本記事では、競技プログラミングの初心者たちに数多の困難を与えているであろう、動的計画法(以下DP)を辞書型データ構造で実装します。読者対象は、DPが苦手な人、飲み込めていない人です。より正確な読者対象は、「漸化式とDPテーブルの意義or存在に疑問を持っている人」です。「DPの多様な問題の各解法を覚えられない人」ではありません。特に私のような、高校や大学で計算科学を正式に学んでいない独学と趣味の皆様のお役に立てば幸いです。
いわゆるDPテーブル(DP配列)と漸化式を使った動的計画法は、特定の問題を効率的に計算・解決できます。ここでの問題は、DPの解法がよく練られているせいで、初心者的な発想(樹形図的な発想)と標準的なDPの説明の間に乖離が存在することです。DPを初めて学ぼうとする人々の何割かはこの乖離のために疑問を抱え、そのモチベーションを下げてしまいます。DPの理解のためには初等的な解法、教育的なステップが必要だと感じます。この解決のために、本記事では樹形図と辞書による実装を紹介します。
この辞書によるDPの実装については、私も他人様(ひとさま)のコードを読んで知りました。私自身、DPテーブルと漸化式の組み立て方が飲み込めていない時に、競技プログラミング(AtCoder)で他人のコードを読んで感心し、それ以来、DPについては辞書で実装しています。DPについて調べても、辞書を使った実装を紹介している記事が無かったので、本記事を書きました。
「DPの標準的な説明を飲み込めない人、DPを苦手な人は何をするべきか?」という主旨の記事はほぼありません。DPの標準的な説明を噛み砕こうとしている記事は多いのですが、結局DPテーブルと漸化式の範囲での説明なので、苦手意識のある人からすればなかなか受け入れがたいかもしれません。私が調べた中では、以下の記事がDPを苦手な人のために書かれていました。
・動的計画法が苦手な人が、動的計画法が超苦手な人へアドバイスしてみる(じじいのプログラミング)
本記事では、辞書を使ったコードを紹介してから、辞書キーについての注意点、辞書による実装の限界とDPテーブルの有用性について述べ、最後に樹形図から漸化式とDPテーブルへの展開、そして「配るDP」と「貰うDP」についての妄想を述べます。
1. ナップサック問題、樹形図と辞書による実装
1-1. 樹形図
本記事では樹形図の細かい説明はしません。念のため書いておきますと、本記事における「樹形図」は、品物あるいは文字あるいは数字を「追加する・追加しない」の選択による、状態の変化を可視化したものです。
記事の以下の部分では、「発散する樹形図」と「収束する樹形図」という単語が出てきますが、「発散する樹形図」は、例えば初期状態から品物の追加・不追加によって状態が増加するような、多くのみなさんがまず思い浮かべるであろう樹形図です。「収束する樹形図」は、「発散する樹形図」とは逆の、複数状態から一つの値へと収束する樹形図です。問題の目的の値から、元の状態を見返し続けたときに辿れる樹形図です。
1-2. 辞書による実装
最初に辞書で実装したコードを紹介します。このコードは、アルゴ式の「典型的な動的計画法」の「ナップサック問題」の練習問題2で作動します。(アルゴ式の登録をおすすめします)
from collections import defaultdict
n, wlim = map(int, input().split())
d = [{0:0}]
# key = 重さの和
# val = 価値の和
for _ in range(n):
w, v = map(int, input().split())
d.append(defaultdict(int))
for key, val in d[-2].items():
# 品物を追加しない。同じ重さでより大きな価値なら更新。
d[-1][key] = max(val, d[-1][key])
# 品物を追加するが、制限重量以下。同じ重さでより大きな価値なら更新。
if key + w <= wlim:
d[-1][key + w] = max(val + v, d[-1][key + w])
# print(d[-1])
print(max(d[-1].values()))
変数名の付け方に癖がありますがご容赦ください。変数「d」が状態を保存する辞書です。辞書データの中身は「重量の和:価値の和」であり、「d = [{0:0}]」が重さ0価値0の初期値です。二重のfor文の中で以前の状態を読み込み、新たな品物の追加・不追加によって状態が増えていきます。
通常は、最大値、最小値、通り数などを辞書の値に設定し、一方で重量や座標など、状態が重複するときに樹形図の枝刈りに用いられる変数を辞書のキーに設定します。
上記のコメントアウトされている「print(d[-1])」で、品物の追加による状態の増加を確認できます。例えば、上記の練習問題2の入力例1については、以下の内容が出力されます。
{0: 0, 2: 3})
{0: 0, 1: 2, 2: 3, 3: 5})
{0: 0, 1: 2, 2: 3, 3: 6, 4: 8, 5: 9, 6: 11})
{0: 0, 1: 2, 2: 3, 3: 6, 4: 8, 5: 9, 6: 11, 7: 10, 8: 12})
{0: 0, 1: 3, 2: 5, 3: 6, 4: 9, 5: 11, 6: 12, 7: 14, 8: 13, 9: 15})
{0: 0, 1: 3, 2: 5, 3: 6, 4: 9, 5: 85, 6: 88, 7: 90, 8: 91, 9: 94})
行頭の「defaultdict(,」を削除した後に、昇順に並び替えています。初期値を「0:0」として、最初のステップで「重さ2、価値3」の品物によって状態が増え、二番目のステップで「重さ1、価値2」の品物によって状態がさらに増えます。最終的に、制限重量以下の最大の価値は「重さ9、価値94」となります。
試しに、自身でこの入力例の樹形図を手計算してみて下さい。すると、どこかの段階で同じ重量で異なる価値の状態が得られるでしょう。そのような場合、プログラム上では同じ重量でより大きな価値に更新することによって不要な「枝」についての計算を回避しています。
2. 辞書キーについての注意点
辞書を使った樹形図の実装はシンプルですが、辞書のキーの設定については注意が必要です。例えばPythonでは、文字列や座標を記したタプルをキーに設定すると、それだけで時間を大幅に消費します。
私の以前の記事「【python】辞書キーのデータ構造による計算時間の違い、タプルと整数と文字列と二重辞書」では、文字列のキー、タプルのキー、整数のキー、及び二重の辞書構造について、値の追加と参照について実時間を計測しました。二重のfor文を回して、計算量のオーダーはどれも同じです。ただ計算時間が異なりました。
文字列とタプルをfor文の前で作成した場合、文字列キーとタプルキーによる計算時間は整数キーと二重の辞書の時間の4倍と3倍でした。for文の中でキーを作成した場合は、文字列キーは8倍、タプルキーが4倍の計算時間になりました。考えられる原因は、文字列とタプルについての配列作成とハッシュ変換です。これ以上の詳細は私の理解の範囲外です。
おそらく、多くの(たぶん全ての)プログラミングコンテストの問題では文字列でキーを作ることはないでしょう。しかしタプルを使ったキーは、例えば二次元座標についての問題では使いたくなります。複数次元座標あるいは桁DPなどで添字を増やしたい場合、私は適切な値をかけて整数のキーにします。例えば、key = 100*x + y。この場合、負の座標値を正にするために一定数を加えるなどの前処理が必要です。辞書データを読み込むときにはdivmodで元のx, yに復元する必要がありますが、そのコストよりもタプルを使うコストのほうが大きいでしょう。
3. 速いのはDPテーブル
今回の樹形図と辞書による実装は、DPテーブルと漸化式に苦しむ人々にとって少しは役に立つと私は信じています。そして初歩的なDPの問題については、この辞書による実装でACできます。しかしやはり競技プログラミングの解法として速いのは漸化式とDPテーブルです(辞書型よりもリスト型のほうがアクセス速いはず)。樹形図と辞書による実装は理解しやすいですが、競技プログラミングでは練られた解法、不要な情報を落とした効率的な解法、の利用が想定されている問題も多々あり、知らなければTLEです。なので、やはりいくつかのDP問題については、DPテーブルと漸化式の解法とのセットで頭に入れておく必要があります。その一例を紹介します。
先に挙げた初歩的なDPの問題とは、例えばアルゴ式の「典型的な動的計画法」の問題中の、二次元ナップサックDP以外の問題です。中には桁DPやbitDPの知識が必要な問題もありますが、それらは必ずしもDPテーブルと漸化式とのセットではありません。紹介したいのは、個数制限付き(無し)部分和問題です。この問題については辞書で実装するとギリギリACで、DPテーブルの想定解法なら当然ACです。
けんちょんさんの記事「典型的な DP (動的計画法) のパターンを整理 Part 1 ~ ナップサック DP 編 ~」には「問題7:個数制限付き部分和問題」があります。この問題は、アルゴ式の「典型的な動的計画法」の「部分和問題とその応用たち」の練習問題5として出てきます。この問題は、名前の通り部分和問題の発展形です。
この問題について私が辞書と樹形図を使って実装したところ、その計算時間は約3200msでした。一方、解説のとおりにDPテーブルで実装したところ、約350msで済みました。以下に辞書と樹形図で実装したコードを載せます。
from collections import defaultdict
inf = 10**6
n, m = map(int, input().split())
# 初期値
d = [{0:0}]
for _ in range(n):
a, b = map(int, input().split())
d.append(defaultdict(lambda: inf))
for key, val in d[-2].items():
d[-1][key] = min(val, d[-1][key])
for i in range(1,b+1):
if key + a*i <= m:
d[-1][key + a*i] = min(val+i, d[-1][key + a*i])
else:
break
print("Yes" if d[-1][m] < inf else "No")
このコードは、部分和問題のコードに個数制限の処理を単純に追加したものです。辞書のキーがM以下であるため、計算量のオーダーは$O(NMB)$となります。正直、オーダー的にTLEだろうと思っていましたが、なんとか通りました。一方、問題の解説で提示されているコードの計算量は$O(NM)$です。解法の詳細は問題の解説を読んで頂くとして、この解法では個数制限の処理をMのループの中で処理しているためにBの計算量を省略できています。この場合、辞書の実装で同じ事をやろうとすると辞書のキーを昇順に並べる必要があり、それはもうDPテーブルの使用と変わりありません。
結論として、おそらく全てのDPの問題は樹形図と辞書を使って実装できるでしょうが、競技プログラミングの時間制限を克服するためにはDPテーブルと漸化式の多様な解法に目を通しておく必要があります。
4. 樹形図+辞書→配るDP→貰うDP
ここでは、発散する樹形図と辞書の実装をしながら感じた、「配るDP」と「貰うDP」についての妄想を述べます。
私の考える、DPについて理解しやすい流れは次のとおりです。
- 発散する樹形図を辞書で実装し、
- 「配るDP」のDPテーブルと漸化式を実装し、
- 収束する樹形図を使って「貰うDP」を実装する。
4.1 配るDP
本記事の「1-2. 辞書による実装」に出てくる計算結果の数字は、けんちょんさんの記事の「問題2:ナップサック問題」の説明用の表に出てくる数字そのままです。つまり当たり前とも言えますが、DPテーブルには樹形図の結果が埋め込まれています。
更に、選択肢の数が多い場合、辞書を使った実装は結局DPテーブルの使用と変わりありません。例えばナップサック問題の品物の数が20の場合($n=20$)、分岐する状態の最大数は$2^{20}\sim10^6$です。品物の重さと価値がある範囲でランダムで、重さ(整数)の制限が10000なら、取り得る重さの状態は0から10000の範囲をほぼ全て埋めているでしょう。さらに品物の数が100なら、とり得る状態を埋め続けながら計算を続けることになります。これはDPテーブルの更新そのものです。
発散する樹形図と「配るDP」について、以下の関係は受けいられると思います。
- 配るDPの漸化式 = 発散する樹形図における状態変化
さらにDPテーブルに樹形図の値が埋まっている事を考えれば、
- 配るDPの漸化式によるDPテーブルの更新 = DPテーブル中での発散する樹形図の構築
である事も理解できます。下の図は、配る形式のDPテーブル中に樹形図を重ねたものです。
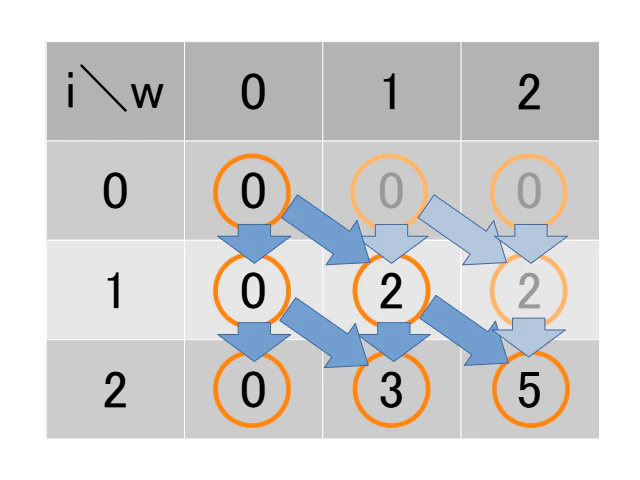
図示を簡単にするため、ナップサック問題について品物1は重さ1で価値2、品物2は重さ1で価値3、と設定しました。濃い色の表示が発散する樹形図です。
薄い色の表示にも言及しておきます。この薄い色の表示は、wの値だけずらした樹形図の値です。ナップサック問題ではある重さ以下での最大値が欲しいために、i=0での全てのwについて初期値を0にします。このように処理するとずらした樹形図を全て計算するので、DPテーブルの右下で必ず最大値を得られます。
例えば上記の図ではi=2、w=2で価値の最大値が得られます。では問題を変えて、品物はそのままでw=3での最大値を知りたいと設定します。そのときは、i=0、w=1をスタート地点とする樹形図がi=2、w=3に到達する事によって答えが得られます。
4.2 貰うDP
一方、「貰うDP」は目的の値から逆算した、収束する樹形図の構築に相当します。次の図は、先程のDPテーブルを「貰うDP」について強調したものです。
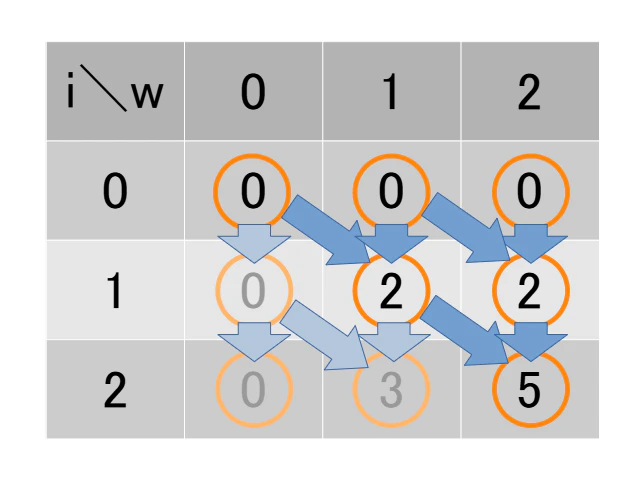
先程と同じように濃色の表示が「貰うDP」の樹形図を意味します。この樹形図は、目的の値へと収束していく、あるいは目的の値からiが小さくなる方向に発展する樹形図です。具体化してみましょう。
この場合、目的値となる値は、i=2、w=2の価値5です。次に一つ前の状態を考えます。品物2を加えられて価値5になる場合、一つ前の状態はi=1、w=1で価値2です。そして品物2を加えない場合、一つ前の状態はi=1、w=2で価値5です。さらにもう一段階戻ってi=0での状態を調べる事で逆向きの、収束する樹形図は形作られます。そしてi=0で一致する状態が存在すれば(この場合はもちろんi=0, w=0の価値0)、「貰うDP」の漸化式を使ってi=1から走査していく事で、解が得られます。
従って、収束する樹形図を想定していれば「貰うDP」の理解は容易であり、「貰うDP」の漸化式の構築も自然なことです。
4.3 なぜDPテーブルと漸化式が苦手だったのか?
自身の経験を振り返るに、自分が暗に発散する樹形図を想定していたのに対し、「貰うDP」の漸化式を説明されたことが、DPが分からなくなった原因、「漸化式とは何か?」という疑問を持った原因、漸化式が構築できなかった原因だと思われます。
今なら、「配るDP」も「貰うDP」も結局同じだと理解できます。ただその当時にDPの問題を解こうとするとき、頭の中の想定が品物の追加・不追加で状態が増えていく発散する樹形図に対し、そこで「貰うDP」の漸化式を構築しようとしても、その間のズレ、「なぜこの漸化式で良いのか?」という疑問を飲み込めずに苦手意識が強くなったように思われます。
そこで「貰うDP」の漸化式とDPテーブルから離れて、発散する樹形図を辞書で実装するようになってからは、(解説を読んで)DPの問題で要求されている樹形図が認識できれば実装でつまづくことは無くなりました。
私が本や記事の執筆者と講師などの指導する立場にある方々に提案したいことは、「配るDP」と「貰うDP」を説明するときに、想定されている樹形図をセットで説明する事です。そして、大抵の人は品物の追加・不追加による状態の増加について最初に発散する樹形図を想定するでしょうから、まずは「配るDP」を説明すると理解を得やすいと思われます。
まとめ、DPが苦手な人はどうするべきか?
- DPの説明を読んでも、DPテーブルと漸化式の存在あるいは構築方法を飲み込めない。
- DP問題の状態の増加を「発散する樹形図」的に考え、辞書を使って実装してみる。
- 辞書による「発散する樹形図」の実装が「配るDP」そのものだと悟る。
- 「貰うDP」は「収束する樹形図」の実装だと悟る。
- DPテーブルと漸化式への苦手意識が消える。
番外
- DPの多様な問題の解法が覚えきれない。
- ひたすら問題を解く。