1.ライブラリをインポート
pip install pillow
pip install pytesseract
2.Tesseract-OCRをインストール
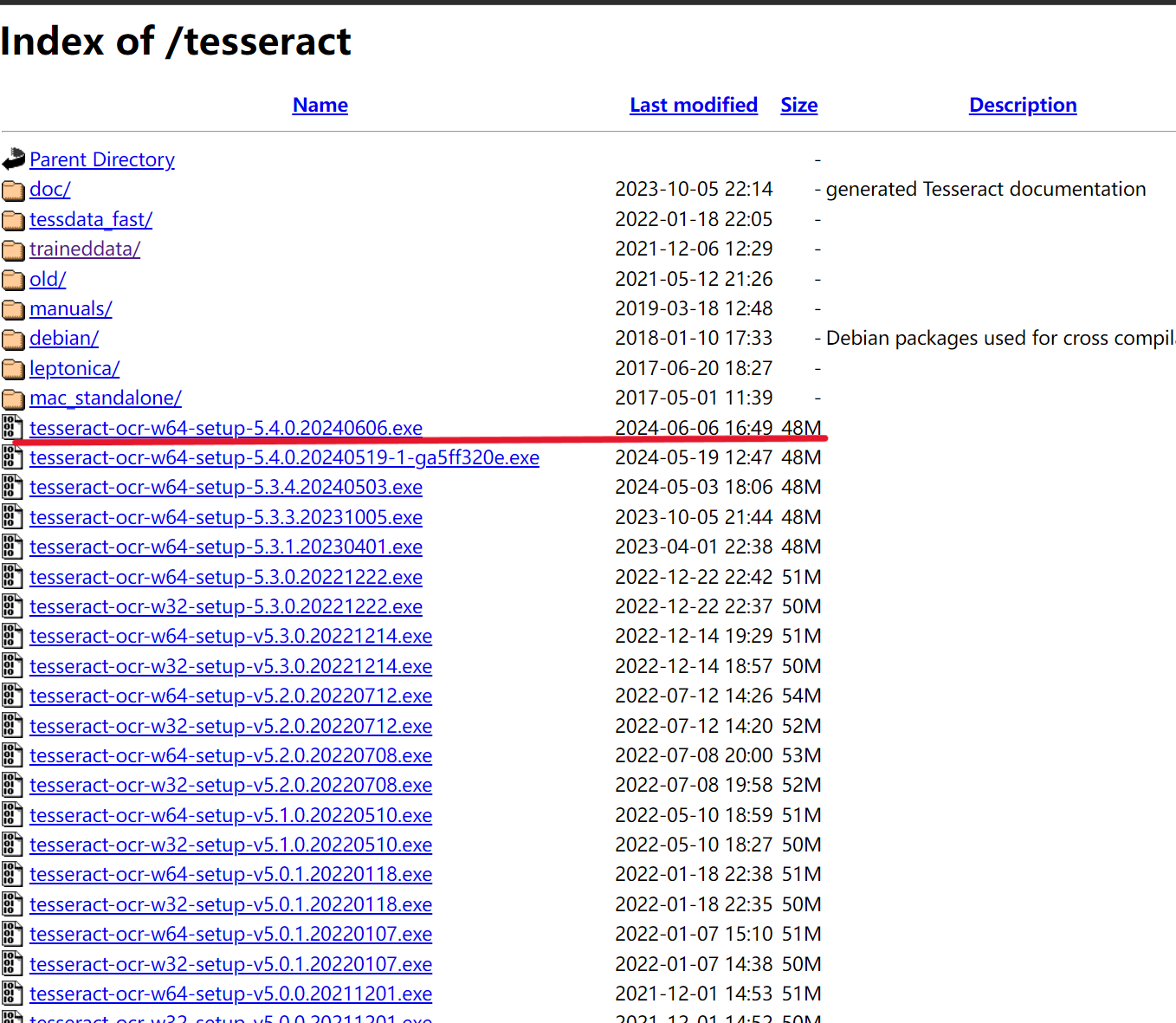
3.日本語のOCRの訓練データを取得
下記のサイトからダウンロードして、「Tesseract-OCR\tessdata」のパスに格納する
4.Pythonで画像から文字列を読み込み
from PIL import Image
import pytesseract
import os
# Tesseractのパスを指定
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 画像フォルダのパス
image_folder = 'C:/Desktop/pdf'
# 結果を保存するフォルダ
output_folder = 'output_txts'
os.makedirs(output_folder, exist_ok=True)
# 画像をループ
for image_file in os.listdir(image_folder):
if image_file.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tiff')):
# 画像のパス
image_path = os.path.join(image_folder, image_file)
# 画像を読み込み
image = Image.open(image_path)
# Tesseractを使って画像を読み込み
text = pytesseract.image_to_string(image, lang='jpn') # 'jpn' は日本語、英語の場合は 'eng'
# txtファイルを作成
txt_name = os.path.splitext(image_file)[0] + '.txt'
txt_path = os.path.join(output_folder, txt_name)
# 文字列をTXTに書き込み
with open(txt_path, 'w', encoding='utf-8') as txt_file:
txt_file.write(text)
print(f"{image_file} は {txt_name}に書き込みました")
print("完了")
下記のエラーが出た場合
modulenotfounderror: no module named 'pytesseract'
pip show pytesseract
# ⬇️こんな情報が出てくる
Name: {モジュール名}
Version: 0.13
Summary: {モジュール名} cryptographic signature library (pure python)
Home-page: http://github.com/xxxxxx/xxxxxx
Author: xxxxx xxxxx
Author-email: xxxxx@xxxxx.com
License: XXXXX
Location: /opt/anaconda3/envs/xxxxxxxx/lib/pythonX.X/site-packages -> このPASSをコピーする
Requires:
Required-by:
import sys
# passの設定 (pip showで出てきた、LocationのPASSを以下に設定)
sys.path.append('/opt/anaconda3/envs/xxxxxxxx/lib/pythonX.X/site-packages')
# passの設定はimportするモジュールより前に設定
import xxxxxx
参考サイト