はじめに
Clean Architectureやレイヤードアーキテクチャでは、どのようにレイヤーを定義するかついては言及されています。
そのような中usecase(レイヤードアーキテクチャではApplication層)をどのように実装するべきかについての議論は少ないです。
しかし私はリーダブルなアーキテクチャを実現するために、一番大切なことはusecaseを適切に実装することであると考えています。
そこでusecaseを実装する上で起こりがちな抽象度の問題を例に、リーダブルなアーキテクチャを考えいていきたいと思います。
サンプル
1:1のチャットアプリでUserとWorkerが存在して会話ができるアプリを例にあげます。
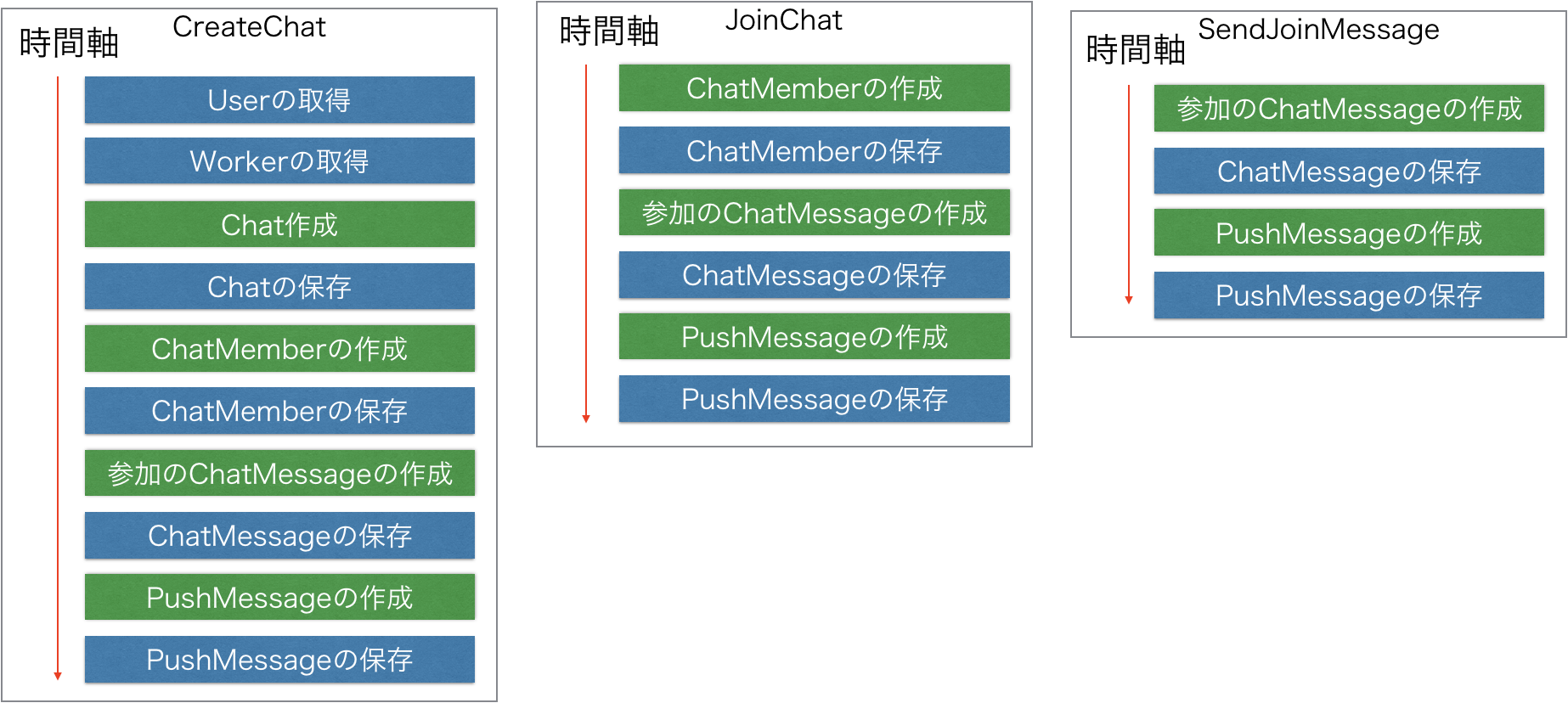
以下の図では青い背景はinfraの関数実行、緑色の背景はdomainの関数実行、赤い背景はusecaseの関数実行を示しています。
usecaseのCreateChat関数が以下のように存在しています。

しかしMessageの送信だけをしたいというユースケースがでたので関数を分離します。
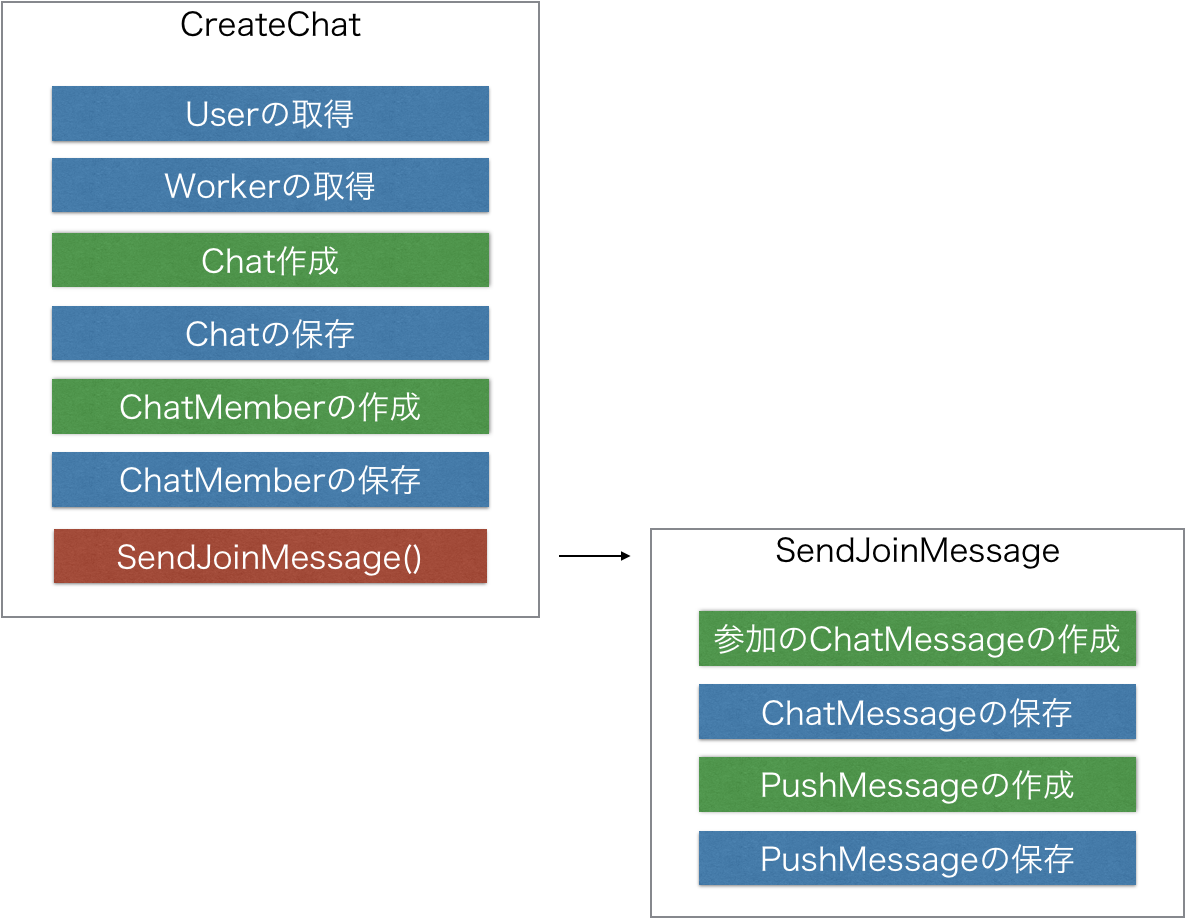
さらにメンバーの参加だけをしたいというユースケースがでたので関数を分離します。
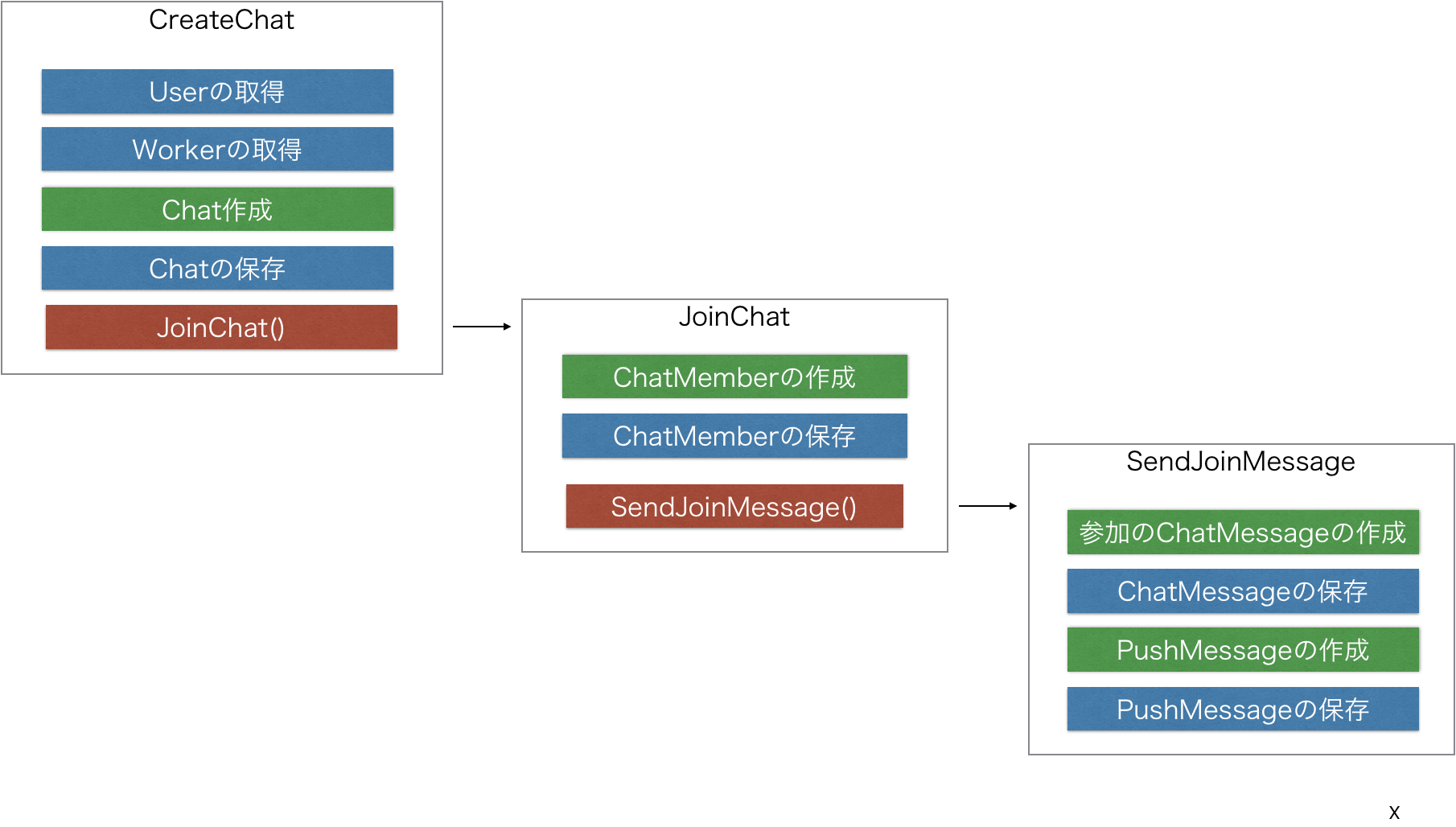
このような変更はよく起こると思いますが、問題はないでしょうか?
問題点
問題点1
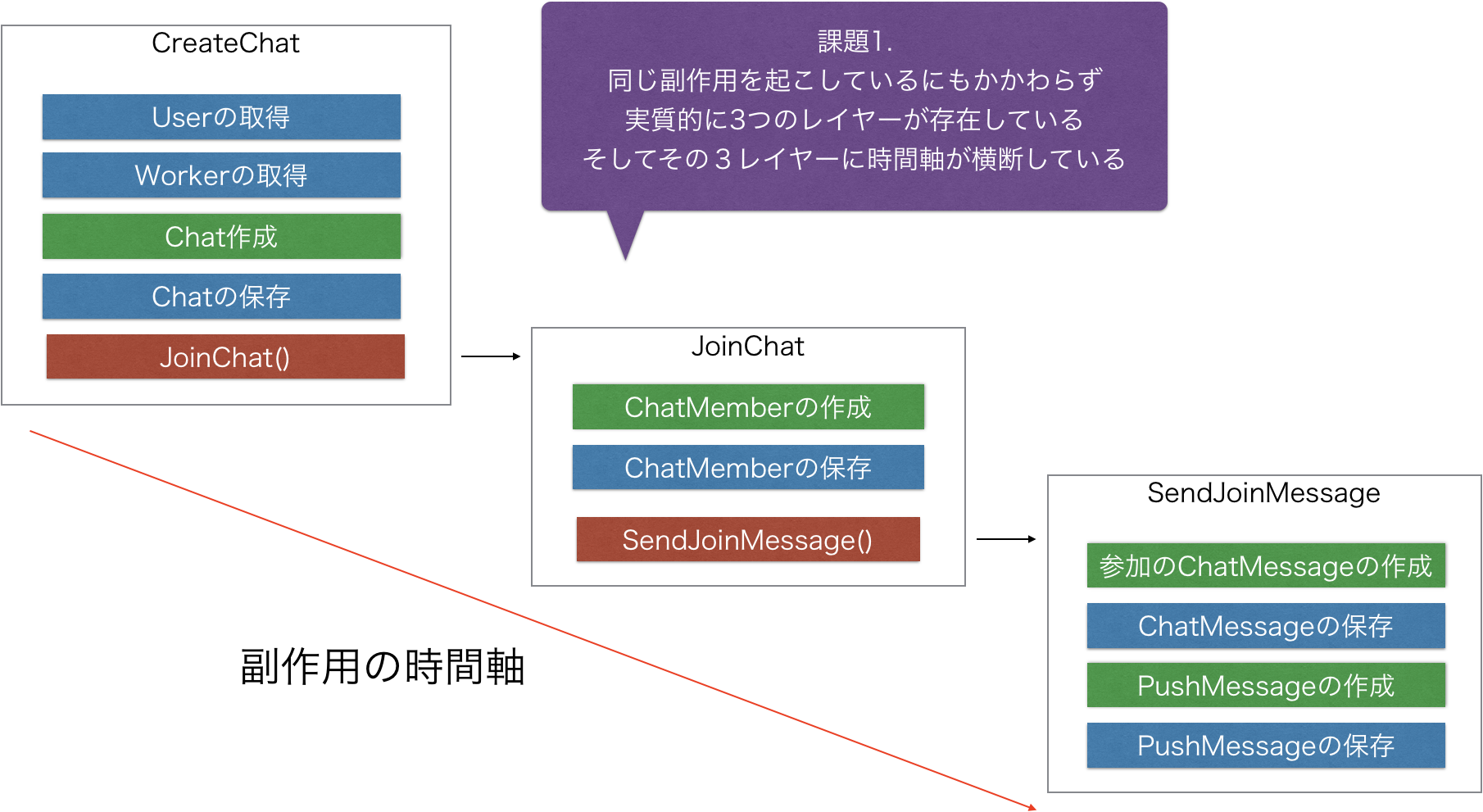
問題点2
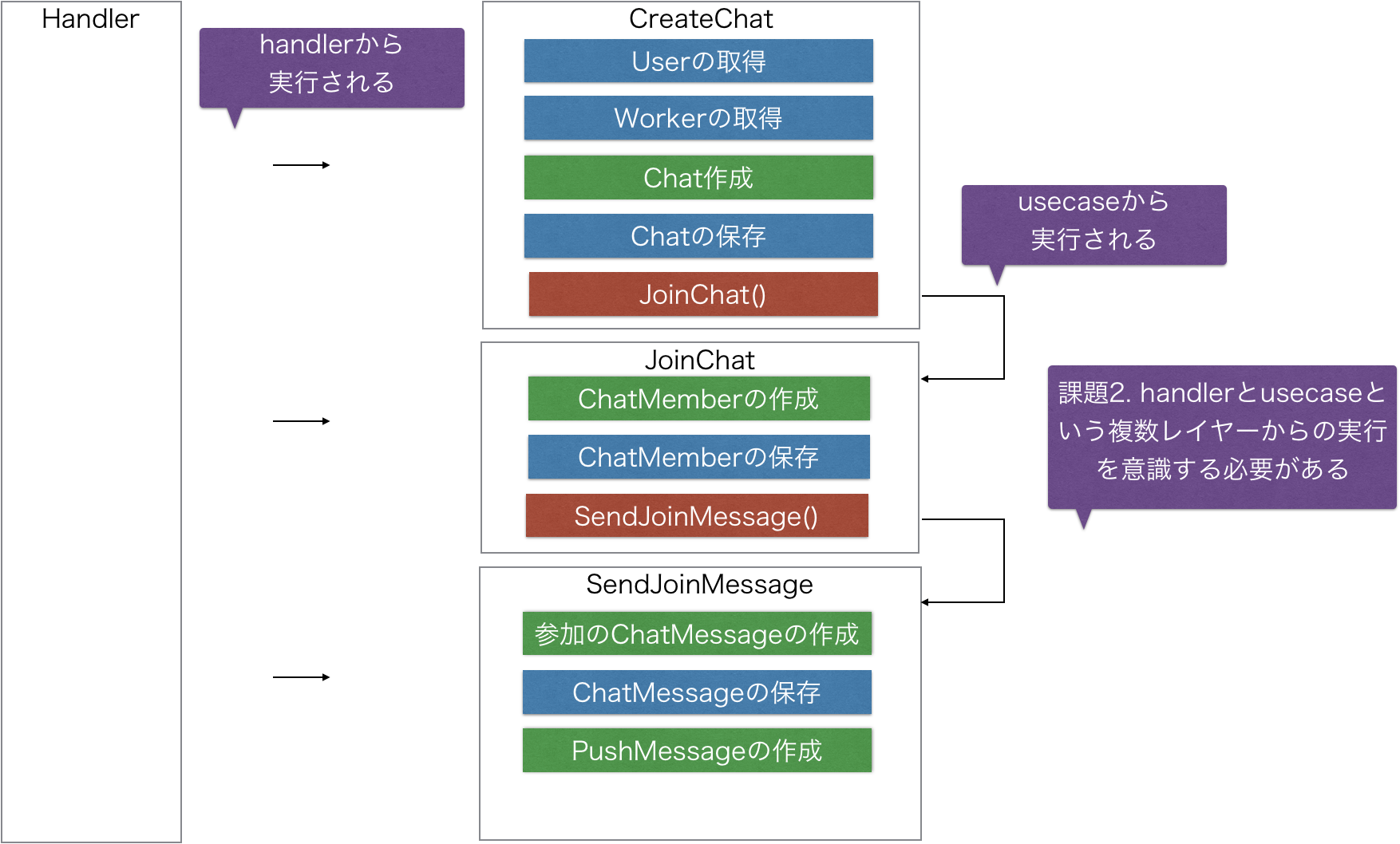
問題点3
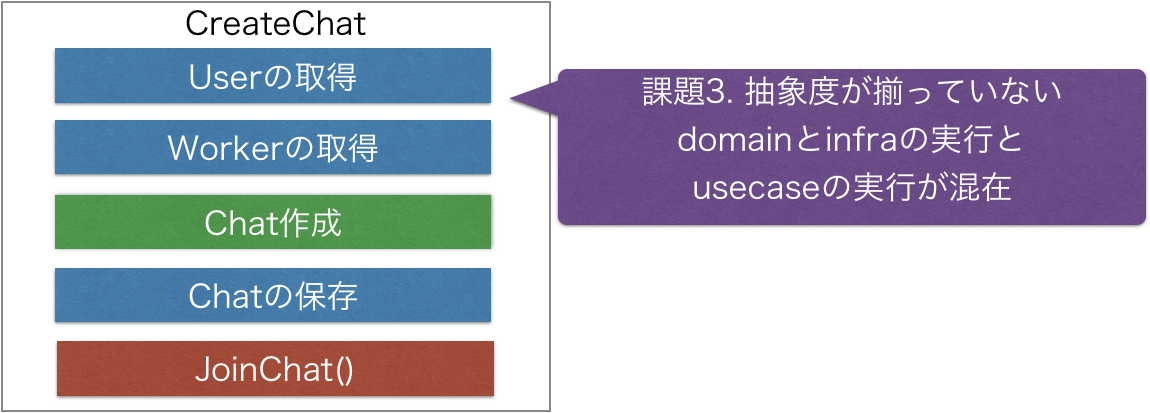
問題点4
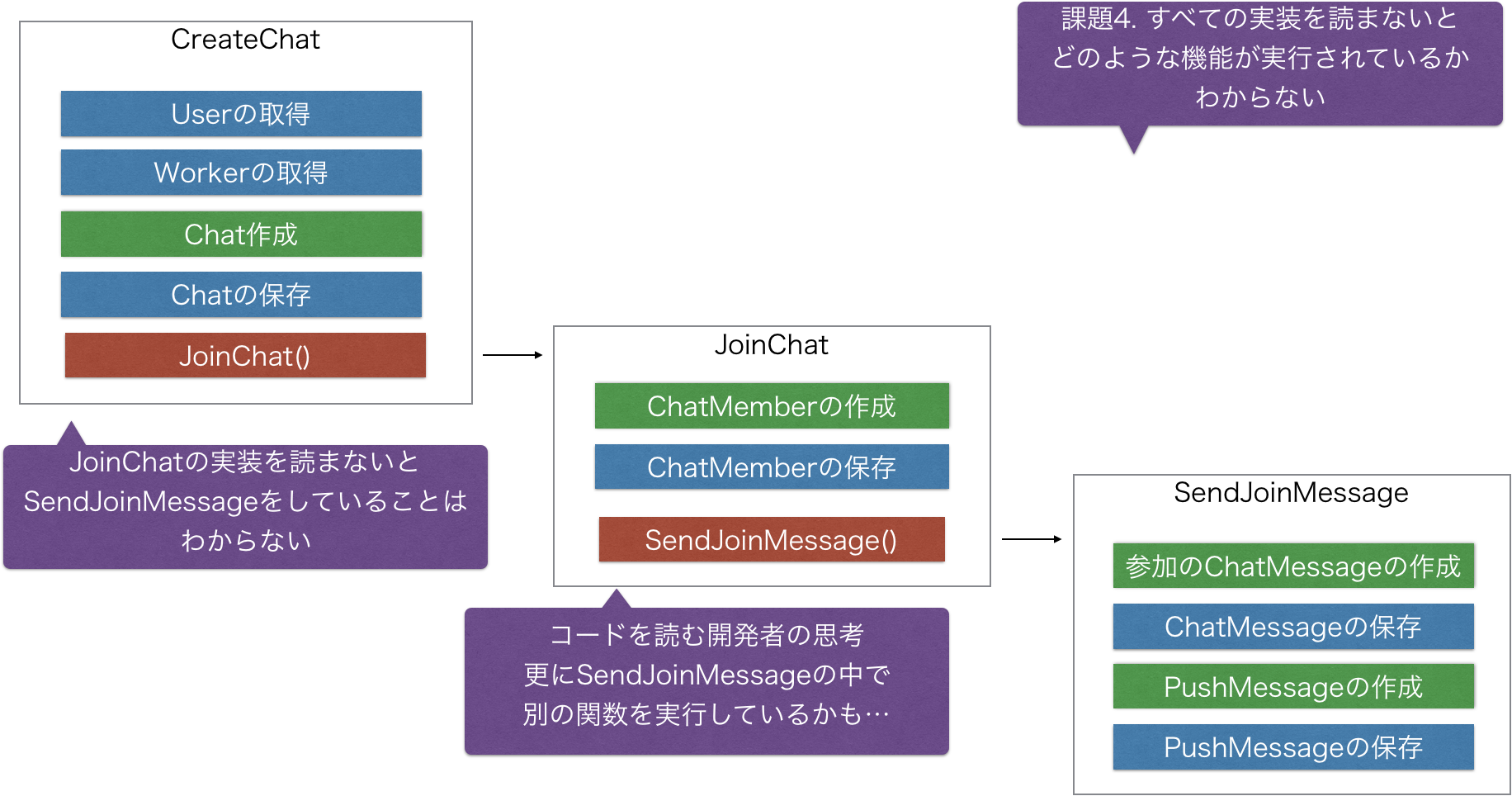
解決策
- 素直にべた書きをする
- Usecaseの中で時間軸を制御するレイヤーと機能を定義するレイヤーを分割する
解決策1. 素直にべた書きをする
usecase内での関数化を諦めて素直にべた書きをします。
こうすることでusecaseはdomainとinfraを実行するレイヤーとして抽象度が揃います。
複数のレイヤーの関数に時間軸の横断がなくなり、usecaseを読むだけでどのような機能が時間軸上で実現されているかを把握することが可能となりました。
すべての実装を読まなければ理解できなかったユースケースを、1つの関数内の関数実行だけを読めば理解できるようになりました。
適切にドメインやインフラを実装できていれば、usecaseにはロジックは登場せずほとんどがドメインとインフラの関数呼び出しをするだけになるはずです。
べた書きでusecaseの実装が複雑になるのであれば、そもそもの責務分割が間違っている可能性が高いので、安易にusecaseの関数に括り出すことはせず、まずはそちらを直せないかを検討するべきです。
解決策2. usecaseの中で時間軸を制御するレイヤーと機能を定義するレイヤーを分割する
どうしても解決策1を取りたくないというときには、usecaseの中で時間制御レイヤーと機能定義レイヤーを分割して、同じレイヤー間の実行を禁止します。
このとき時間制御レイヤーから機能定義レイヤーを実行することだけが許されます。また時間制御レイヤーではdomainとinfraの関数を絶対に実行しないことが大切です。これによりusecaseの抽象度が揃います。
複数のレイヤーの関数に時間軸の横断がなくなり、時間制御レイヤーを読むだけでどのような機能が時間軸上で実現されているかを把握することが可能となります。また機能を関数化も可能となりDRYになります。
これによりすべての実装を読まなければ理解できなかったユースケースを、1つの関数内の関数実行だけを読めば理解できるようになりました。
とはいえ、おすすめの解決策は圧倒的に解決策1です。
妥協案くらいに思ってもらえると良いと思います。
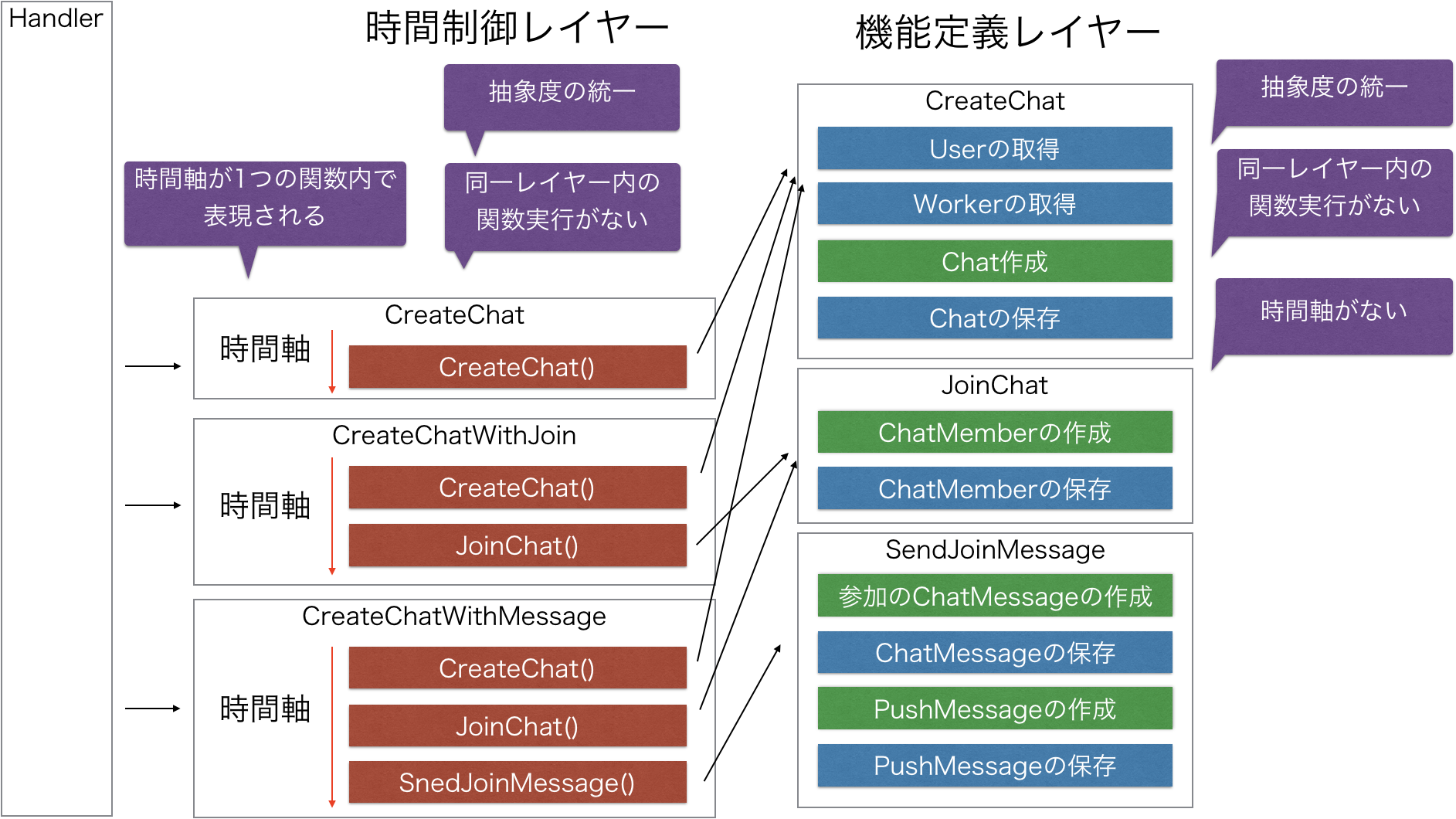
考察
domain、infraとusecaseの違い FunctionとFlow
doaminとPresentation(infra)を分割して、domainがPresentationに依存しないというPresentation Domain Separationはよく聞く話だと思います。
しかし今回はPDSだけでは捉えることができない点を、domainとinfraを機能を実現する同じ分類とし、usecaseを時間軸と副作用を制御する層として注目します。
ソフトウェア開発で大切なことの1つは副作用を制御することです。
バックエンド開発における副作用は大きく2種類存在しており、domainを操作することでのオンメモリ上での副作用とinfraを操作することでの永続化の副作用です。
domainとinfraは副作用を起こしますが、純粋な機能であり時間軸を持ちません。
usecaseでは、時間軸が存在しており、その時間軸の上でdomainとinfraを利用して副作用を制御する責務を持っています。
このとき**usecaseにdomainとinfraの機能が漏れ出してはいけません。**そうするとusecaseに機能と副作用の制御の責務が混在することなります。
domainとinfraをFunction(機能)と捉え、usecaseをFlow(時間軸)としてFunction Flow Separationという認識がとても大切です。
usecaseがusecaseを呼び出すことの問題点
usecaseがusecaseを呼び出すということは、関数を深く潜って実装を読んでいかないと副作用がどのように完了するかを理解することができません。
このようなコードは適切なレイヤー化が行われていないため、とても読みにくいコードとなります。
副作用が一目瞭然であるためには、1つのusecaseの関数にすべての副作用が表現されていることが大切です。
domain service
「usecaseからusecaseを実行する代わりにdomain serviceを実行しているから大丈夫」と思っている方がいるかもしれません。
しかしusecaseからdomain serviceを実行しているからOKとはなりません。もしdomain serviceがinfraを実行しているのであれば、それは名前がusecaseからdomain serviceに変わっただけで同様の問題を抱えています。
また私はdomain serviceでinfraを実行するべきではないと考えています。もしdomain serviceでinfraを実行しているのであれば、それはdomain serviceではなくusecaseです。domain serviceは永続化に関する処理をするべきではありません。
何故解決策1がおすすめなのか
解決策2は機能定義レイヤの関数の大きさ、入出力の受け渡し方、トランザクションの管理など設計で考慮するべきことが増えます。また複数のusecaseの関数から実行されることも考慮しなければなりません。
機能定義レイヤーといっても、Usecaseの都合で設計変更が行われる可能性が高いです。つまり純粋な機能ではありません。
また機能定義レイヤーを再利用したいがあまりにフラグを渡して、Aの場合はこの処理、Bの場合はという条件分岐が発生するような論理的凝集の設計が起こる可能性があります。これはusecaseが機能定義レイヤーに漏れ出していることを意味します。
このように機能追加のたびに新たな設計要素が増えることがデメリットです。私はこのデメリットをDRYによる修正漏れが減るというメリットが大きく上回らないと考えています。
解決策1をしたときに修正漏れが起こるケースを考えてみます。
domainとinfraは適切に設計されていれば起こり得る変更は以下の2つに絞れます。
-
domainやinfraの入出力が変わった場合
型の変更によりコンパイルエラーになるため漏れは発生しません。 -
usecase内に新たに機能を追加(削除)する場合
もし新たな機能の実行が機能定義レイヤーに含まれるのであればこれは解決策2のメリットになります。
そうでなく新たな関数を定義して、時間制御レイヤーから実行しなければいけないのであれば、どちらでも修正漏れは起こりえます。
このようにDRYにするメリットは大きくありません。
これらはチームの規模や状況によると思います。自分のチームではDRYのメリットが設計が複雑になるデメリットを上回るかを考えて、解決策1と解決策2を選択してください。
まとめ
usecaseを実装する際に陥りがちな問題について説明しました。
コードを読む際に1つのレイヤーの抽象度が揃っているということはとても大切なことです。 SLAP(Single Level of Abstraction Principle)という原則も存在しています。
しかしDRYを突き詰めるあまりにそれが破綻してしまうことがあります。
そのDRYのための関数化は本当に必要なのかを考え、まずはusecaseの実装を適切にドメインやインフラに委譲できないかを考えます。どうしても関数化する必要に迫られたら時間軸と副作用の制御が必要なレイヤーとそうでないレイヤーを明確に責務を分けることで解決します。
最後にusecaseを実装する際の注意事項をまとめます。
- usecaseにdomainとinfraの機能の実装が漏れてはいけない
- 1つのusecaseの関数にすべての副作用が表現されている
- usecaseの抽象度が揃っている
- domain serviceでinfraを実行しない
関連
ユースケースの書き方についてまた別視点でまとめた資料があるのでご参考ください。