概要
RubyのActive RecordやPHP(Laravel)のEloquent、PythonのSQLArchemyみたいなORMを使うのに慣れている人は結構多いと思われる。
そういう人がScalaでアプリケーションを作ろうとしたときに一番戸惑うのがこのDB周りなんじゃないかと思う。
Java系ライブラリが強いからか、そもそも思想が違うからかORMっぽいDBライブラリがない。それも慣れれば気にならなくなるのだが、最初はそもそもScala自体に慣れていなかったりPlayフレームワークに慣れていなかったりするわけで、追い討ちをかけるように慣れないORMが襲ってくると結構心折れる。
しかも特に今回紹介するSlickとか典型的な使い方は普通に書いてあるしそこまで違和感ないので最初そこまで警戒しないのだが、少しちゃんとしたアプリ作ろうとした瞬間にORMではないという特徴が襲ってくる。
ただ、断言すると少し大変なところもあるけどちゃんと使えればSlickは有用なライブラリだと思う。確かにORMで起こる問題を解決する書き方ができることも多い。癖があるのは間違いないが、ユースケースの知見がもう少し色々出ていれば普通に使える。
今回はPlayの公式ライブラリであるSlickをちゃんと使い倒す方法を色々調べて、説明していく。
基礎的なところ
基礎的なところは結構色々書いてある。
特にこのドキュメントが日本語にもなっててかなり使える。
http://krrrr38.github.io/slick-doc-ja/v3.0.out/slick-doc-ja+3.0.html
また、ビズリーチが出しているslickのチートシートがかなりよくて、公式ドキュメントが少しわからないところも補完してくれる
https://github.com/bizreach/slick-reference
ただ実際使ってみるとこれだけだとまだ色々足りない
例えば
-
リレーションに関する言及が少ない。
-
最初に困るのはORMだと大抵Users.booksとかでユーザーと関連する1対多の子モデルも一緒に引っ張れるが、これのやり方が見てるだけだとわからない。また、子モデルも一緒にインサートするときどうするのかとかは全く書いておらず、どうやるんだろうとなる。
-
普段ORMに任せてSQLそこまで書かないエンジニアであればなおさら戸惑う(最初僕もそうでした)。Slickではある程度DBをSQLで叩くのに慣れているのを前提としており、ORMでできないレベルの複雑なことだけやるときにググるくらいの人だと結構最初大変。これに関してはSQLは大事なのでやりましょうとしか言えないが、肝心なのはSlickで使う構文は「SQLに似ている」だけでSQLとは全然違う。逆にSQLの常識で考えるとよくわからなくなる場面もあった。(group by の使い方とか)
-
-
code generatorの使いかた
- ORMみたいにスキーマを定義するのであるが、slickにはcode generatorという機能があり既存テーブルがあればすごく楽になる。と説明がある。
- と、思いきやORMだと思って考えるとこのcode generatorが使いづらく感じる。まず1ファイルに全モデルが出力されるため読みづらい。かなりよくわからないコードが生まれる。(outputToMultipleFilesオプションをtrueにすればファイルは分割される。)
- さらにコードは完全に上書きされるので、ORMみたいにコードを書いておいてももう一回code generateすると全部消える。この時点で普通のモデルの使い方はできない。
- 一応出力されるコードのカスタマイズはできるが、カスタマイズするコードがこれまた結構難しい。
-
Playでの使い方
- これは公式に結構ちゃんと書いてある。(https://www.playframework.com/documentation/2.7.x/PlaySlick)
- ただし、これはPlayのDIのやり方に慣れてからじゃないとよくわからないので最初飛ばしがち。LarabelとかでDI使っててもORMは結構普通に呼ぶパターンが多いのでわからない場合もあるかも。
- テスト時のDIが結構むずい。いくつか選択肢があるが、一番やりやすいはずのNamedアノテーションを使った方法は別クラスを使うことになって意外と辛い。これはPlayの問題と調べても一向に答えが出ず、Guiceの問題として調べると答えが出てきたりする。
こんな感じで結構わからないことおおいんですが、2週間くらい全力で触りまくってると確かにかなりSlickが言いたい、ORMだとここ辛いじゃんみたいなことがわかってくる。
まずは実験準備
要件
まず今回必要な使う要件は以下になる。
ユーザーがメモを保持し、これにタグを複数つけられる。
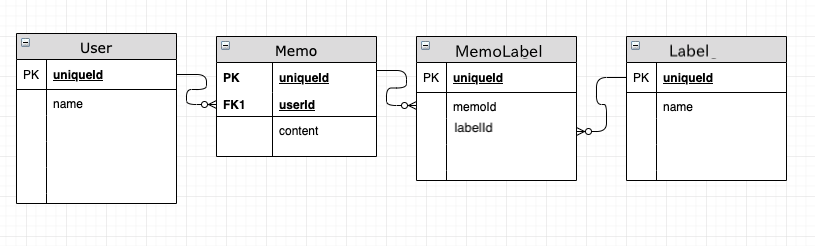
このようなDBを作ってSlickで実験する。
そこでこんなレポジトリを作っておいた。
これを使えばとりあえず今回の実験は可能。クローンして使ってください。
構築の仕方はREADME.mdに書いたので自分でPlayのプロジェクトを作るときとかは参考にしてください。
最初の前提:Codegen
ORM使ってた人が勘違いするポイント
SlickにおいてCodegenは相当強力な機能なのであるが、RailsなどORMから来る人はすごく混乱する。「ORMを自動生成してくれるのか!便利!」みたいな勘違いをするからである。(僕です)
まず最初にわかっておかなければならないのはCodegenは「データベースをScalaで表現することでSQLとかを簡単に書いて実行することができるためのオブジェクトを自動生成する」ものであり、ORMなんて作ってくれない。
つまり、ORMっぽくしたければ自分で作る必要がある。
例えば今回の話でいうとUserRowオブジェクトとかMemoオブジェクトなどは作ってくれる。そのため、ORMに慣れた人(僕です)ならUserモデルは勝手にMemoモデルを配列に持ったオブジェクトを作ってくれていると思い込む。そのため「わかった!こう書くんでしょ!」って言いながら
val users = Users.all
val firstUser = users.head
// userはmemoモデルを配列で持つ(と勘違いした図)
println(user.head.memos)
とか書けばuserに紐づいたメモを配列で取れると思いこむ(なんども言いますが僕です)。**Slickにそんな甘えた機能はない。**というかこういったORMの機能のデメリットを解消するためのSlickである。
ちなみにこれを再現して、メモオブジェクトを配列で持つuserの配列を作りたかったらこうなる。
val action = Users join(Memo) on (_.id === _.user_id)
val resultFuture = db.run(action).map(
_.groupby(_.1)
.map(
userAndMemos = > {
(userAndMemos._1, userAndMemos._2.map(_.2))
}
)
resultFuture.map{
users => println(users.head._2)
}
ここで逃げ出さないように。 joinやらgroupbyやらが出てきてSQL嫌だってなる気持ちはわかる。(僕です)
Railsとか使ってるとuserに紐づくMemo一覧を取るだけでSQL書かなきゃいけないの!ってなる人は少なくないんじゃないかと思う。やってくとそこまで難しくないし、Scala言語自体の強力さ(コレクション操作や型システム)のおかげで気にならなくなってくる。
以上でわかるように、とにかくまず理解してほしいのはSlickは思想的にそもそもORMを作るものではない。
するとCodegenの認識が変わってくる。要するに単にScalaでSQLを作り出すために作らなければいけないオブジェクトってだけなのである。なので
- 基本自動生成
- 生成されたコードを触らない
- マイグレーションするたびに自動生成する。
みたいな運用をするだけでいい。ORMじゃないからメソッドを追加したりしない。必要なのは勝手に生成される。
使い方
とりあえず使うためにはマイグレーションをした上でてきとうなscalaファイルで
SourceCodeGenerator.main(
Array(
"slick.jdbc.PostgresProfile",//DBドライバー。古い情報だと "slick.driver.PostgresDriver"になっていることが結構あるが、これはslick3.2.0で変わってしまった。slickと一緒でおけ
"org.postgresql.Driver", //JDBCのDBドライバー?まあslickと一緒でおけ
"jdbc:postgresql://localhost:5432/slick_db_development",//DBのurl。ここもslickと一緒でおけ
"app/infrastructure",// コードの出力先ディレクトリ。
"dto",// 上と合わせてこう書くとapp/infrastracture/dto/Tables.scalaというパスで1ファイルに全て書かれる。基本Slickは1ファイルに全てが書かれる形だが、一番最後のオプションをtrueにすると分割して作成できる。
"postgres",// dbのユーザー名。slickと一緒でおけ
"password"// dbのパスワード。slickと一緒でおけ
"true", // ignoreInvalidDefaultsオプションらしい。よくわからない。
"slick.codegen.SourceCodeGenerator", // codeGeneratorClassオプション。これはデフォルトはこうなってるのでこのままでいい。
"true"// outputToMultipleFilesオプション。デフォルトはfalseだが、これをtrueにするとファイルが分割されて出力される。
)
)
と書いて実行すれば良い。ただわざわざscalaファイルにするのもアレなのでsbtタスクを作っておくと、sbt codegenでいつでも呼べるので良い。
import slick.codegen.SourceCodeGenerator
name := """play-scala-seed"""
organization := "com.example"
version := "1.0-SNAPSHOT"
//以下削除
-) lazy val root = (project in file(".")).enablePlugins(PlayScala)
scalaVersion := "2.12.8"
libraryDependencies += guice
libraryDependencies += "org.scalatestplus.play" %% "scalatestplus-play" % "4.0.3" % Test
resolvers += "scalaz-bintray" at "https://dl.bintray.com/scalaz/releases"
resolvers += "Akka Snapshot Repository" at "https://repo.akka.io/snapshots/"
libraryDependencies ++= Seq(
"com.typesafe.play" %% "play-slick" % "4.0.2",
"com.typesafe.play" %% "play-slick-evolutions" % "4.0.2",
"com.typesafe.slick" %% "slick-codegen" % "3.2.0",
"org.postgresql" % "postgresql" % "42.2.5"
)
//以下追加
lazy val codegen = taskKey[Unit]("generate slick table code")
lazy val root = (project in file("."))
.enablePlugins(PlayScala)
.settings(
codegen := {
SourceCodeGenerator.main(
Array(
"slick.jdbc.PostgresProfile",
"org.postgresql.Driver",
"jdbc:postgresql://localhost:5432/slick_db_development",
"app/infrastructure",
"dto",
"postgres",
"password",
"true",
"slick.codegen.SourceCodeGenerator",
"true"
)
)
}
)
このようにcodegenというtaskKeyを定義し、root.settings内で実行コードを書くとsbt codegenで呼び出せる。
Play内での使い方
Slickの基本的な使い方は上記のサイトなどに結構書いてあるが、意外とPlayで使うときこれどうするんだってなる点が多い。
まずは実験用に/users/addってurlにGETリクエストを送ったらランダムのユーザー名でユーザーが追加され、/usersで全てのデータが取れるみたいなクソサーバーを作ります。
チュートリアル用プロジェクトではviewを使うのだが、今回はJSONサーバーを作るためapp/viewディレクトリは全削除。その上で最初にこうなっているコントローラーを
package controllers
import javax.inject._
import play.api._
import play.api.mvc._
/**
* This controller creates an `Action` to handle HTTP requests to the
* application's home page.
*/
@Singleton
class HomeController @Inject()(cc: ControllerComponents) extends AbstractController(cc) {
/**
* Create an Action to render an HTML page.
*
* The configuration in the `routes` file means that this method
* will be called when the application receives a `GET` request with
* a path of `/`.
*/
def index() = Action { implicit request: Request[AnyContent] =>
Ok(views.html.index())
}
def explore() = Action { implicit request: Request[AnyContent] =>
Ok(views.html.explore())
}
def tutorial() = Action { implicit request: Request[AnyContent] =>
Ok(views.html.tutorial())
}
}
こうする。スッキリ。
package controllers
import javax.inject._
import play.api._
import play.api.mvc._
@Singleton
class HomeController @Inject()(cc: ControllerComponents) extends AbstractController(cc) {
def index() = Action { implicit request: Request[AnyContent] =>
Ok("")
}
def add()=Action{
Ok("")
}
}
さらにconf/routesというファイルでこうなっているのを
# Routes
# This file defines all application routes (Higher priority routes first)
# https://www.playframework.com/documentation/latest/ScalaRouting
# ~~~~
# An example controller showing a sample home page
GET / controllers.HomeController.index
GET /explore controllers.HomeController.explore
GET /tutorial controllers.HomeController.tutorial
# Map static resources from the /public folder to the /assets URL path
GET /assets/*file controllers.Assets.versioned(path="/public", file: Asset)
こうする。
GET /users controllers.HomeController.index
GET /users/count controllers.HomeController.count
GET /users/add controllers.HomeController.add
# Map static resources from the /public folder to the /assets URL path
GET /assets/*file controllers.Assets.versioned(path="/public", file: Asset)
これで準備完了。/usersと/users/addにアクセスするとエラーは起きないが何も表示されないのが確認できる。
ユーザー一覧取得
Play内でSlickを使うときは、PlayのDIシステムを利用する。Playを使う上でDIの考え方は必須なので知らない人は"Play DI"とかでググるか公式を見るといいです。公式がかなりちゃんと書いてある。
使う手順としては
-
まずHasDatabaseConfigProviderトレイトをSlickで使いたいクラスでミックスインします。
-
DatabaseConfigProviderをDIします。HasDatabaseConfigProviderトレイトで使う。
-
import slick.jdbc.PostgresProfile
import slick.jdbc.PostgresProfile.api._ -
(SlickというよりFutureのために必要な部分だが)implicitでExecutionContextをInjectする。
-
(これもSlickというよりFutureのために必要な部分だが)コントローラー用メソッドがAction.asyncを返すように変更
-
dbという変数名で呼び出せる。
まずは/usersにアクセスするとユーザーを全取得する機能と、
/users/countにアクセスすると保存されているユーザーの数を表示する機能を作成する。
package controllers
import javax.inject._
import play.api._
import play.api.mvc._
import play.api.db.slick.{DatabaseConfigProvider, HasDatabaseConfigProvider} // 1. 2.に対する対応でimportが必要
import slick.jdbc.PostgresProfile // 3.の対応
import slick.jdbc.PostgresProfile.api._ // 3.の対応
import dto.Tables._ // sbt codegenで"app/infrastructure/dto/"配下にUserとかが作成されるので、それをimportする。
@Singleton
//DatabaseConfigProviderとExecutionContextをInject
class HomeController @Inject()(protected val dbConfigProvider: DatabaseConfigProvider,cc: ControllerComponents)(implicit ec: ExecutionContext)
extends AbstractController(cc) with HasDatabaseConfigProvider[PostgresProfile] {
// コントローラー用defがActionではなくAction.asyncを返すよう変更
def index(): Action[AnyContent] = Action.async { implicit request =>
val action = User.result
db.run(action)
.map(
users => Ok(users.toList.mkString(","))
)
.recover{
case exception: Exception => InternalServerError(exception.getMessage)
}
}
// コントローラー用defがActionではなくAction.asyncを返すよう変更
def count(): Action[AnyContent] = Action.async {
val action = User.result
db.run(action)
.map(
users => Ok(users.size.toString)
)
.recover{
case exception: Exception => InternalServerError(exception.getMessage)
}
}
def add()=Action{
Ok("")
}
}
さて、いよいよSlickの文法になるが、まず重要なのはSlickはクエリの構築と実行が分離されている。
そのためN+1問題みたいな予想外のクエリ発行みたいな問題は起こらない。
詳しく見ていくと
val action = User.result//action作成
db.run(action)//実行(Futureを返す)
.map(
users=> Ok(users.toList.mkString(","))
)
という構成になっており、さらにコントローラーはAction.asyncを戻り値にするとしておくとFutureを返せばFutureがCompleteしたときにrenderされる。
これで/usersにアクセスすると、当たり前だが何も表示されない。
さらにこれで/users/countにアクセスすると0が表示される。
ユーザー追加
ここからはDBへの追加をおこなっていく。
最終形はgithubレポジトリではexample1_add_and_indexブランチにある。
def add() = Action.async{
val action = User returning User.map(user => (user.id,user.name)) += UserRow(0, Random.alphanumeric.take(7).mkString)
db.run(action).map(
tuple=> Ok("ID:"+tuple._1.toString+"ユーザー名:"+tuple._2+"のユーザーが作成されました。")
).recover{
case exception: Exception => InternalServerError(exception.getMessage)
}
ユーザーの追加は一癖ある。
まず追加のアクションは
val action = User += UserRow(0, Random.alphanumeric.take(7).mkString)
となる。このとき注意なのはauto incrementされるカラムに関しては何を入れても無視されて自動で数字が決まるということである。ただ、型としてはprimary keyはnull不可なので、とりあえず0を固定して入れておく(これ普通に気持ち悪いけどなんとかならないのか)。
ただ、これでdb.runをすると返ってくるのは影響を与えた行。つまり追加された行数になり、成功すると1が返る。
例えば今回のように、生成された行数のパラメータが欲しい場合はreturningを使う。
//オートインクリメントされたidを取る場合
val action = User returning User.map(_.id) += UserRow(0, Random.alphanumeric.take(7).mkString)
//idも名前も欲しい場合
val action = User returning User.map(user => (user.id,user.name)) += UserRow(0, Random.alphanumeric.take(7).mkString)
このようなコードを書いて、/users/addにアクセスすると、
また、その後/usersにアクセスすると
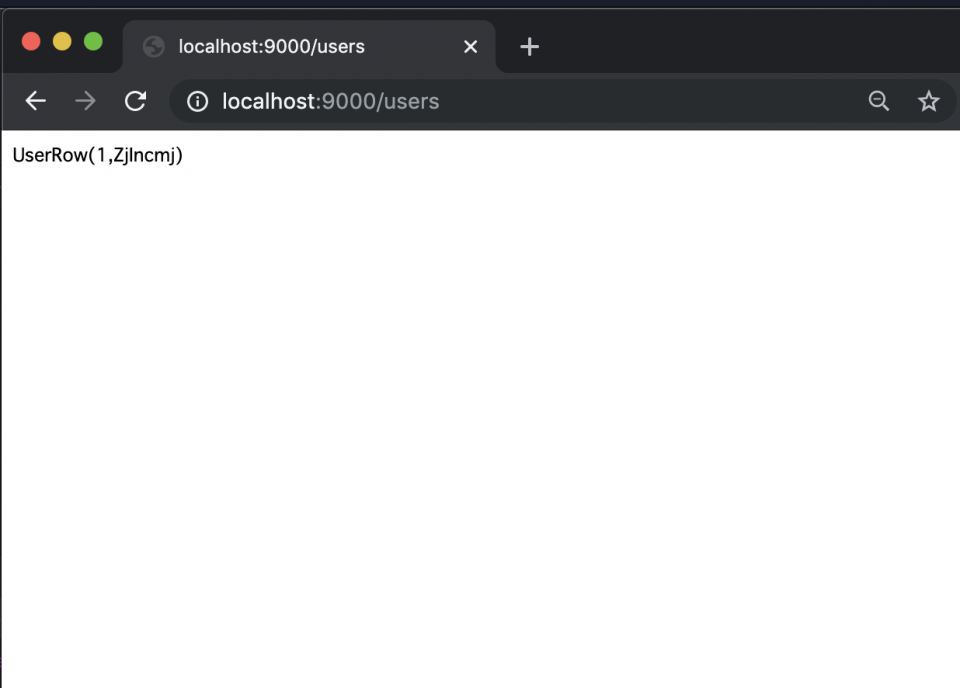
というようにIDとnameが登録された状態になる。
多対多のモデルと関連テーブルを同時登録
今度はメモとラベルを同時に登録する。
最終形はexample2_add_memo_and_labelブランチにある
構成は以下のようになる(再掲)
メモを登録する時に同時にラベルを登録したい。
このような場合1回のアクション(今回は登録)の結果を利用して次の文を書くことになる。
(登録されたMemoとLabelのauto incrementされたidを利用し、Labelmemoデータを作成する。)、for文を使うと綺麗にかけることが多い。
以下のようにfor文を使って書く。
def addMemoAndLabel(userId:Int): Action[AnyContent] = Action.async{
val action=
for{
memo <-Memo returning Memo.map(memo => memo.id) into((memo,id)=> memo.copy(id = id)) += MemoRow(0,"todo:"+Random.alphanumeric.take(7).mkString, userId)
label <- Label returning Label.map(label =>label.id) into((label,id)=>label.copy(id=id)) += LabelRow(0,"label:"+Random.alphanumeric.take(7).mkString)
_ <- Labelmemo += LabelmemoRow(0,memo.id,label.id)
} yield (memo,label)
db.run(action.transactionally).map(
tuple=> Ok("ID:"+tuple._1.id.toString+" ユーザーID:"+tuple._1.userId.toString+" コンテンツ:"+tuple._1.content+"のメモが作成されました。"+"\n"+"ID:"+tuple._2.id.toString+" コンテンツ:"+tuple._2.name+"のラベルが作成されました。")
).recover{
case exception: Exception => InternalServerError(exception.getMessage)
}
}
このfor文を解説すると。
for{
//メモを登録する
memo <-Memo returning Memo.map(memo => memo.id) into((memo,id)=> memo.copy(id = id)) += MemoRow(0,"todo:"+Random.alphanumeric.take(7).mkString, userId)
//ラベルを登録する
label <- Label returning Label.map(label =>label.id) into((label,id)=>label.copy(id=id)) += LabelRow(0,"label:"+Random.alphanumeric.take(7).mkString)
//登録されたラベルのidとメモのidを用いて中間テーブルであるLabelmemoを登録する。
_ <- Labelmemo += LabelmemoRow(0,memo.id,label.id)
} yield (memo,label)
また、このように一連の流れを1トランザクションで行うために
db.run(action.transactionally)のようにtransactionallyをつけて実行する。
GET /users controllers.HomeController.index
GET /users/count controllers.HomeController.count
GET /users/add controllers.HomeController.add
GET /users/:userId/memos/add controllers.HomeController.addMemoAndLabel(userId:Int)
# Map static resources from the /public folder to the /assets URL path
GET /assets/*file controllers.Assets.versioned(path="/public", file: Asset)
以上をおこなって、まずuserを作る。
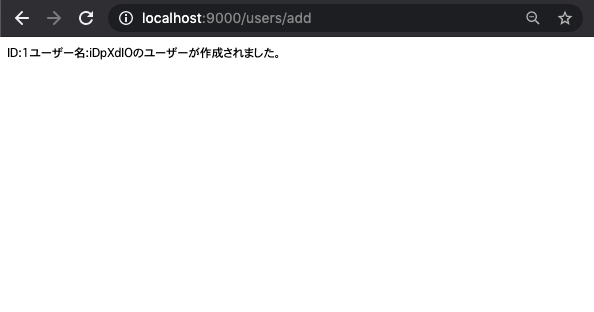
その後、/users/作られたid/memos/addのルーティングにアクセスする。
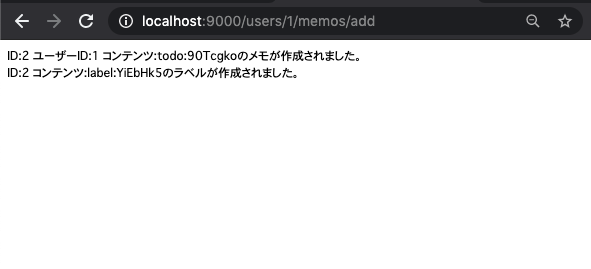
関連テーブルとともにユーザー一覧取得
これがslickで行うと一番複雑になるであろう部分。
今回はユーザーがメモを多数もち、メモが多対多でラベルを持つという状況である。
これらを一括で取得する。
もはや文章だと複雑なのでJSONオブジェクトで返すこととする。
def indexWithRelatedTable(): Action[AnyContent] = Action.async {
implicit request =>
val labels = Labelmemo join Label on (_.tagId === _.id)
val labelsAndMemos = Memo joinLeft labels on (_.id === _._1.memoId)
val action = User joinLeft labelsAndMemos on (_.id === _._1.userId)
db.run(action.result).map {//ここまで①の部分
result => {
Ok(
Json.obj(
"users" -> (
for {
(user, memos) <- result.groupBy(_._1)//ここまで②の部分
memoAndLabels = for {
(maybeMemo, labels) <- memos.groupBy(_._2.map(_._1))
} yield for {
memo <- maybeMemo
} yield Json.obj(
"memoId" -> memo.id,
"memoContent" -> memo.content,
"labels" -> labels.map {
case (_, maybeMemoAndLabel) =>
maybeMemoAndLabel.flatMap(_._2.map {
case (_, label) => Json.obj(
"labelId" -> label.id,
"labelName" -> label.name
)
})
}
)//ここまで③の部分
} yield Json.obj(
"userId" -> user.id,
"userName" -> user.name,
"memo" -> memoAndLabels.flatten
)).toSeq
)
)
}
}
}
あまりにも複雑すぎて意味不明だと思う。順番に追っていこう。
①部分
val labels = Labelmemo join Label on (_.tagId === _.id)
val labelsAndMemos = Memo joinLeft labels on (_.id === _._1.memoId)
val action = User joinLeft labelsAndMemos on (_.id === _._1.userId)
db.run(action.result) //ここまで①部分
.map{...
ここで行なっているのはSQL文の構築である。
一行ずつみていく。
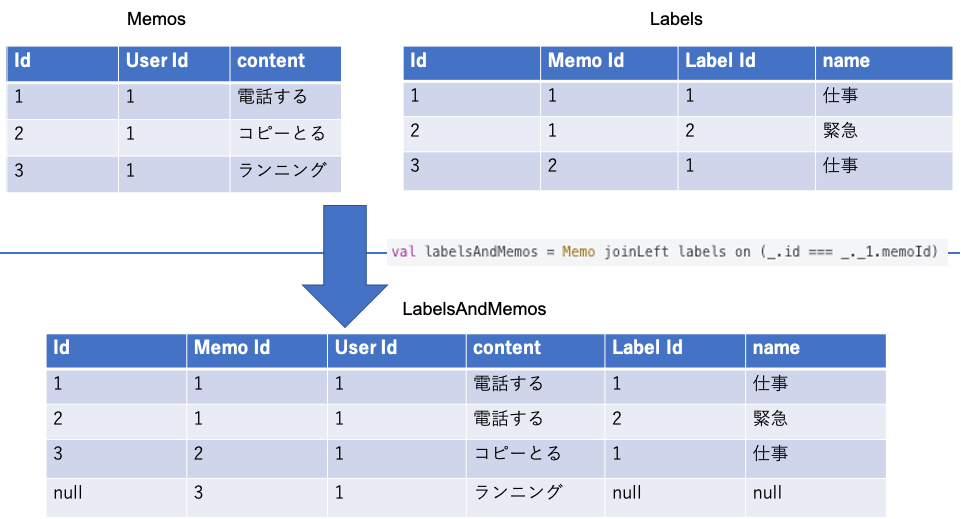
val labels = Labelmemo join (Label) on (_.tagId === _.id)
このER図を再びみるが、まずはLabelMemoテーブルとLabelテーブルをつなぐ。(labelIdがtagIdになってしまっているが気にしないでください。)
labelMemoが存在する時Memoは必ず存在するのでinner joinでok。inner joinの時はjoinメソッドを使う。
以下のようになる。(Idが消えていないので謎なことになってますが図直すのめんどくさいんで気にしないでください)

次に以下
val labelsAndMemos = Memo joinLeft labels on (_.id === _._1.memoId)
これも同じだが、Memoはラベルを持つとは限らないので、今回は外部結合を行う。外部結合はjoinLeftで行える。
さらに
val action = User joinLeft labelsAndMemos on (_.id === _._1.userId)
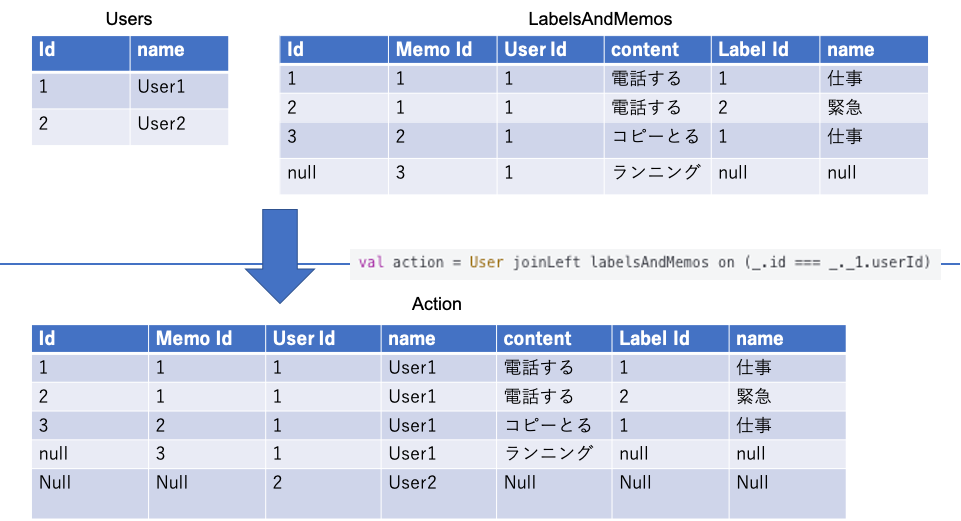
さて、ここまではSQLを生成する部分。
これをdb.run(action.result)で実行する。そうするとFuture型が返る。
ただし、これによって取得できるのは以下のような状態。
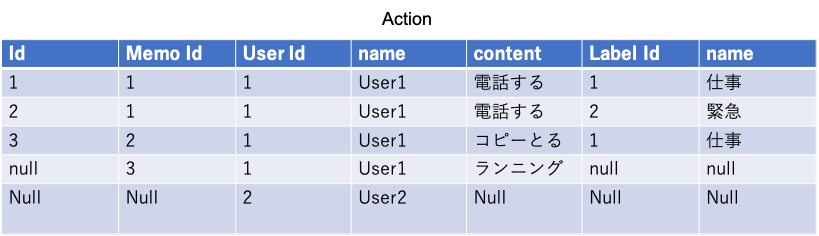
当たり前だがここからUserやmemoごとにgroup化する必要がある。
これはSQL上ではできないので、db.run後にアプリケーション側で行う。
続き
db.run(action.result)
.map {//ここまで①の部分
result => {// これはFuture型の中身。ちなみに型はSeq[(Tables.UserRow, Option[(Tables.MemoRow, Option[(Tables.LabelmemoRow, Tables.LabelRow)])])]
Ok(
Json.obj(
"users" -> (
for {
(user, memos) <- result.groupBy(_._1)//ここまで②の部分
memoAndLabels = for {
(maybeMemo, labels) <- memos.groupBy(_._2.map(_._1))
} yield for {
memo <- maybeMemo
} yield Json.obj(
"memoId" -> memo.id,
"memoContent" -> memo.content,
"labels" -> labels.map {
case (_, maybeMemoAndLabel) =>
maybeMemoAndLabel.flatMap(_._2.map {
case (_, label) => Json.obj(
"labelId" -> label.id,
"labelName" -> label.name
)
})
}
)//ここまで③の部分
} yield Json.obj(
"userId" -> user.id,
"userName" -> user.name,
"memo" -> memoAndLabels.flatten
)).toSeq
)
)
}
}
②部分
result => {
Ok(
Json.obj(
"users" -> (
for {
(user, memos) <- result.groupBy(_._1)//ここまで②の部分
db.runの戻り値をmapし、Okメソッドの中にJsObjectを入れて返す。
今回はUserに関連するメモをまとめ、メモに関連してるラベルをまとめるという構造。
なのでまず、
(user, memos) <- result.groupBy(_._1)//ここまで②の部分
とすることでuser(Tables.UserRow)と memos (Seq[(Tables.UserRow, Option[(Tables.MemoRow, Option[(Tables.LabelmemoRow, Tables.LabelRow)])])])が取れる。
memosにもuserRowがあるが、別にあまり気にしなくてよく、どちらかというとOption[(Tables.MemoRow, Option[(Tables.LabelmemoRow, Tables.LabelRow)])]の部分が重要。現段階ではmemoとlabelが被っている状態。
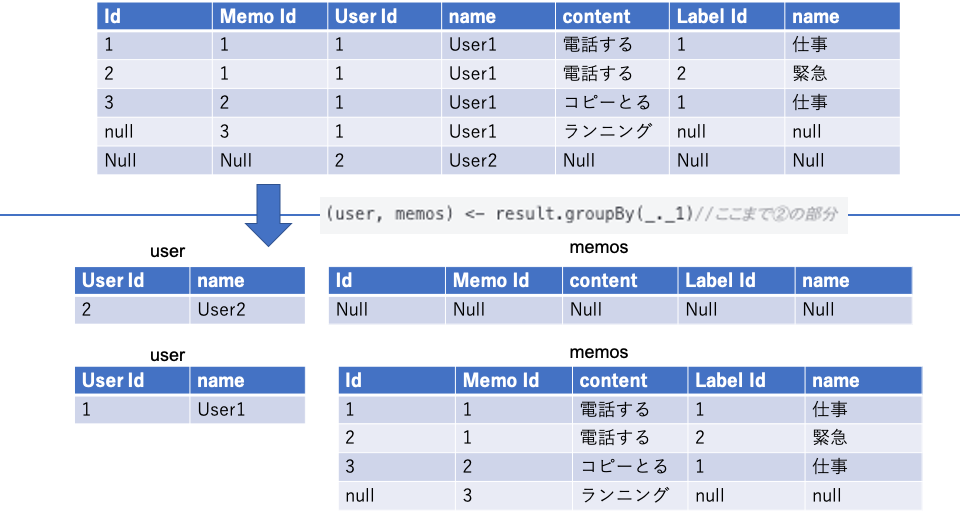
③部分
memoAndLabels = for {
(maybeMemo, labels) <- memos.groupBy(_._2.map(_._1))
} yield for {
memo <- maybeMemo
} yield Json.obj(
"memoId" -> memo.id,
"memoContent" -> memo.content,
"labels" -> labels.map {
case (_, maybeMemoAndLabel) =>
maybeMemoAndLabel.flatMap(_._2.map {
case (_, label) => Json.obj(
"labelId" -> label.id,
"labelName" -> label.name
)
})
}
)//ここまで③の部分
まず
(maybeMemo, labels) <- memos.groupBy(_._2.map(_._1))
この記述により
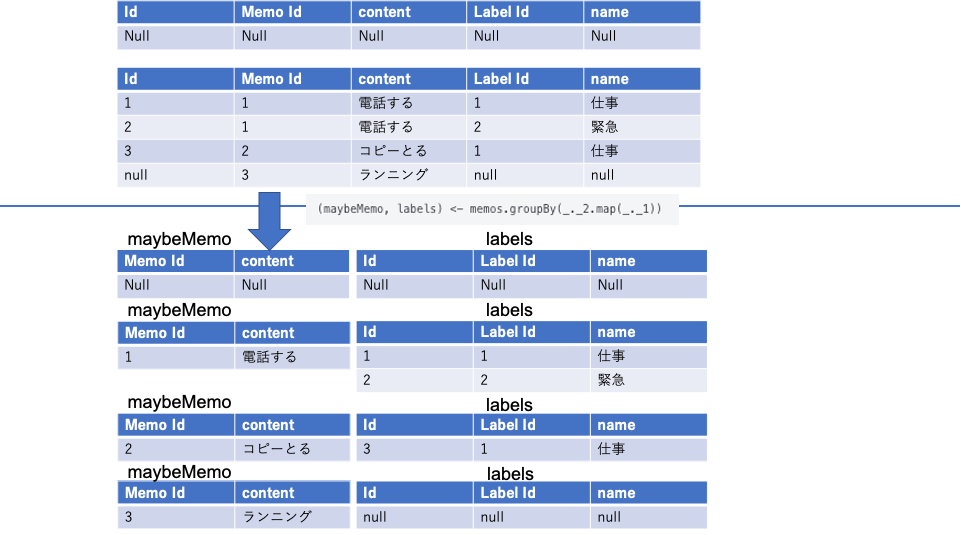
こんな感じになる。
あとはmemoがNullの時はNullとするためにこの記述をする。
yield for {
memo <- maybeMemo
}
最後にそれをJson化する。
yield Json.obj(
"memoId" -> memo.id,
"memoContent" -> memo.content,
"labels" -> labels.map {
case (_, maybeMemoAndLabel) =>
maybeMemoAndLabel.flatMap(_._2.map {
case (_, label) => Json.obj(
"labelId" -> label.id,
"labelName" -> label.name
)
})
}
)
labelsの処理だけ少し複雑なのでさらに詳細にみる。
"labels" -> labels.map {
case (_, maybeMemoAndLabel) =>
maybeMemoAndLabel.flatMap(_._2.map {//ややこしいがここもnullが化なのでnullの時はnullのままにするためにflatMap。中身がある時だけ処理する。
case (_, label) => Json.obj(//存在してたらJsonオブジェクトにする。
"labelId" -> label.id,
"labelName" -> label.name
)
})
}
)
ここまでかけたら/usersの実行メソッドを変える。
GET /users controllers.HomeController.indexWithRelatedTable//ここがindexだったのをindexWithRelatedTableに変える
GET /users/count controllers.HomeController.count
GET /users/add controllers.HomeController.add
GET /users/:userId/memos/add controllers.HomeController.addMemoAndLabel(userId:Int)
# Map static resources from the /public folder to the /assets URL path
GET /assets/*file controllers.Assets.versioned(path="/public", file: Asset)
その後
/users/addに2回アクセスした上で
/users/1/memos/addにアクセス。
その後
usersにアクセス。
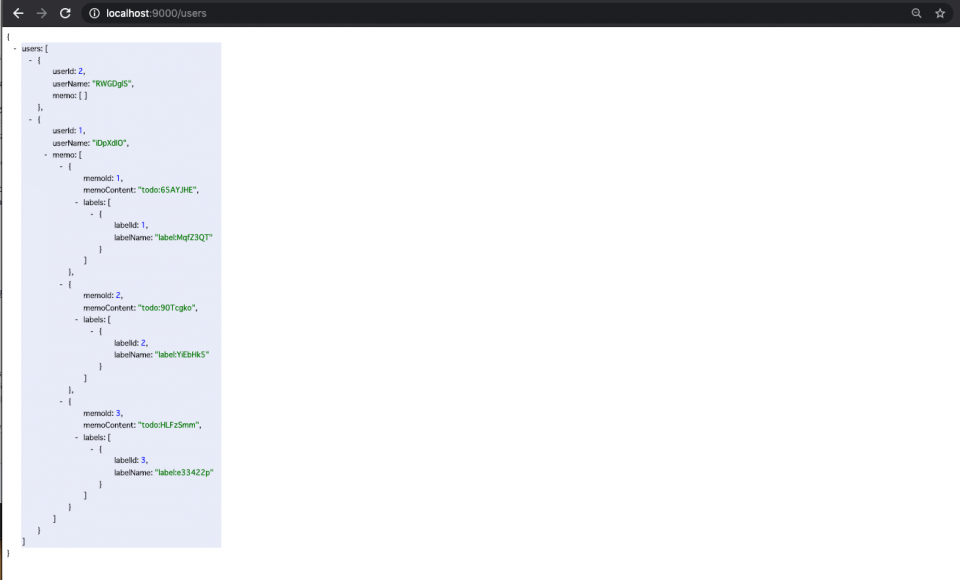
こうなってたらOK。
削除時に関連テーブルも一緒に削除
最後の項目である。
完成形はexample4_delete_userブランチ
ユーザーを削除する時に関連するメモと、それに関連するラベルを一緒に削除したい。
こういう時はfor文が使える
def delete(userId: Int): Action[AnyContent] = Action.async {
implicit request =>
//削除するユーザーを取得
val deleteUser = User.filter(_.id === userId.bind)
//削除するユーザーに関連するメモを取得
val deleteMemo = Memo.filter(_.userId in deleteUser.map(_.id))
//削除するユーザーに関連するメモに関連するラベルメモ(中間テーブル)を取得
val deleteLabelMemos = Labelmemo.filter(_.memoId in deleteMemo.map(_.id)).result
db.run(
//削除するラベルメモをもとに、LabelとLabelMemoテーブルを削除
// 一旦resultからmapしないと先にlabelMemoが削除されて関連するラベルが削除されない。
deleteLabelMemos.flatMap(
//取得したラベルメモをもとに、LabelとLabelMemoテーブルを削除
result =>(Labelmemo.filter(_.id inSet result.map(_.id)).delete >> Label.filter(_.id inSet result.map(_.tagId)).delete)
) >>
deleteMemo.delete >> //これはAndThen構文。順番に実行し最後の結果のみ返す。
deleteUser.delete
).map(_ => Ok("ユーザーを削除しました。"))
}
これも少し複雑である。いくつかポイントをみていく
//削除するユーザーを取得
val deleteUser = User.filter(_.id === userId.bind)
//削除するユーザーに関連するメモを取得
val deleteMemo = Memo.filter(_.userId in deleteUser.map(_.id))
//削除するユーザーに関連するメモに関連するラベルメモ(中間テーブル)を取得
val deleteLabelMemos = Labelmemo.filter(_.memoId in deleteMemo.map(_.id)).result//<- ここ注目
注目すべきところは最後のdeleteLabelMemosだけ.resultがついている部分である。
resultをつけるとクエリが一旦実行されるので、それをflatMap等するとその結果を用いて再びアクションを実行できる。
逆にresultがついていないところはまだ評価されていないという状態。
SQLが確定していないという意味でもある。
例えば
User.filter(_.id === userId.bind)//db.runにかけると SELECT * FROM users WHERE id=? となる
User.filter(_.id === userId.bind).delete//db.runにかけると DELETE FROM users WHERE id=? となる
という感じで、resultが呼ばれるまではSQLが確定していない。
これによりいい感じにSQLが発行されるのだが、問題にもなる。
例えば今回のコードは一見これでいいように見える
val deleteUser = User.filter(_.id === userId.bind)
val deleteMemo = Memo.filter(_.userId in deleteUser.map(_.id))
val deleteLabelMemo = Labelmemo.filter(_.memoId in deleteMemo.map(_.id))//削除するメモのidでラベルメモのフィルタリング
val deleteLabel = Label.filter(_.id in deleteLabelMemo.map(_.tagId))//削除するラベルメモのidでラベルのフィルタリング
db.run(
DBIO.sequence(Seq(
deleteLabelMemo.delete,
deleteLabel.delete,
deleteMemo.delete,
deleteUser.delete
)).transactionally
).map((result: Seq[Int]) => Ok("ユーザーを削除しました。"))
しかし、これをやるとuser, memo , labelMemoは削除されるがlabelは削除されない。
理由は以下のような感じ。
db.run(
DBIO.sequence(Seq(
deleteLabelMemo.delete,//Labelmemo.filter(_.memoId in deleteMemo.map(_.id))が評価され、ラベルメモが削除される。
deleteLabel.delete,// Labelmemo.filter(_.memoId in deleteMemo.map(_.id)) が評価されるが、すでにラベルメモは削除済み。よって1つも削除されない。
deleteMemo.delete,
deleteUser.delete
))
遅延評価なため、labelmemoが削除された後に再び Labelmemo.filter(_.memoId in deleteMemo.map(_.id))が評価され、それをサブクエリとしてin区で書いている。これでは取得できない。
そのため
//一旦このように書いてクエリを確定、
val deleteLabelMemos = Labelmemo.filter(_.memoId in deleteMemo.map(_.id)).result
// それをflatMapし、結果を用いてLabelMemoとLabelを削除
db.run(
deleteLabelMemos.flatMap(
result =>(Labelmemo.filter(_.id inSet result.map(_.id)).delete >> Label.filter(_.id inSet result.map(_.tagId)).delete)
)
とする。
また、ついでに連続してクエリ処理をするときは
andThen(>>)構文を使うか、DBIO.seq/DBIO.sequenceメソッドを使う。
使いかたはこんな感じ
- andThen
>>とかける。これで書くと順番に実行され、一番最後のアクションの結果が返る
db.run(
(deleteMemo.delete >> deleteUser.delete).transactionally
)
- DBIO.sequence/DBIO.seq
DBIO.sequenceはSeqに入ってるDBIOActionを逐次処理する。seq()とsequence()の違いは、seqの場合結果が破棄されるがsequenceの場合結果を戻す。
db.run(
DBIO.sequence(Seq(
deleteLabelMemo.delete,
deleteLabel.delete,
deleteMemo.delete,
deleteUser.delete
)).transactionally
)
これを書いて、最後にdeleteルーティングを加える。
GET /users controllers.HomeController.indexWithRelatedTable
GET /users/count controllers.HomeController.count
GET /users/add controllers.HomeController.add
GET /users/:userId/memos/add controllers.HomeController.addMemoAndLabel(userId:Int)
GET /users/:userId/delete controllers.HomeController.delete(userId:Int)//追加
# Map static resources from the /public folder to the /assets URL path
GET /assets/*file controllers.Assets.versioned(path="/public", file: Asset)
その後
-
/users/addにアクセスしてユーザー追加し、 -
/users/1/memo/addにアクセスしてメモとラベル追加 -
/usersにアクセスして追加されているのを確認 -
/users/1/deleteにアクセスして削除
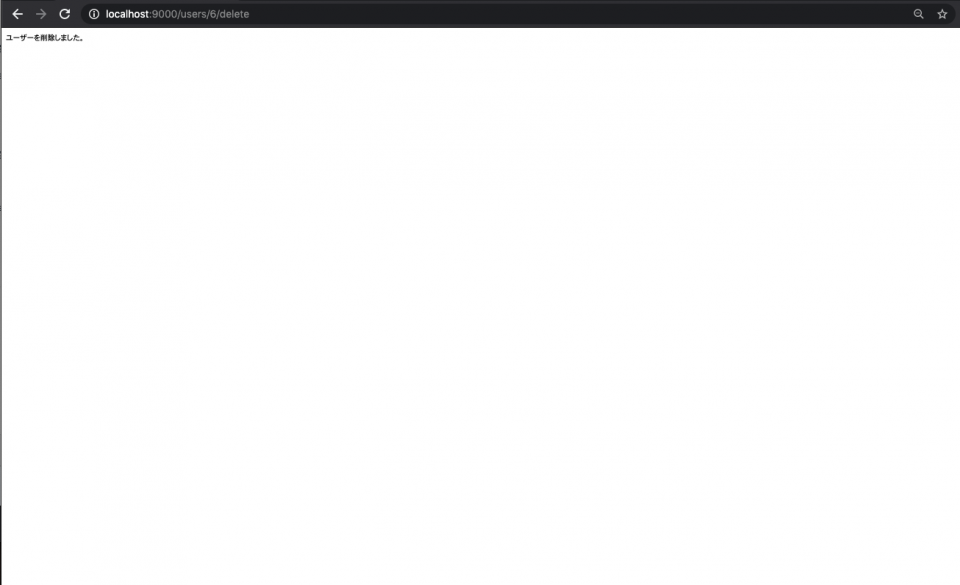
-
もう一度
/usersに行けば消えているはず。
以上。お疲れ様でしたー。
おまけ、PlayでのTips
-
maxConnectionsとnumThreadsという変数をconfigで指定するとconnection poolの設定ができる。設定は
slick.dbs.default.db内で行う。slick.dbs.default { dataSourceClass = org.postgresql.ds.PGSimpleDataSource profile="slick.jdbc.PostgresProfile$" db { driver=org.postgresql.Driver url="jdbc:postgresql://localhost:5432/gkassistantserver_development" databaseName = "gkassistantserver_development" user= "postgres" password="1115260m" numThreads=2 // maxConnections=2 }
}
```