きっかけ
https://qiita.com/dely13/items/5e949a384161c961d8ce
こちらの記事を読んで、遊び練習がてら自分で試していたら、結果が違うぞ→この記事2017年じゃん
と、なったので最新を出してみた(2020/6/29 10:00現在)
前半はそのまま
@dely13さんの記事をそのまま使います
import pandas as pd
import requests
import numpy as np
import seaborn as sns
from scipy import stats
import matplotlib.pyplot as plt
%matplotlib inline
url = "http://api.syosetu.com/novelapi/api/"
# APIのパラメータをディクショナリで指定する
# この条件で、総合評価順でjson形式のデータを出力する
payload = {'of': 't-gp-gf', 'order': 'hyoka','out':'json'}
st = 1
lim = 500
data = []
while st < 2000:
payload = {'of': 't-gp-gf-n', 'order': 'hyoka',
'out':'json','lim':lim,'st':st}
r = requests.get(url,params=payload)
x = r.json()
data.extend(x[1:])
st = st + lim
df = pd.DataFrame(data)
# 前処理('year'列追加、'title_len'列追加)
df['general_firstup'] = pd.to_datetime(df['general_firstup'])
df['year'] = df['general_firstup'].apply(lambda x:x.year)
df['title_len'] = df['title'].apply(len)
ホントにそのままなので詳しくは元の記事を読んでください
本題
2017年では
面白い数字です。平均値が17字ですが、これは俳句の文字数と同一ですね。
つまり、なろうのタイトルは俳句だったのです!
古池や 蛙飛び込む 水の音…
と言われましたが2020年では……?
df['title_len'].hist()
df['title_len'].describe()
ヒストグラム図 df['title_len'].hist()
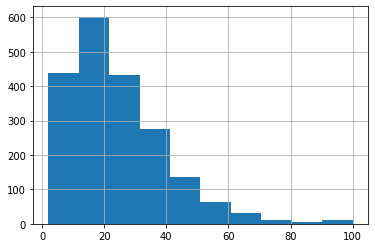
データ df['title_len'].describe()
count 2000.000000
mean 24.179500
std 15.528356
min 2.000000
25% 12.000000
50% 21.000000
75% 32.000000
max 100.000000
Name: title_len, dtype: float64
平均7文字増えとるwwwwww
そして本当に面白いのはここから
title_by_year = df.groupby('year')['title_len'].agg(['mean','count','std']).reset_index()
# プロット
title_by_year.plot(x='year',y='mean')
# データ
title_by_year
プロットtitle_by_year.plot(x='year',y='mean') ※mean=平均

集計title_by_year
|year |mean |count |std|
|--:|--:|--:|--:|--:|--:|
|2008 |7.500000 |2 |2.121320|
|2009 |12.428571 |7 |8.182443|
|2010 |10.882353 |17 |5.278285|
|2011 |10.180000 |50 |4.684712|
|2012 |13.294737 |95 |6.963237|
|2013 |14.115942 |138 |8.541930|
|2014 |16.065476 |168 |8.780176|
|2015 |18.218009 |211 |9.701245|
|2016 |21.577358 |265 |12.326472|
|2017 |24.476015 |271 |11.750113|
|2018 |29.425856 |263 |13.890288|
|2019 |31.327327 |333 |15.861156|
|2020 |40.483333 |180 |22.348053|
※2020のデータは6/29までのデータです
結論
2019年 なろうのタイトルは 短歌となる
2017年の記事で推測した人すっげぇ。ドンピシャじゃん。
余談1
せっかくなので最大・最小を出してみる
title_by_year = df.groupby('year')['title_len'].agg(['mean','min','max']).reset_index()
# プロット
title_by_year.plot(x='year')
# データ
title_by_year.plot
プロットtitle_by_year.plot(x='year')
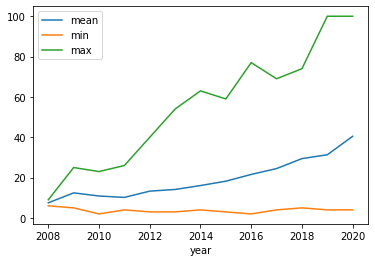
データtitle_by_year
|year |mean |min |max|
|--:|--:|--:|--:|--:|--:|
|2008 |7.500000 |6 |9|
|2009 |12.428571 |5 |25|
|2010 |10.882353 |2 |23|
|2011 |10.180000 |4 |26|
|2012 |13.294737 |3 |40|
|2013 |14.115942 |3 |54|
|2014 |16.065476 |4 |63|
|2015 |18.218009 |3 |59|
|2016 |21.577358 |2 |77|
|2017 |24.476015 |4 |69|
|2018 |29.425856 |5 |74|
|2019 |31.327327 |4 |100|
|2020 |40.483333 |4 |100|
この、100文字のデータって文字数オーバーしてるのでは……?
df[['ncode','title','year','title_len']].set_index('ncode').query('title_len==100')
| ncode | title | year | title_len |
|---|---|---|---|
| N7855GF | 無能扱いされて、幼馴染パーティーを追放された俺は外れギフト『翻訳』を駆使して成り上がる~馬鹿... | 2020 | 100 |
| N6203GE | 独裁王国を追放された鍛冶師、実は《鍛冶女神》の加護持ちで、いきなり《超伝説級》武具フル装備で... | 2020 | 100 |
| N0533FS | 【連載版】追っかけていたアイドルがイケメンと歩いている姿を目撃した俺は、バイト代はたいて買っ... | 2019 | 100 |
| N4571GF | ループ7週目で信じていた仲間たちに嵌められていたことを知ったので、8周目は能動的にパーティー... | 2020 | 100 |
・・・これ、100文字オーバーしてない・・・?
記事書いてから調べてみたら100文字きっかりでした

文字数制限があるのかな?
限界ギリギリで戦っているのはそれはそれですごい。
余談2
逆に短いタイトルが気になった
df.groupby('title_len')['title_len'].agg(['count']).head(9).T
文字数と作品数の対応一覧
長くなったので横配置
| title_len | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| count | 2 | 8 | 18 | 35 | 41 | 38 | 64 | 75 | 89 |
df[['title','year','title_len']].set_index('title').sort_values('title_len').query('title_len<5')
4文字は一部抜粋で
| title | year | title_len |
|---|---|---|
| 書簡 | 2016 | 2 |
| 払暁 | 2010 | 2 |
| 弓と剣 | 2013 | 3 |
| 水の理 | 2012 | 3 |
| 墓王! | 2013 | 3 |
| 幼馴染 | 2016 | 3 |
| 探索者 | 2013 | 3 |
| 塔の陰 | 2012 | 3 |
| 駆除人 | 2015 | 3 |
| 猫と竜 | 2013 | 3 |
| 忘却聖女 | 2020 | 4 |
| J/53 | 2012 | 4 |
| 黒の魔王 | 2011 | 4 |
| 私の従僕 | 2019 | 4 |
| モブの恋 | 2015 | 4 |
| 賢者の孫 | 2015 | 4 |
| セブンス | 2014 | 4 |
少ない文字でも有名どころはありますね。
元モバ民には4文字に「タイトル」とかあると感動した。
感想
モバ(現えぶぅ)ほどじゃないにしても初心者参入が多いのは携帯小説のアニメ化の影響か?
自分はモバに鍛えられたので多少読みづらくても内容が面白ければ読むけどそれにしてもタイトルが長い。
かという今ハマってるのこれとかこれもそこそこ長いタイトルだけど。(えぶぅだとこれ※ステマ)
なろうAPIで検索条件絞れるのでいろいろ試してみたいと思った。2000件以上抽出したい場合ってどうするんだろう……