背景
Transformerは近年の様々なAIモデルに使用されており、その理屈を理解したく勉強中です。
その中でもPositional Encodingでは具体的に何をやっているのかイメージ出来なかったので、少しでも内容理解に繋げるために記事を書きました。
Positional Encodingとは
端的に言うと、Self-Attentionではトークンの位置情報がないので、ベクトルを足して位置情報を表現しようというものです。
TransFormerではEncoderとDecoderどちらにも使われています。
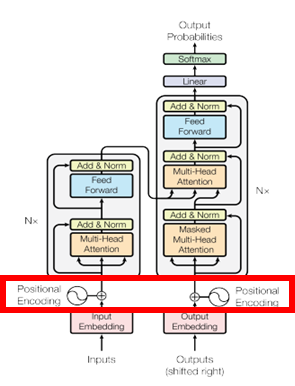
計算式は以下の通りです。
PE\left( pos,2i\right) =\sin \left( \dfrac{pos}{10000^{2i/d_{model}}}\right)
PE\left( pos,2i+1\right) =\cos \left( \dfrac{pos}{10000^{2i/d_{model}}}\right)
ここではトークンの位置をpos、トークン埋め込み後のベクトルにおける各次元のインデックス値をi、トークン埋め込み後のベクトル次元数を$d_{model}$としています。
一体何をしているの??
Positional Encodingの計算式や目的はわかりました。
しかし、いろんな人の記事を見てもPositional Encodingの説明はここまでであり、実際に三角関数が何をやっているのか、なぜこの式を使えば位置を表現できるのかまで説明されてません。
実装上は問題ないと思いますが、もう少し踏み込んだ理解を目指します。
そもそもなぜSelf-Attentionでは位置情報がないのでしょうか。
本題と逸れるので詳しい説明は省きますが、Transformerでは並列計算できる代わりに位置情報を犠牲にしているのです。
RNNモデルであれば位置情報は使えますが、処理に時間がかかるといった特徴がありますね。
つまり元の埋め込みベクトルに位置情報を付加しないと、トークンの位置関係が失われてしまいます。(例えば 私は綺麗 と 綺麗私は から同じ特徴表現が得られてしまう。)
そこでPositional Encodingが登場します。役割としては識別子のようなものです。例としてQueen and kingの3文字を入力する場合を考えてみましょう。
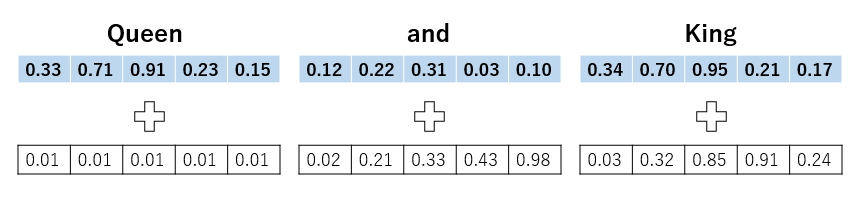
青がトークン埋め込みベクトル、白が位置ベクトルです。2つを足し合わせてAttentionに入力します。
ここで位置ベクトルを足すとはどういうことか視覚的に理解します。
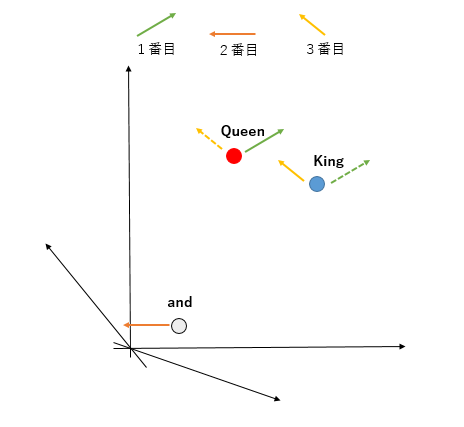
まず特徴表現ベクトルを無理矢理二次元で表します。本当は多次元なので平面で表せませんが。
QueenとKingは、単語の頻度分布の関係から近い距離にあります。
ここから位置ベクトルを足しますが、入力の順序によって足す値が変わります。
Queen and Kingと入力すれば実線、King and Queenと入力すれば点線のベクトルが足されます。
このように特徴表現ベクトルに位置情報を付加することを目的とします。
ここから本題に入ります。
Positional Encodingの満たすべき条件が2つあります。
- 文章の長さや入力の正確さに関係なく、それぞれの位置が同じ位置ベクトルを持つ必要がある
- 位置ベクトルを大きくしすぎてはいけない
1から見ていきます。例えば入力がPrinceのみの場合でも位置ベクトルは常に固定されます。
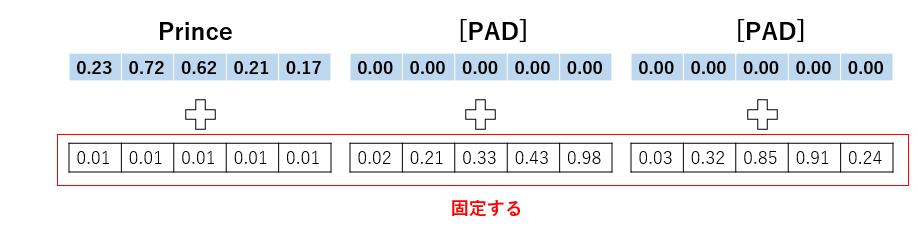
2は特徴表現ベクトルの値を変えすぎたらいけないよと言うことです。大きすぎる値を足すと、元の意味から外れてしまうためだと考えてます。
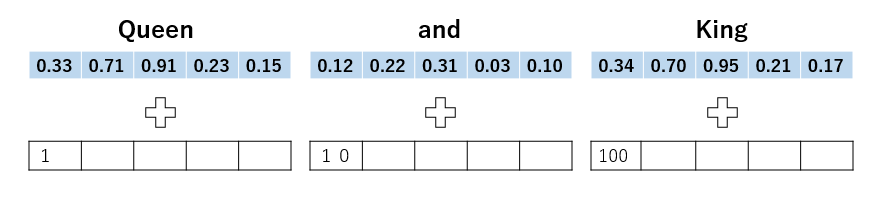
数式理解
ここまで概要の理解に努めてきました。しかしなぜsinやcos関数を使うのか、10000という値はどこから来てるのか分かりません。したがって具体的にどのようにPositional Encodingを決めるのか見てみます。
ここで最も簡単に位置情報を与える手法を考えてみます。
まず思いつくのは、入力された順番と同じ値を付加する手法です。
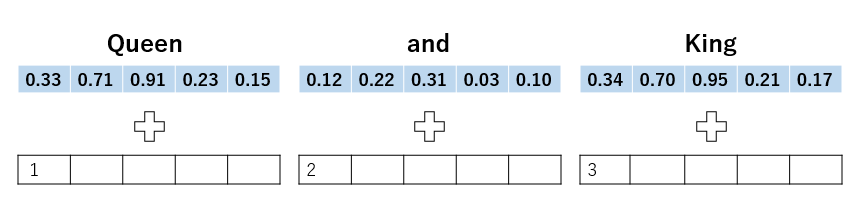
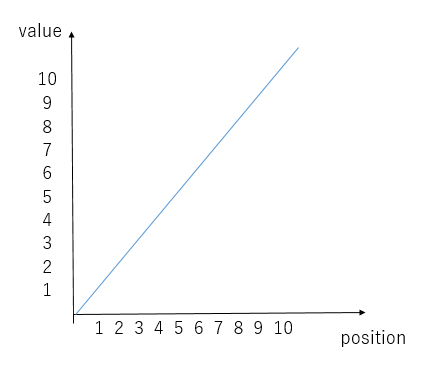
しかしこれでは値が大きくなりすぎるため、条件2に反します。したがって、valueの値を制限し、かつpositionは制限なく使える関数が必要です。
ここでsinやcosが登場します。
sinやcosを使うことでvalueを-1から1の間に制限できます。
他にもsigmoid関数が考えられますが、positionが大きくなるにつれてvalueが変わらないというデメリットがあります。
その点sinやcosはpositionが大きくなってもvalueを変化させれます。
なるほどだからsinやcosを使うのですね。
しかしまだ問題があります。周期関数なので、positionが変化しても同じvalueの値が返されます。そこで最大の文章量が来てもvalueが繰り返されないほど低い周波数をsinに与えればどうでしょうか?
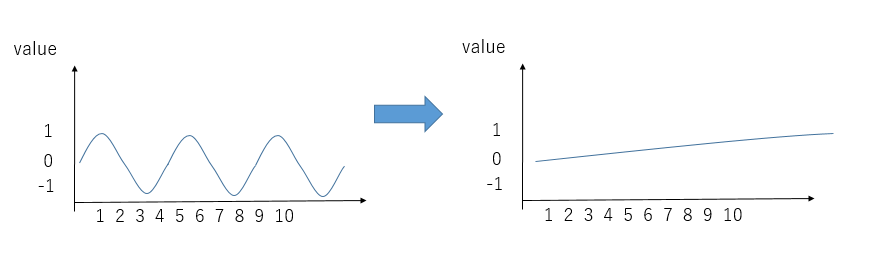
これで長い文章が来ても位置情報を個別に割り振れました。
だから数式中に10000という大きな数字が表れているのですね。ちなみに10000はハイパーパラメータなので、自由に変更できます。
このままでもよさそうですが、更なる工夫が必要です。
なぜなら低周波数にしたため、positionが小さいとき(例えば1, 2の場合)値がほとんど変化しません。
したがって表現を増やすためcosを使います。
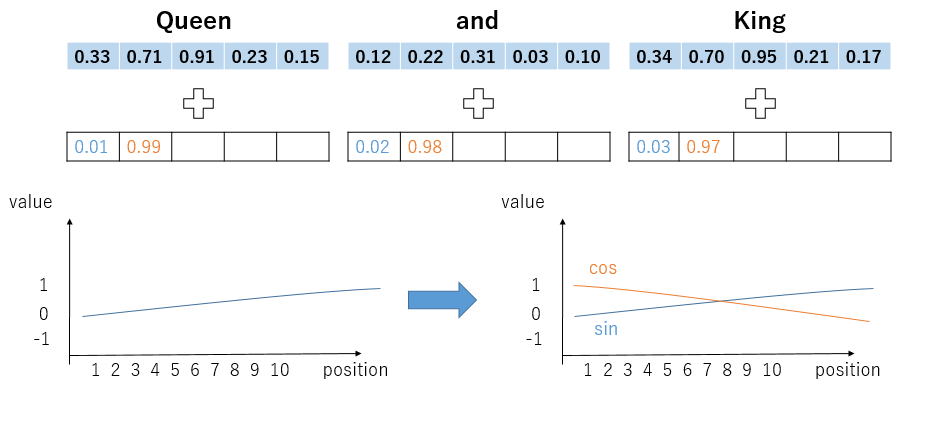
イメージは上の図の感じです。
これでsinとcosを両方使う意味が分かりました。
Positional Encoding vs Positional Embedding
ここまでPositional Encodingを見てきましたが、調べていくうちにPositional Embeddingという言葉も目にしました。この2つの違いはあるのでしょうか。正直違いを認識しているわけではないですが、
学習を行わないのがPositional Encoding
学習を行うのがPositional Embedding
と分けられるそうです。
More
正直納得いってない部分があり、まだまだ理解しきれてないです。
Positional Encodingには様々な派生形があり、データによって使い分ける必要があります。
例えば音声、画像、映像にはrelative positional encodingが有用であると示唆されてます。
また、フーリエ変換を使って位置情報を与える手法もあるそうです。
必要があれば、この辺も勉強したいと思います。
記事を書き始めたばかりなので、文章力も課題です。また、図形作成能力も必要だと感じました。これから少しずつ上達していきます。
参考