KINTO Technologies Advent Calendar 2021 - Qiita の11日目の記事です。
KTCでPlatformGroupのDevOpsサポートとして働いてます。アプリケーション開発者と運用者向けに、CICDツール周りの導入サポートや改善、標準化などを主に行っています。
2022/7/4にTASKごとにメトリクスを取得する方法を追記しました。
2023/11/28にawsprometheusremotewriteの非推奨(v0.21.0~)に伴う更新をしました。
はじめに
Amazon Managed Service for Prometheus(AMP)が発表されて、GAされました。
AMPはRemoteWriteのみでスクレイピングの機能がありません。AWSのドキュメントではCloudWatchエージェントもしくはAWS Distro for OpenTelemetry Collectorを使用するようになっています。
今回は、Java以外も見据えて、後者のCollectorを使ってメトリクスの収集まで行おうと思います。
※CloudWatchエージェントはJVMのみ対応のようです
前提条件
ECS
- クラスタとサービス、タスク定義が構築されていること
- Fargateを想定しています。EC2を使う場合は一部を読み替えてください
- アプリケーションはSpringBoot(Actuator)を使用したJavaアプリケーションの想定です
AMP(Amazon Managed Service for Prometheus)
- 長いので、PrometheusもしくはAMPと今後は記載します
- ワークスペースや各種権限が既に構築・設定されていること
- インターフェース型のVPCエンドポイントを作成すると内部通信にできますが、省略
- Grafanaを使った可視化についても詳細は省略しますが、Prometheusにデータがあるかどうか?という確認のため、ローカルで起動します
- AWS Grafanaだと権限とか気にしなくていいしCloudWatchとかX-Rayも連携するので、とっつく分には楽だと思います。知らんけど
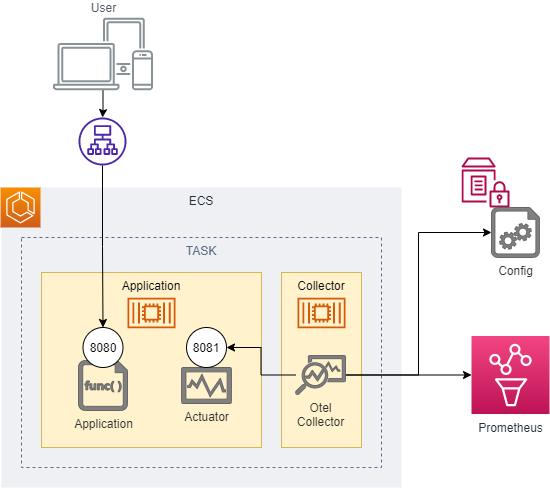
構成
AdotCollectorのデプロイは、クラスタにサービスとして登録するか、アプリケーションのサイドカーとして設定するかが選べますが、今回はサイドカーとしています。
設定
IAMの設定を追加する
タスク実行ロール(taskRoleArn)に対して、AMPへのRemoteWrite権限を付与します。
"aps:RemoteWrite"
必要に応じて、ResourceでAMPのWorkspaceを制限します。
Configを設定する
ECSの実環境では、ドキュメント上はParameterStoreに登録してTaskDefinitionの中から呼び出すようになっていますので、その通りにします。
Fargateを使用した場合の、adotCollectorのConfigサンプルは上記の通りです。
EC2なら、同じディレクトリにEC2向けサンプルがあります。
##
## AWS OTEL COLLECTOR CONFIG FOR ECS TASK
##
receivers:
prometheus:
config:
global:
scrape_interval: 30s
scrape_timeout: 20s
scrape_configs:
- job_name: {{ApplicationName}}
metrics_path: "/actuator/prometheus"
static_configs:
- targets: [ 0.0.0.0:8081 ]
awsecscontainermetrics:
collection_interval: 20s
processors:
filter:
metrics:
include:
match_type: strict
metric_names:
- ecs.task.memory.utilized
- ecs.task.memory.reserved
- ecs.task.cpu.utilized
- ecs.task.cpu.reserved
- ecs.task.network.rate.rx
- ecs.task.network.rate.tx
- ecs.task.storage.read_bytes
- ecs.task.storage.write_bytes
exporters:
prometheusremotewrite:
## ENDPOINTはAWS AMPの「エンドポイント - リモート書き込み URL」をそのまま使用する。
endpoint: {{endpoint}}
resource_to_telemetry_conversion:
enabled: true
auth:
authenticator: sigv4auth
logging:
loglevel: debug
extensions:
health_check:
sigv4auth:
service:
extensions: [health_check, sigv4auth]
pipelines:
metrics:
receivers: [prometheus]
exporters: [logging, prometheusremotewrite]
metrics/ecs:
receivers: [awsecscontainermetrics]
processors: [filter]
exporters: [logging, prometheusremotewrite]
- Endpoint
- ApplicationName
- スクレイピングの間隔
は個別値ですので適時修正してください。job_nameはGrafanaで検索する場合のApplicationNameに割り当たるので、アプリ事に個別にした方がわかりやすくなります。
上記のYamlをParameterStoreの
/common/ADOT_CUSTOM_CONFIG
に保存します。
タスク定義を更新する
Fargateを使用した場合の、ECSタスク定義のJSONサンプルは上記の通りです。
EC2なら、同じディレクトリにEC2向けサンプルがあります。
ContainerDefinitionsの部分に
{
"name": "aws-otel-collector",
"image": "public.ecr.aws/aws-observability/aws-otel-collector:latest",
"essential": true,
"secrets": [{
"name": "AOT_CONFIG_CONTENT",
"valueFrom": "arn:aws:ssm:***:***:parameter/common/ADOT_CUSTOM_CONFIG"
}],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/ecs-aws-otel-sidecar-collector",
"awslogs-region": "ap-northeast-1",
"awslogs-stream-prefix": "ecs",
"awslogs-create-group": "True"
}
}
"memory": 96,
"memoryReservation": 96,
"cpu": 128
}
を追記し、Collectorをサイドカーで起動するように変更します。
- CloudWatchのロググループ
- プリフェックス
- ParameterStoreのパス
- AWS REGION
などは適時書き換えてください。
CollectorのCPU、メモリについては追加設定で制限しました。
タスク定義をデプロイする
KTCではGithubActionsを使ってCICDを実装していますが、ここでは割愛します。
タスク定義のバージョンがあがり、正しく起動していることを確認します。
AdotCollectorのConfigミスとかParameterStoreの権限ミスとかTypoでCollectorコンテナが落ちたのでタスク全体が落ちるというミスをしましたので、ご注意ください。
Grafanaでデータを確認する
Grafanaをローカルで動かします。
権限周りは割愛しますが、apsの各種クエリを発行できるユーザを使用します。
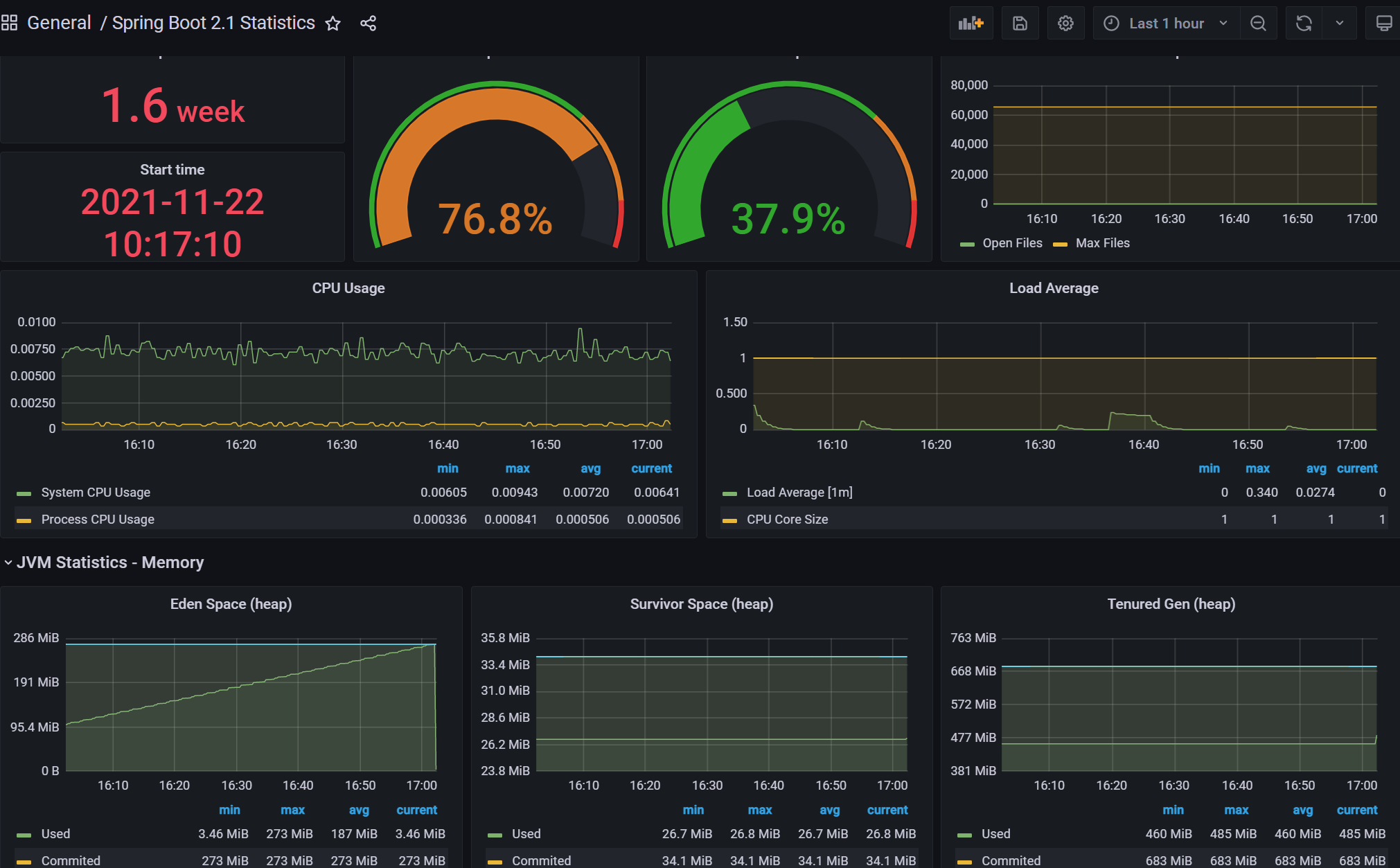
こちらのダッシュボードを利用しました。
うまくデータソースなどを設定できると、このように表示されるので、問題なくデータがプッシュされていることが確認できました。
Appendix(ローカルで動かす)
サイドカーではなく、アプリケーションコンテナと個別に独立して動かしています。
- ローカルで項目などがうまくAMPに登録できるか、可視化のPoCなどをするのに、ECSまで作ると手間
- アプリケーション向けにワークショップをしたい
ということで準備しました。
想定するディレクトリ構成は以下の通りです。
.
├── README.md
├── docker
│ └── otel
│ └── otel-local-docker-config.yaml
└── docker-compose.yaml
LOCALでAMPにプッシュする
Docker-Compose
# AWS OtelCollector
collector:
image: public.ecr.aws/aws-observability/aws-otel-collector:v0.13.0
container_name: aws-otel-collector
command: ["--config=/etc/otel-agent-config.yaml"]
## AMPへPUSHできる権限のあるユーザID/SECRETを記載する。
## 環境変数から呼び出す
environment:
AWS_ACCESS_KEY_ID: ${AWS_ACCESS_KEY_ID}
AWS_SECRET_ACCESS_KEY: ${AWS_SECRET_ACCESS_KEY}
AWS_SESSION_TOKEN: ${AWS_SESSION_TOKEN}
AWS_REGION: ap-northeast-1
## OpenTelemetoryCollectorのConfigを設定する。
volumes:
- ./docker/otel/otel-local-docker-config.yaml:/etc/otel-agent-config.yaml
- ~/.aws:/root/.aws
ports:
- 55680:55680
- 8889:8888
アプリケーションと同じdocker-compose.yamlに上記を追加します。適時、Configのパスやリージョンは書き換えてください。
Config
##
## AWS OTEL COLLECTOR CONFIG FOR LOCAL DOCKER/JAR APP
##
receivers:
prometheus:
config:
global:
scrape_interval: 30s
scrape_timeout: 10s
scrape_configs:
- job_name: {{ApplicationName}}
metrics_path: "/actuator/prometheus"
static_configs:
- targets: [ app:8081 ]
awsecscontainermetrics:
collection_interval: 20s
processors:
batch:
exporters:
prometheusremotewrite:
## ENDPOINTはAWS AMPの「エンドポイント - リモート書き込み URL」をそのまま使用する
endpoint: {{endpoint}}
resource_to_telemetry_conversion:
enabled: true
auth:
authenticator: sigv4auth
logging:
loglevel: debug
extensions:
health_check:
sigv4auth:
service:
extensions: [health_check, sigv4auth]
pipelines:
metrics:
receivers: [prometheus]
exporters: [logging, prometheusremotewrite]
targetsのappはdocker-composeのアプリケーションコンテナ名から引っ張っていますので、適時修正をしてください。
2022/7/4追記:Appendix(ECSのTaskごとにメトリクスを分割する)
ECSでTaskを動かす場合、ApplicationNameをSpringBootなどで入れておけば、Cluster内で複数のServiceを起動していてもある程度は集計結果を分割して確認できます。
が、ServiceのなかのTask単位で問題を見たいという場合は、何かしらの考慮が必要になってきます。
うちのSRE担当者がAWSサポートと話をして、CollectorのConfigでTask分割ができたので、そちらを追記します。
OtelCollectorのバージョンを上げる
本文中ではlatestとしていますが、実運用では本記事掲載時はv0.16.0を使用していました。が、このあと出てくるタスク定義のConfigで使用する設定がv0.18.0以降で動作確認できているので、v0.18.0にバージョンを上げています。
v0.15.1だとバグでNGで、動作確認時の最新のv0.18.0でOKでした。
OtelConfigを更新する
##
## AWS OTEL COLLECTOR CONFIG FOR ECS TASK
##
receivers:
prometheus:
config:
global:
scrape_interval: 30s
scrape_timeout: 20s
scrape_configs:
- job_name: {{ApplicationName}}
metrics_path: "/actuator/prometheus"
static_configs:
- targets: [ 0.0.0.0:8081 ]
awsecscontainermetrics:
collection_interval: 30s
processors:
resourcedetection:
detectors:
- env
- ecs
attributes:
- cloud.region
- aws.ecs.task.arn
- aws.ecs.task.family
- aws.ecs.task.revision
- aws.ecs.launchtype
filter:
metrics:
include:
match_type: strict
metric_names:
- ecs.task.memory.utilized
- ecs.task.memory.reserved
- ecs.task.cpu.utilized
- ecs.task.cpu.reserved
- ecs.task.network.rate.rx
- ecs.task.network.rate.tx
- ecs.task.storage.read_bytes
- ecs.task.storage.write_bytes
exporters:
prometheusremotewrite:
endpoint: {{endpoint}}
resource_to_telemetry_conversion:
enabled: true
auth:
authenticator: sigv4auth
logging:
loglevel: warn
extensions:
health_check:
sigv4auth:
service:
telemetry:
logs:
level: info
extensions: [health_check]
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [logging, prometheusremotewrite]
metrics/ecs:
receivers: [awsecscontainermetrics]
processors: [filter]
exporters: [logging, prometheusremotewrite]
AWSのサポートとも確認して、こうなりました。
詳しいところは割愛しますが、
- resourcedetection processorを使用してタスクごとのメタデータをメトリクスに付与する
- awsprometheusremotewrite exporterにresource_to_telemetry_conversionを追加
という形になっています。
DashBoardを更新する
既存のダッシュボードはTask分割などを考慮していない作りになっていまして、
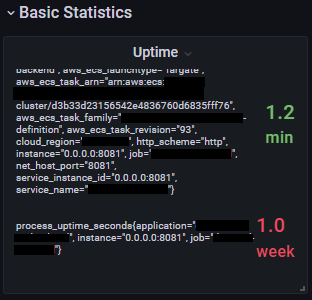
UptimeとかStartTimeとか色々とこんな感じに。特にStat表示周りがこうなります。TimeSeriesとかは線が増えますが、Legendの設定をしないとどれがどれだかわからないことに。
ARNで絞る
ECSタスク系のメトリクスには
- aws_ecs_cluster_name
- aws_ecs_launchtype
- aws_ecs_service_name
- aws_ecs_task_arn
- aws_ecs_task_family
- aws_ecs_task_id
- aws_ecs_task_known_status
- aws_ecs_task_revision / version
- cloud_account_id
- cloud_availability_zone
が入ってきます。
PrometheusExpoterで取得したメトリクスには、上記ConfigのProcessorで付与したAWS系のLabelでは
- aws_ecs_launchtype
- aws_ecs_task_arn
- aws_ecs_task_family
- aws_ecs_task_revision
- cloud_region
があります。aws_ecs_task_arnを変数化して、Repeat forでその変数を繰り返すことで詳細なPanel群は各タスクごとに確認できるかなと思います。
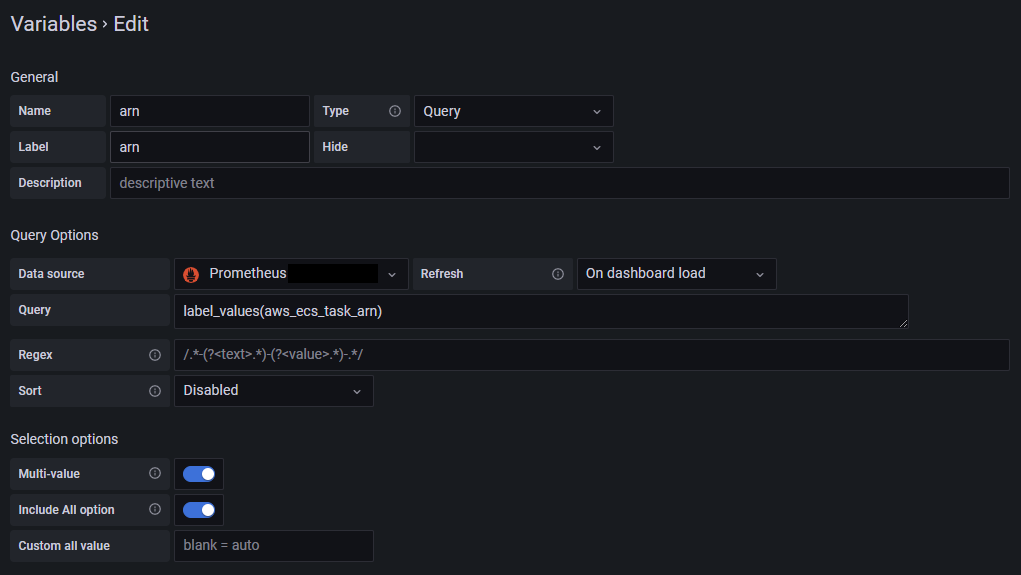
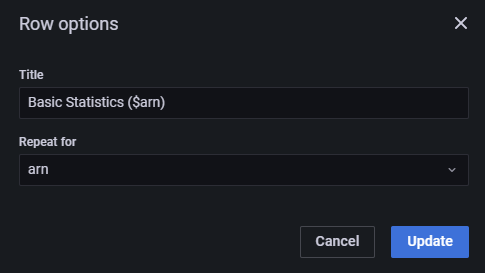
Queryにaws_ecs_task_arn=${arn}の絞り込みの追加が必要です。
HTTPのリクエストとかレスポンスタイムとかは、集計が必要ですが、
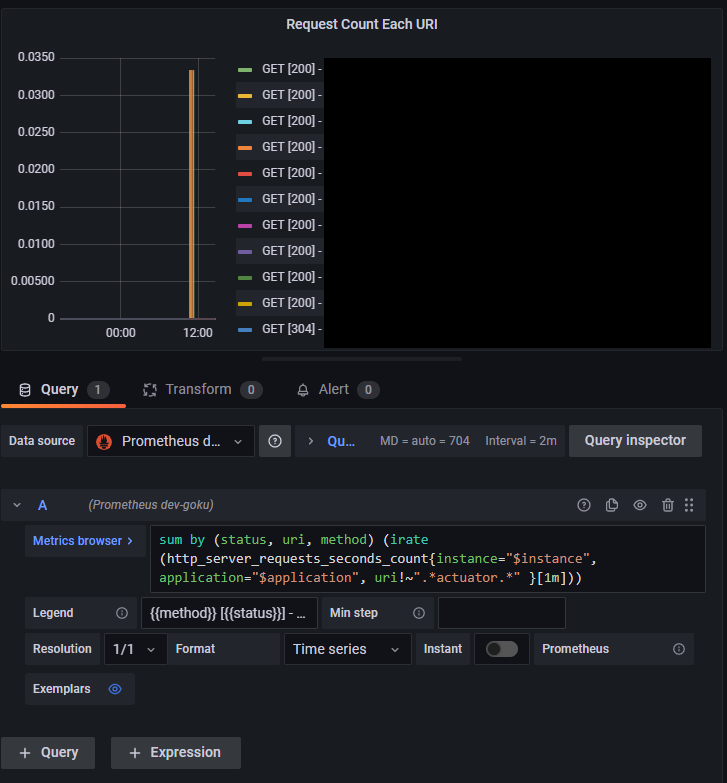
こんな感じにすることで、各Service(Application)ごとのMethod/Status/URIで集計できるかなと思います。
悲しいこと
LocalとAWS上のGrafanaではAlertの実装なのか設定方法が違うので、AlertDashBoardを標準で作成してWorkShop用にExport/LocalGrafanaにImportしたらAlertは消えてしまいました。(使用バージョンは同じ)
さいごに
RemoteWriteという形なのでデータ保存をメインとしたPrometheusサービスですが、Configやデプロイの定義のサンプルも用意されており、思ったより簡単にメトリクスを収集できます。収集用のサイドカーコンテナなどでアプリケーション側に考慮するポイントが増えています。が、比較検討すると自力で準備するよりはハードルは低いと思います。
今後はバッチ向けのPushGatewayあたりができるのを期待しています。SpringBootでもPushGatewayのライブラリがあったので、利用することでサイドカーの導入も不要になってくるのかなと思います。
2023/11/28追記
ADOT(AWS Distro for OpenTelemetry)でログの対応も始まりました。
https://aws.amazon.com/jp/about-aws/whats-new/2023/11/logs-support-aws-distro-opentelemetry/
自動計装で、Log/Metrics/Traceとできると思うので、上記のConfigはもっと簡易かつログ追加とかも進めたいなぁと思ってます。それができたら、別記事で。
参考資料(公式)
いつもの
当社では、トヨタ車のサブスク「KINTO」等の企画/開発を行っており、エンジニアを募集中です。