NeuralTalk2とは?
Deep Learningを応用した画像認識や画像処理については、今や割と身近なものになってきている。ちょっとした処理であれば、ありもののサービスやライブラリを使って出来てしまうので、あとはアイデア次第で、いろいろなものに使えると思う。最近では、GoogleのCloud Vision APIが公開されたことなんかも話題になっている。
ということで、今回取り上げるNeuralTalk2も、そんなDeepを使った画像認識から、写っているものについてのキャプションをつけることができる実装の一つだ。作者はGoogleなどでもインターンとして働いたこともある、スタンフォード大学の博士過程学生のAndrej Karpathyという人だ。この人の名前で検索すると、Deepを使った画像認識系の論文もいくつか出てくる。というのと、ブログが参考になるので、この手の技術を追っかけてみたい人はフォローしておくとよいかもしれない。
- スタンフォード大での公式サイト:http://cs.stanford.edu/people/karpathy/
- ブログ:http://karpathy.github.io/
ちょっと前にイケてるセルフィーとイケてないセルフィーを識別するモデルを作って、ネット上で話題にもなっていた。
NeuralTalk2は最初に作られたNeuralTalkの改良版で、実装がPythonとCaffeによるものから、LuaとTorchに変更されて、処理速度などが上がっている(らしい)。また、認識、キャプションの作成ともRNNによるモデル(正確にはCNN+RNNのはず)で行うようになっていて、キャプションをつけてみるだけなら、学習済みのモデルからすぐに使えるようになっている。
ここでは、理論の説明はいったん置いておいて、NeuralTalk2を利用できるよう、手順にしたがって環境構築し、キャプションを付けられるところまでやってみる。
実行環境を作ってみる
この手の実装の例にもれず、NeuralTalk2もGPUを利用することで、処理が高速化できるようになっているため、AWSのGPUインスタンス上に環境を作ってみる。ここでは、事前にCUDA Toolkitをインストールしてある状態から始める。CUDAのインストール等については公式サイトに譲るとして、その他のインストールを行う。AWSのインスタンスについては、以下の通り。
- OS:Ubuntu14.04
- インスタンスタイプ:g2.2xlarge
- リージョン:バージニア北部
事前にインストールしておいたCUDAのバージョンは7.0となっている。一旦デフォルトで入っているCUDAを全てパージした上で、バージョン7.0を入れ直した。最新は7.5だが、AWSで環境を作る場合、対応ドライバの関係で7.0の方が安定していそうなので、いったん7.0にしている。
また、Pythonを一部利用することがあるが、こちらもインストール済みとしておく。
NeuralTalk2自体のクローン
まずはNeuralTalk2自体を手元に落としてくる必要がある。普通にGithubのリポジトリからクローンしてくるだけだ。
$ git clone https://github.com/karpathy/neuraltalk2.git
Torchと関連するLuaのモジュールのインストール
認識をかけていくところまでに必要なTorchとTorchでの実装に必要なLuaのモジュールをインストールする。
Torchについては、依存するライブラリのインストールなど事前に行えるスクリプトを実行し、その後Githubのリポジトリから最新のソースをクローンしてインストールスクリプトを実行という流れになっている。ホームディレクトリで以下の通り行う。
$ curl -s https://raw.githubusercontent.com/torch/ezinstall/master/install-deps | bash
$ git clone https://github.com/torch/distro.git ~/torch --recursive
$ cd ~/torch;
$ ./install.sh
$ source ~/.bashrc
インストールの最後にTorchのパスが.bashrcに追加されるので、sourceコマンドでパスを有効にしている。Torchがちゃんとインストールできたかは、Torchのインタラクティブセッションを実行してみれば分かる。以下のようにTorchのロゴが表示されればインストールは正常に行われている。
$ th
______ __ | Torch7
/_ __/__ ________/ / | Scientific computing for Lua.
/ / / _ \/ __/ __/ _ \ | Type ? for help
/_/ \___/_/ \__/_//_/ | https://github.com/torch
| http://torch.ch
th>
Torchがインストールできたら、Torchでの処理用にニューラル系と画像処理系のLuaのライブラリをインストールする。LuaのライブラリはLuaのパッケージマネージャであるLuaRocksで行うことができる。インストールするのは以下の3つで、luarocksコマンドのインストールオプションで行う。LuaとLuaRocksは上記の依存関係を含めたTorchのインストール手順の中で使える状態になっている。
$ luarocks install nn
$ luarocks install nngraph
$ luarocks install image
次に内部でJSONをLuaで扱うためのcjsonのライブラリもインストールしておく。こちらはソースコードからビルドしてインストールする。
$ wget http://www.kyne.com.au/~mark/software/download/lua-cjson-2.1.0.tar.gz
$ tar xzvf lua-cjson-2.1.0.tar.gz
$ cd lua-cjson-2.1.0/
$ luarocks make
最後にGPUを利用するので、CUDA関連のライブラリをインストールする。利用するライブラリは以下の二つ。
$ luarocks install cutorch
$ luarocks install cunn
CUDA関連も基本はこれでOKなのだが、NVIDIAのDNN用ライブラリであるcuDNNを使う場合は、cuDNNのバージョン3.0以上とcudnn.torchを入れる必要がある。後ほど使う学習済みのモデルが利用しているので、ここでは入れておくことにする。まずはNVIDIAのサイトからcuDNNをダウンロードしてきて、任意の場所に置き、共用ライブラリパスに追加しておく。その後、cudnn.torchのリポジトリをクローンしてきて、ビルドしておく。cuDNNはv4.0のrcが最新だが、試してみたところv4.0だとエラーが出るため、v3.0をダウンロードしておく必要がある。
$ export LD_LIBRARY_PATH=/home/ubuntu/libs/cuda/lib64:$LD_LIBRARY_PATH
$ git clone https://github.com/soumith/cudnn.torch.git
$ cd cudnn.torch
$ luarocks make cudnn-scm-1.rockspec
ここまでの環境構築で、学習済みのモデルを利用して画像を評価し、キャプションをつけるまではできるようになるはず。
学習を行う場合のライブラリの追加
これまでの環境構築でとりあえずキャプションをつけるところまではできるはずだが、一応自分でファインチューニングしたり、新たにモデルを学習するために必要なライブラリもインストールしておく。
一つはCaffeで学習したモデルをTorchで利用するのに必要なloadcaffeをインストールする。loadcaffe自体はluarocksでインストールできるが、loadcaffeを利用するにはProtocol Buffersのライブラリが必要になるので、こちらは別にインストールしておく。Caffeを同一の環境にすでにインストール済みの場合はすでに入っているはずだが、そうでない場合はloadcaffeのインストールとともに以下の通り。
$ sudo apt-get install libprotobuf-dev protobuf-compiler
$ luarocks install loadcaffe
あとは内部で前処理のデータ保持に利用されているHDF5形式のファイルを扱うためのライブラリを入れる。ちなみにHDF5は大規模な科学計算などでも用いられる構造化データの形式の一つだ。入れる必要があるのはTorch用のライブラリであるtorch-hdf5とPythonでHDF5形式のファイルを扱うためのライブラリであるh5pyだ。またそれらのビルドや内部で参照されているライブラリも最初にインストールしておく。
$ sudo apt-get install libhdf5-serial-dev hdf5-tools
$ git clone git@github.com:deepmind/torch-hdf5.git
$ cd torch-hdf5/
$ luarocks make hdf5-0-0.rockspec LIBHDF5_LIBDIR="/usr/lib/x86_64-linux-gnu/"
$ pip install h5py
これで一応の環境構築はできているはず。ということで、実際に使ってみる。
キャプショニングの実行
それでは、実際にキャプション付を実行してみる。ここでは学習済みのモデルを使って実行する。提供されている学習済みのモデルは、マイクロソフトが公開しているデータセットであるCOCOを学習させたものだ。任意のディレクトリにダウンロードして解凍しておく。
$ wget http://cs.stanford.edu/people/karpathy/neuraltalk2/checkpoint_v1.zip
$ unzip checkpoint_v1.zip
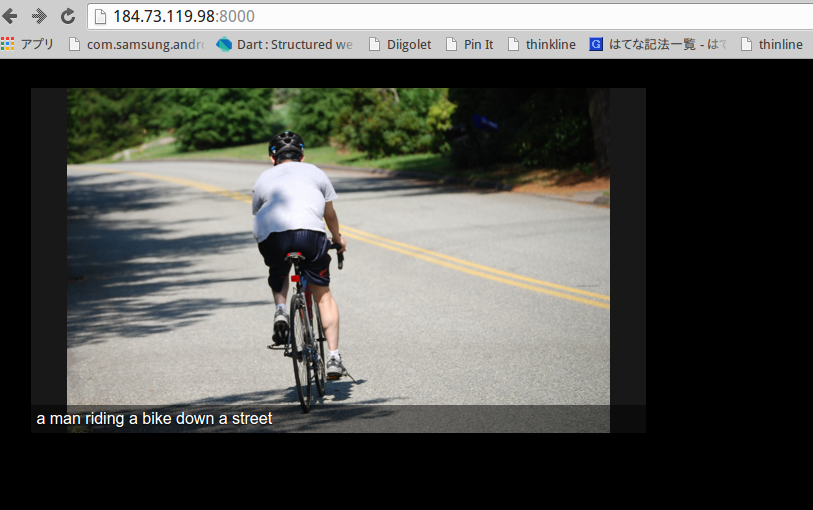
あとはキャプションを付けたい画像も任意のディレクトリに保存しておき、先ほどクローンしてきたNeuralTalk2の中に含まれているeval.luaを実行する。試しにロイヤリティフリーの画像素材から以下の画像を持ってきて実行してみた。

写真素材 足成よりダウンロード http://www.ashinari.com/
男性が自転車に乗っているというようなキャプションが付けばOKのはずである。
$ th eval.lua -model ~/data/model/model_id1-501-1448236541.t7 -image_folder ~/data/images -num_images -1
DataLoaderRaw found 1 images
constructing clones inside the LanguageModel
cp "/home/ubuntu/data/images/a1180_015158_m.jpg" vis/imgs/img1.jpg
image 1: a man riding a bike down a street
evaluating performance... 0/-1 (0.000000)
loss: nan
実行はクローンしてきたNeuralTalk2のディレクトリに移動して行っている。num_imagesというオプションは処理するイメージ数を指定しているが、-1で実行すると、指定のディレクトリ下の全ての画像を処理する。この他バッチサイズもbatch_sizeオプションで指定できるが、ここではデフォルトのままで実行している。画像数が多く、処理速度を上げたい場合は指定するとよい。
キャプションの結果はimage 1:の部分に表示されている。「a man riding a bike down a street」となっており、この画像については、正しいキャプションが付けられた。NeuralTalkのキャプションは単なる単語でつくのではなく、このように短文で説明がつくような形になる。
キャプションはJSON形式でvisというディレクトリの中にも保存されており、こちらは簡易のWebインターフェイスで見ることもできる。こちらを見るにはvisディレクトリに移動して、PythonのsimpleHttpServerを実行すればよい。デフォルトだとポート8000番で起動するので、プラウザからアクセスして表示してみる。
$ cd vis
$ python -m SimpleHTTPServer
この後どうする?
NeuralTalk2を動かしてみるところまで、ざっくりやってみた。提供されている学習済みのモデルを使うだけでも、かなりよい感じにキャプションを付けてくれそうで、いろいろ応用を考えてみようと思っているところ。
Karpathyさんご本人のデモだったと思うが、動画のストリームで映っている範囲のキャプション付けをしているのを見たような記憶があるので、そちらもちょっとやってみようと考えている。
ということで、興味のある方はちょっと触ってみてはいかがだろうか?