やりたいこと
- とりあえずYolov5を動かしてみる
- 自分でアノテーションしたデータセットで学習させる
- 自分で学習させた重みファイルで認識させてみる
※精度は無視してとりあえず動かすことに重きを置いた記事です。
とりあえずYolov5を動かしてみる
Yolov5をダウンロード
githubからリポジトリをクローンしてくる。
作業フォルダをあらかじめ作っておくと良いかもしれません。
git clone https://github.com/ultralytics/yolov5
特に意味はないけどフォルダの画像を載せておきます。
必要なライブラリをインストールする
requirement.txtから必要なライブラリをインストールします。
仮想環境をあらかじめ作っておくと良いかもしれません。
cd yolov5
pip install -r requirements.txt
たったこれだけで準備完了です。
デフォルトのデータを使って認識
data/imagesフォルダの中にサンプル画像が格納されています。
このデータを用いて事前に学習済みの重みファイル「yolov5s.pt」を用いて認識させてみます。
python detect.py --source data/images/bus.jpg --conf 0.5 --weights yolov5s.pt
認識結果はruns/detectフォルダ内に出力されます。
yolov5s.ptはフォルダ内に見当たりませんが、detect.pyの初回起動時に自動でダウンロードされるようになっているそうです。どうしても気になる方はこちらに入っているのでご確認ください。
自分でアノテーションしたデータセットで学習させる
アノテーションツール
2つアノテーションツールを紹介します。
- Roboflow
yolov5公式?なのかtutorial.ipynbで紹介されています。今回はこちらを使用しましたが、機能が充実していて使いやすいし共同作業ができるようです。しかし、欠点としてはアカウント登録が必要なところや商用利用の場合は商用アカウントの登録が必要??そうです。これは自分では調べていないので商用利用する方は調べてからご使用ください。

- LabelImg
こちらも使いやすいツールだと思います。pipでインストールも可能でアカウント登録も不要です。日本語対応なのもありがたいところです。
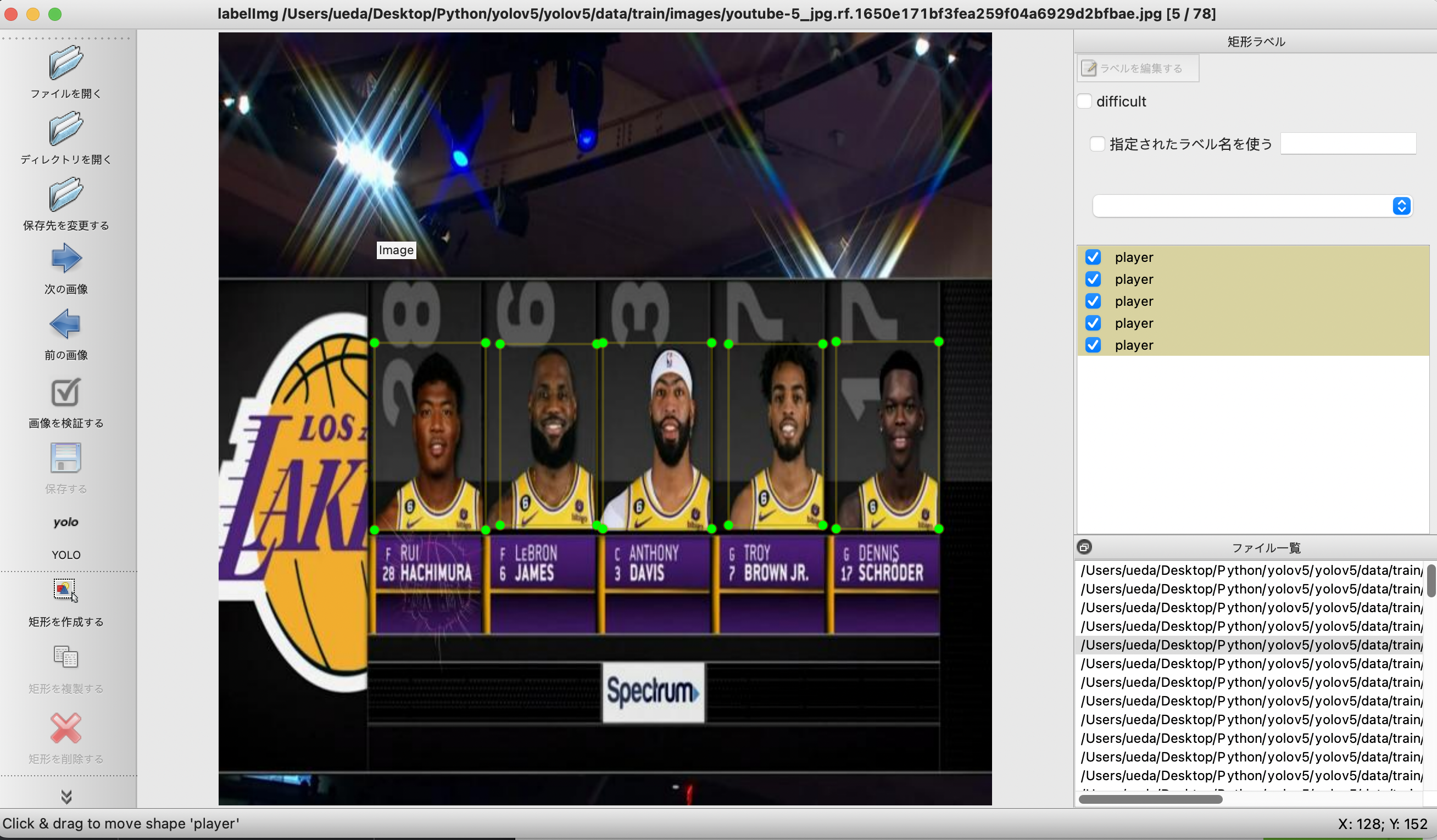
アノテーション
アノテーションの方法は長くなるのでここでは割愛いたします。
特に難しくもないので上記ツールを用いて検索を駆使すれば利用可能かと思います。
アノテーションをすると以下のファイルが作成されます。
Labelimgの場合は自分でファイル構成を整える必要があるかもしれないです。
images
┗ ****.jpg
labels
┗ ****.txt
学習させる
まずはyamlデータを作成します。
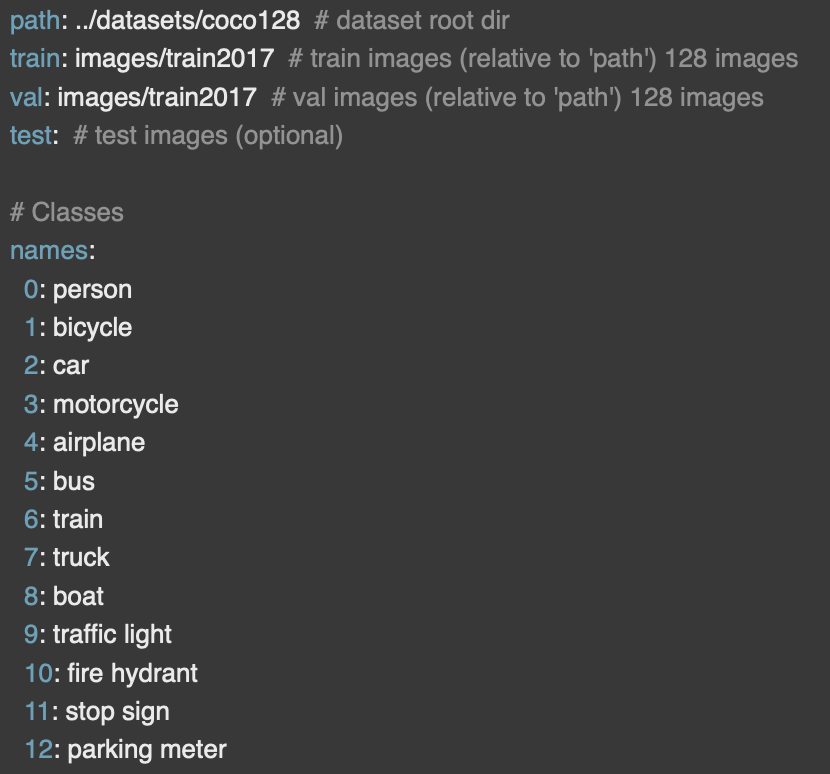
yamlデータはdata/data.yamlか以下を参考に作成してください。(train,validに分けないといけないんですかね。。。)
train: data/train/images # 学習の画像のパス
val: data/valid/images # 検証用画像のパス
nc: 1 # クラスの数
names: [ 'cat' ] # クラス名
coco128.yamlの中身を参考に載せておきます。
python train.py --data data/data.yaml --cfg models/yolov5s.yaml --weights '' --batch-size 8 --epochs 300
学習にはかなり時間かかります(CPUの場合)。私は120枚程度の画像で8時間以上かかりました。
学習結果はruns/trainフォルダ内に重みファイルが作成されます。
自分で学習させた重みファイルで認識させてみる
--source引数を0にするとWebカメラで、動画ファイルにすると動画ファイルを、画像ファイルにすると画像ファイルを、フォルダにするとそのフォルダ内にある画像全てに対して処理を実行します。ちなみに--view-img引数を取ると処理結果をWindowで表示してくれるようになります。
python detect.py --source data/images/ --weights best.pt
最後に
備忘録的に書いているのでもし分かりにくかったらすみません。
正直本家のtutorial.ipynbファイルがとても分かりやすく記載してくれているのでぜひそちらもみていただければと思います。