seq2seqによる機械翻訳の仕組みについて理解を深めるため、Kerasを用いたseq2seqのサンプルコードについて調査しました。私がこれまで学んできた一般的なディープニューラルネットワーク(DNN)やCNNと比べると、モデル定義や推定処理等の実現方法が色々異なっており初見では取っ付きにくかったので、調査結果を備忘録として本記事に残すことにしました。
はじめに
この記事のゴール
seq2seqのサンプルコードで使用されているモデル構造や処理フローの全体像について把握することで、seq2seqの仕組みについて理解する
この記事の対象者
- 深層学習や機械翻訳の初学者
- パッケージ化されたseq2seqのAPIではなく、KerasのLSTM等を用いたseq2seqの実現方法について興味がある方
※サンプルコードの動かし方については本記事では扱いません。
サンプルコード中のコメント文の説明で動かし方が記載されていますので、興味のある方はそちらをご参照下さい。
参考元のソースコード
下記のGitHubで掲載されているサンプルコードを参照し、本記事で解説させて頂いています。
https://github.com/awslabs/keras-apache-mxnet/blob/master/examples/lstm_seq2seq.py
※上記のコードは下記URLのkeras-team様のコードからforkしたものであるようですが、keras-team様のGitHubコードはその後更新されており、現時点では所々差分がありますのでご留意ください。(見比べたところモデルの構成や処理フローに大きな変更はありません)
https://github.com/keras-team/keras-io/blob/master/examples/nlp/lstm_seq2seq.py
seq2seqとは
エンコーダとデコーダで構成される、機械翻訳で使用される深層学習アルゴリズムです。
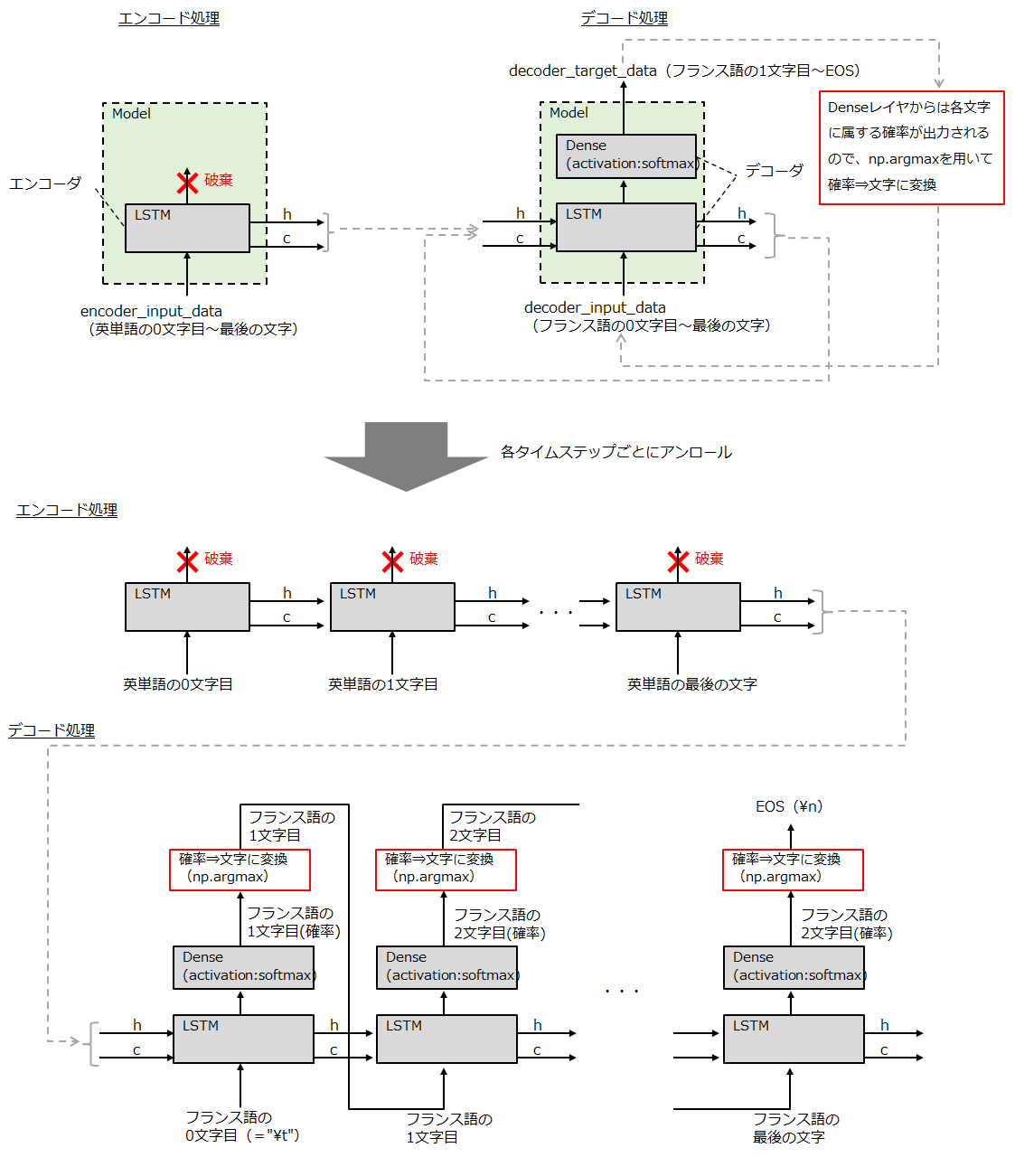
エンコーダは翻訳対象の単語を受け取ると、その単語の意味情報が圧縮された「状態」を出力してデコーダに受け渡し、それを基にデコーダが別言語の単語に翻訳するというものです。デコーダでは全文字を一発で出力するのではなく先頭から1文字ずつ出力し、出力した文字を用いてさらに次の文字を出力していくという流れで単語を翻訳します。
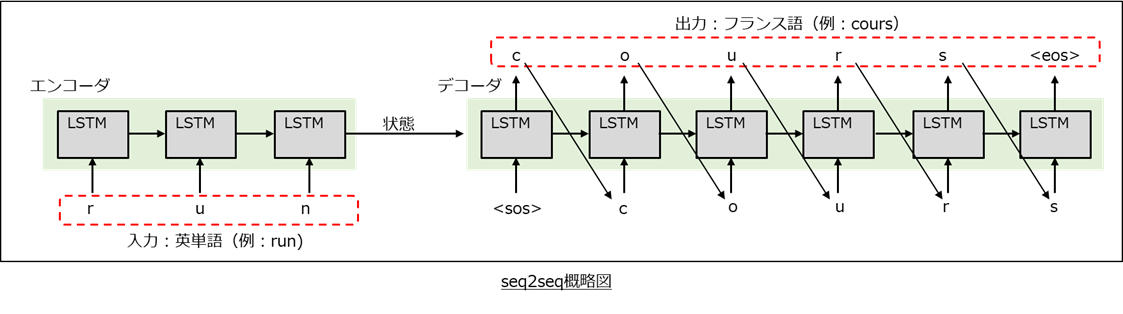
ソースコード解説
各処理の概要を順番に説明します。
学習データの用意
ソースコードのコメント文に記載されているURLから英語とフランス語の単語表のテキストファイルを入手し、それを1行ずつ読み取って下記の学習データセットを用意します。
- エンコーダの入力データ: 各行の英単語をOneHot表現に置きかえたもの
- デコーダの入力データ: 各行のフランス語の単語の先頭と終端にそれぞれSOS(\t)とEOS(\n)を付与し、OneHot表現に置きかえたもの
- デコーダの出力データの正解ラベル: デコーダの入力データを1文字ずつ手前にずらしたもの
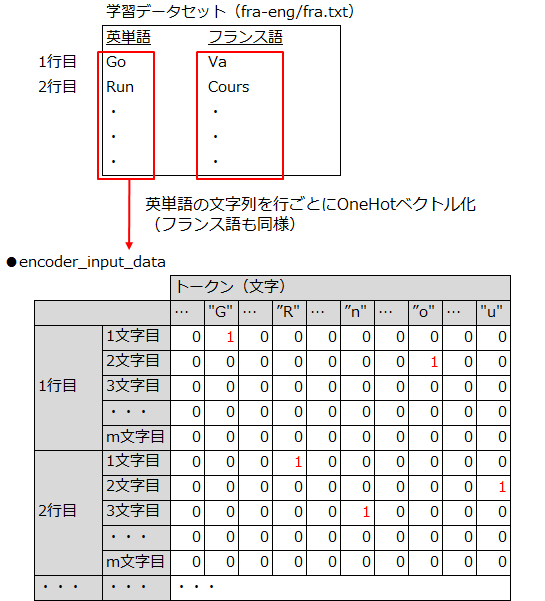
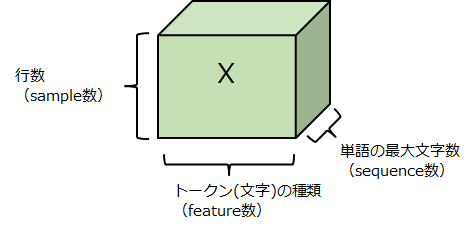
ちなみに上記の各入出力データは、各単語の文字をOneHotベクトル化したことで下図のような3次元データになっています。seq2seqでは各単語を文字が順番に並んだ時系列データとして扱ってLSTMで処理しているので、このような前準備が必要になるのですね。
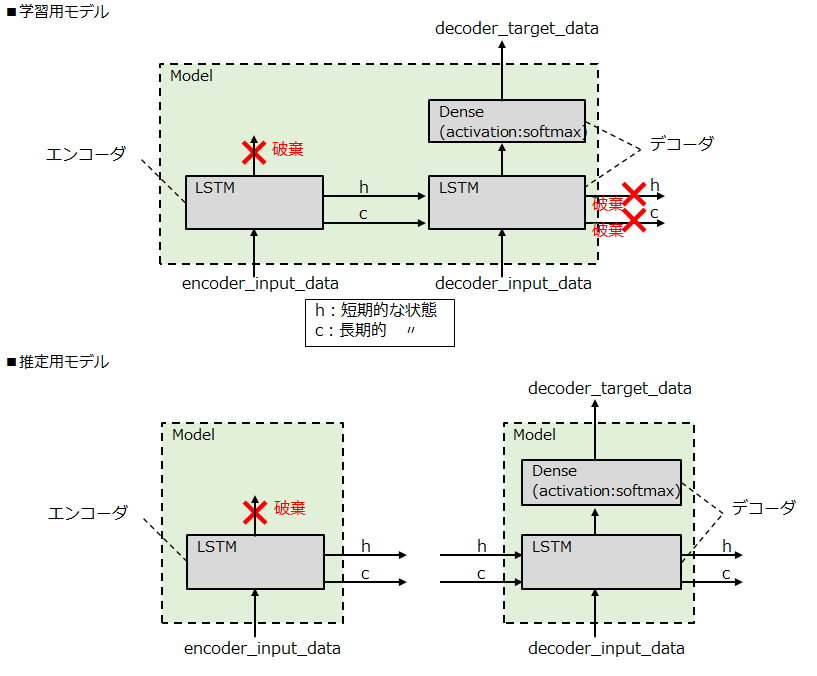
モデルの定義
モデルは主にエンコーダとデコーダで構成され、それぞれKerasのLSTMレイヤと、デコーダについては翻訳後の文字を推定するためのDenseレイヤ(全結合層)が使用されています。
また、一般的なDNNやCNN等では一旦モデルを定義したらそれを学習と推定の両方で使用するかと思いますが、seq2seqでは学習完了後にモデルを再定義して推定に使用しています。
- 学習時: エンコーダとデコーダを1つのモデルインスタンスにパッキングして定義
- 推定時: エンコーダとデコーダを別々のモデルインスタンスとして定義
なお、推定時にモデルを再定義する際には、学習で使用したLSTMやDenseレイヤのインスタンスを流用して推定用モデルを定義します。これによって、学習した各レイヤのパラメータを保持しつつも、学習時とは異なったモデル構造で推定処理を行うことが可能になります。(個人的にはこの発想が斬新でした)
学習処理
上記で用意したエンコーダとデコーダの入力データ、およびデコーダの出力データの正解ラベルを引数として、学習用モデルのfitメソッドを実行するだけです。fitメソッドの第一引数にエンコーダとデコーダの入力データをリスト化して与えている点以外は、特に変わった点はありません。
推定処理
推定処理は若干複雑です。通常のDNN等ではpredictメソッドを1回実行するだけで各サンプルの推定処理が行われますが、このseq2seqではエンコーダとデコーダで個別にpredictを実行し、さらにデコーダの方では1文字ずつpredictを行い、その出力をさらに次のpredictの入力に手動で渡している点が特徴です。
具体的には、以下の処理を各英単語ごとに実行し、フランス語の各単語を出力していきます。
① 英単語をOneHotベクトル化したデータを入力として、エンコーダモデルのpredictメソッドを実行
⇒ 英単語の意味情報が圧縮された状態変数(h,c)が出力される。
② エンコーダモデルから出力された状態変数と、デコーダの入力データの初期値(\t)を入力として、デコーダモデルのpredictメソッドを実行
⇒ 状態変数とフランス語の1番目の文字が何であるかを示す確率が出力されるので、
np.argmaxやインデックス⇒フランス語文字への変換テーブルを用いて
フランス語文字へ変換する。
③ ②で出力された状態変数と、②で推定したフランス語の文字をOneHotベクトル化したものを入力として、デコーダのpredictメソッドを実行
⇒ 再度状態変数と次のフランス語の文字の推定値が出力されるので、②と同様にして
フランス語の文字に変換する。以降、EOS(\n) or フランス語単語の最大長に
達するまでこれを繰り返す。
さいごに
以上、Kerasを用いたseq2seqのサンプルコードの解説でした。
実際に機械翻訳を実装する際にはパッケージ化されたライブラリ(TensorFlowのAddonプロジェクト等)や翻訳サイト等が公開しているWebAPIを使用することが多いかと思いますが、seq2seqの仕組みの理解の際にご参考にして頂ければ幸いです。