとは"Submit"ボタンを押すだけです。
しばらく待つと次のような生成結果が得られます(APIキー等の設定を間違わなければ)。
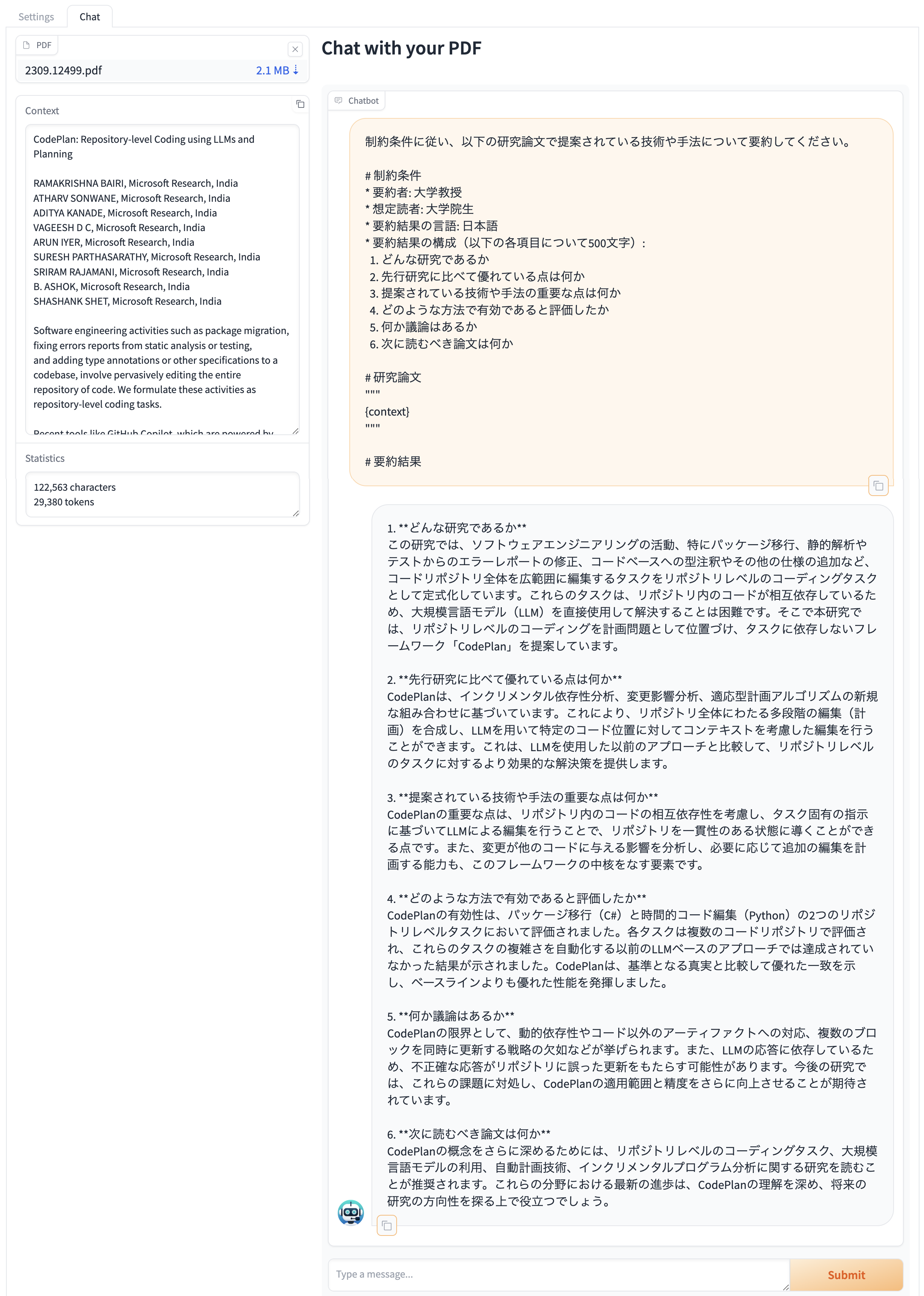
要約がたった数クリックでできました。論文読解が捗りますね。
この要約に、更にテスト問題も追加で生成してもらったチャット履歴を下記リンク先で見ることができます(アプリの起動に20〜30秒かかりますが)。これはチャット履歴保存機能を使った履歴共有の例でもあります。
4. RAG (Retrieval-Augmented Generation) 機能
RAG機能とは、PDFのページをキーワードで検索して、その検索結果を用いて質問に回答させたり、要約させたりできる機能です。(RAGの解説)
「ページを検索して」といったページ検索を促す表現と、検索キーワード(検索クエリ)を指定する文言をプロンプトに書けば、RAG機能(PDFのページ検索機能)が動きます。
検索キーワードは自分で明示的に与えることもできますし、ChatGPTに考えさせることもできます。
以下で説明する例はいずれもアプリ最下部にあるExamplesに含まれています。
RAGによるQAの例
下図のようにプロンプトを書けば、質問文から検索キーワード(検索クエリ)を複数バリエーション考えさせ、ページを複数検索させて、検索結果を用いて回答させることができます。
Examplesの「QA (英語文書RAG)」をクリックすれば、このプロンプトが入力されます。
プロンプトは長々としていますが、都度変える必要があるのは「質問」と「検索クエリの言語」くらいでしょう。
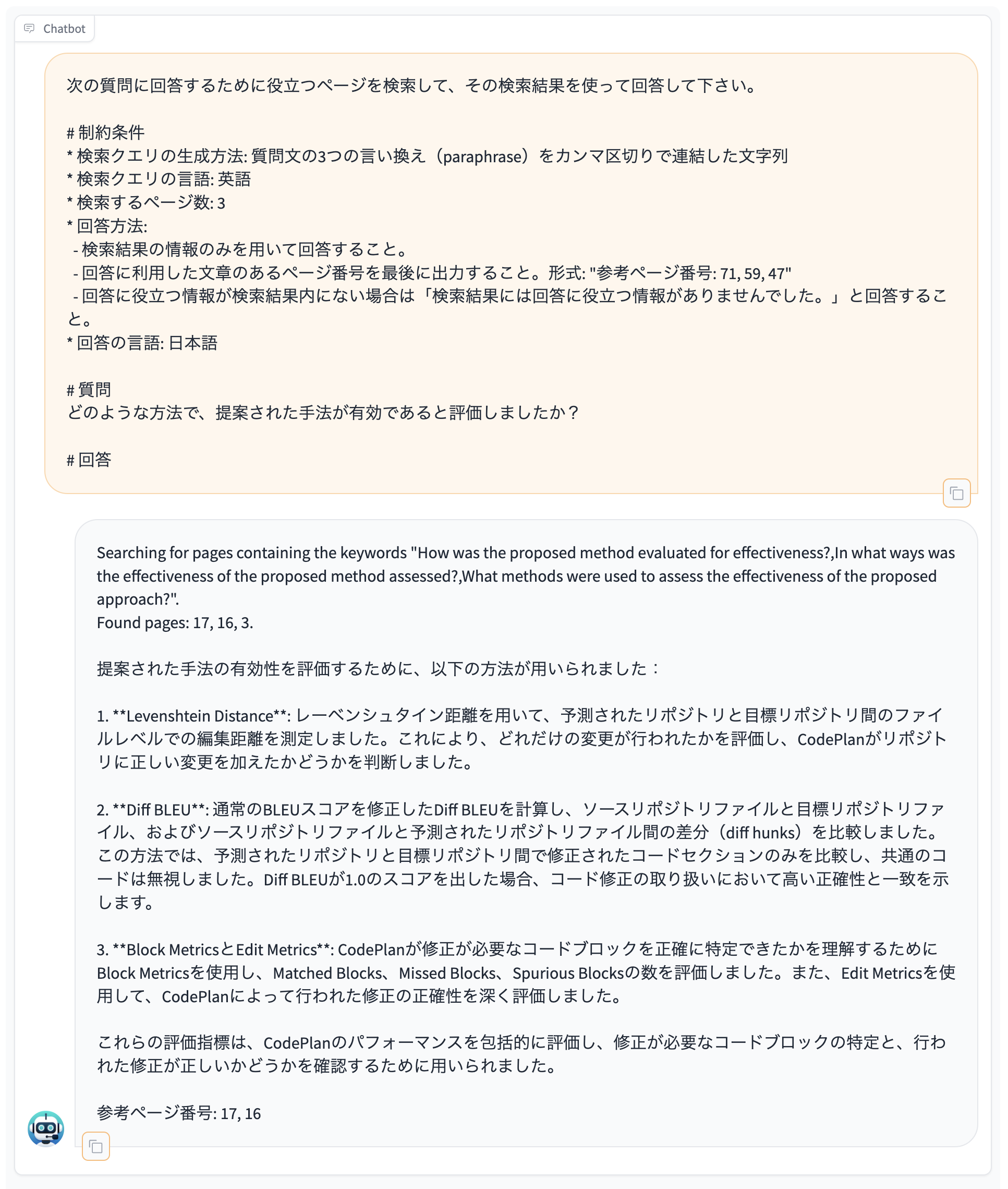
この例では検索キーワードとして "How was the proposed method evaluated for effectiveness?,In what ways was the effectiveness of the proposed method assessed?,What methods were used to assess the effectiveness of the proposed approach?" が自動生成されて、検索が行われ、ページ17と16、3がヒットしています。実際の回答に用いられたのはそのうちページ17と16です。
注意
ユーザーからは見えませんが、検索でヒットした全ページのコンテンツがChatGPTに渡されて処理されます。つまりページ数が多ければ多いほど処理するトークン数が増えて、お金がかかったり、トークン数の上限に到達してエラーが発生したりします。上記プロンプトの「検索するページ数」設定は増やしすぎないようにお気をつけください。
RAGによる要約や翻訳の例
本アプリのRAG機能はQAだけでなく、任意の生成に利用できます。
例えば、下図のようにプロンプトを書けば、要約や翻訳が行えます。
どちらもキーワードを明示的に指定していますが、QAのプロンプトの例のようにChatGPTに考えさせることも可能です。
検索したページの要約の例:
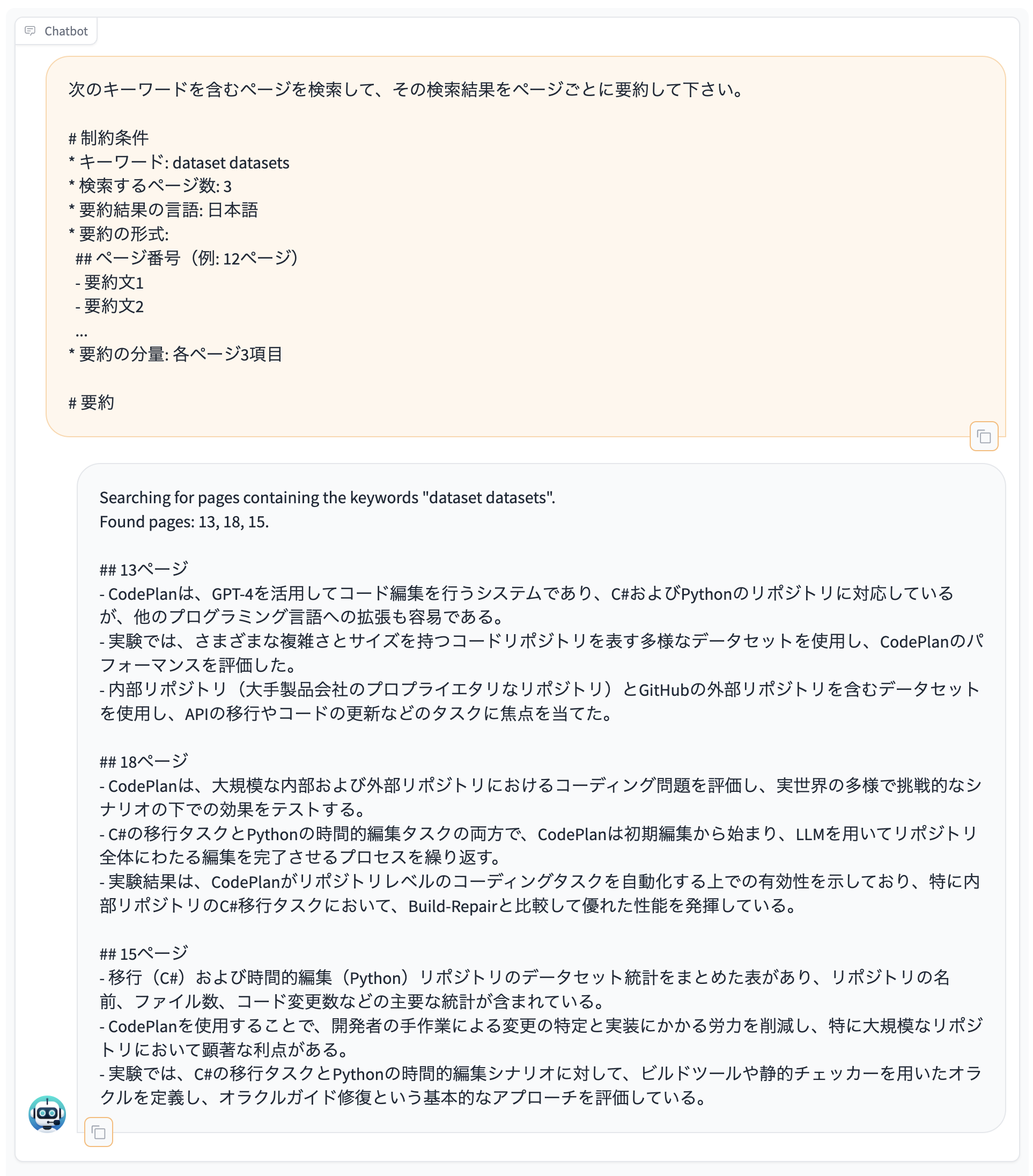
検索したページの翻訳の例:

ページ番号を指定してページを参照する例
RAG機能を使っていると、検索で見つけたページの前後のページも参照したくなる場合があります。例えば続きのページを要約したくなるなど。
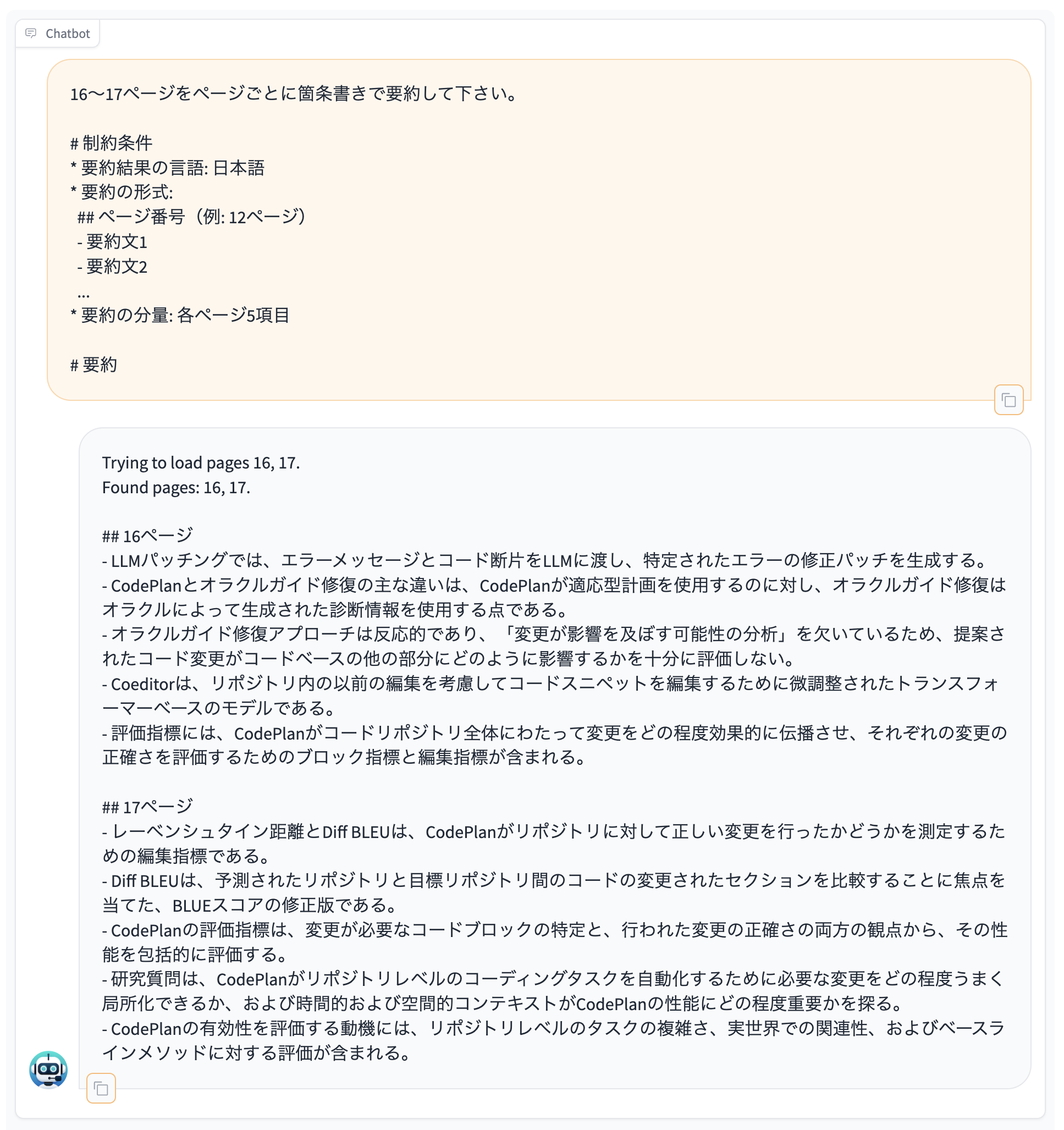
そういった用途のために、ページ番号を指定してページを参照できる機能もあります。
例えば、下図のようにページ番号を明示的に与えて参照させる表現を使うと、そのページを参照して生成処理を行なってくれます。
他にも、あるページを処理した次の発話で「その次のページも要約してください。」といった間接的にページ番号を与える指示を用いることもできます。
注意
ページ検索の場合と同じ注意事項です。ユーザーからは見えませんが、与えられた全ページのコンテンツがChatGPTに渡されて処理されます。つまりページ数が多ければ多いほど処理するトークン数が増えて、お金がかかったり、トークン数の上限に到達してエラーが発生したりします。参照させるページ数は増やしすぎないようにお気をつけください。
おまけ: チャット履歴保存機能
設定画面で「URLにチャット履歴を保存する機能」をオンにすると、URLのクエリパラメータ"history"にチャット履歴データ(を圧縮したもの)が保存されるようになります。(注意:huggingface spaces版ではチャット履歴保存機能は動きません)
オンの時は画面をリロードしても前のチャットの続きを行えますし、そのURLを他の人に渡すことでチャット履歴を共有することもできます。
ただし、GitLab pagesなどの利用できるURLの文字数制限をしているサーバー上で本機能を用いると、チャットが長くなると414エラーなどのページ読み込みエラーが発生する場合がありますので、その場合はチャット履歴保存機能をオフにして下さい。
- チャット履歴の例:論文要約とテスト問題生成結果
仕組みの解説
本アプリはGradio Liteを用いて構築されています。
Gradio Liteとは、ブラウザ内で動作するアプリをPython言語(Pyodide)を用いて開発できるフレームワークです。このフレームワークのおかげで、様々な既存のPythonライブラリ資産を活用でき、アプリサーバーを立てなくてもブラウザのメモリ内で高度な処理が行えます。
主な利用技術:
- Gradio Lite: ユーザーインターフェイスの構築
- Pyodide: ブラウザ内で動作するPython環境
- pdfminer.six: PDFファイルからテキストを抽出するために用いたライブラリ
- Janome: RAGの実装に用いた日本語形態素解析器
- Rank-BM25: RAGの実装に用いた検索エンジン
- OpenAI APIやAzure OpenAI Service: ChatGPT APIとして利用
ロボットアイコン  はDALL-Eを使って生成しました。
はDALL-Eを使って生成しました。
PDFのページ検索には、Okapi BM25アルゴリズムによるキーワード型検索を採用しています。ベクトル型検索はキーワード型検索よりも劣る結果になるケースをよく見かけますので、ひとまずベクトル型検索は不採用とし、キーワード型検索のみを採用しております。気が向いたらハイブリッド検索を実装するかもしれません。
検索対象のチャンク設計は「1チャンク = 1ページ」としました。この設計にした主な理由は、私の扱う資料ではまあまあ1ページごとに1つのトピックが分かれている傾向があるというのと、ページはユーザーにとっても理解と取り扱いがしやすい分割単位であることです。その他、ベクトル型検索を用いる場合はもっとチャンクサイズを小さくしないと埋め込みの精度が落ちるという問題がありますが、今回採用したキーワード型検索ではそういった問題は起こりにくいことも設計時の観点にありました。
現時点、キーワード型検索を行う際の形態素解析器として日本語用のみがある状態であり、英単語の取り扱いが十分とはいえません(単数形と複数形が別の形態素になっています)。英語のLemmatization等の正規化を行える形態素解析器も利用可能にすることで英語の検索精度を上げることができるはずです。
まとめと次の予定
私が資料チェックのときに普段使いしているアプリを公開させていただきました。
皆様のお役立てば幸いです。
今でも最低限の機能は備えていると思っておりますが、実用性を高めるために下記のような機能を追加したり、お遊びに別アプリを作ってみようかなと思っております。
-
RAG的な機能の追加。文章が長すぎると見落とし等の間違いが発生しやすくなるため、精度向上の観点から(function callingを使い)PDFのページやチャンクなどを検索して処理対象を絞り込めるようにする。(RAGの解説)(2024-02-17に実装済み) - Advanced Data Analyticsのような機能の追加?技術的な面白さはあるものの、この仕組みで実装することの嬉しさは少ない?(autogenのインストールまでは確認済み)
- マルチモーダル対応?
- Gemini対応?
免責事項
本アプリはMITライセンスに従い公開いたします。
著者は本アプリを開発するにあたって、その機能等について細心の注意を払っておりますが、バグがないことや、安全なものであるか等について保証をするものではなく、何らの責任を負うものではありません。本アプリのご利用により、万一、ご利用者様に何らかの不都合や損害が発生したとしても、著者や著者の所属組織は何らの責任を負うものではありません。