本記事は株式会社ベリサーブに所属するメンバーによる ベリサーブ Advent Calendar 2023 の10日目の記事です。
Property-Based Testing について、簡単に調べてまとめてみました(JaSST九州では2009年の時点で発表があります)。また、Python 上でこのアプローチをサポートする Hypothiesis というフレームワークも試してみました。また、調べる過程で、アプローチが似ているようにみえる、Metamorphic Testing と Fuzzing との違いについても考察しています。
まず、概念の整理から。
Example-Based Testing
一般的な、何らかの基準で入出力の組を予め設定し、テストするもの
入出力の組を導くにはテスト設計技法が利用可能です。
テスト技法によってある程度カバーされますが、設計者の思い込みが入りがち(特に開発者自身がテストする場合)という欠点があります。
Property-Based Testing
あらゆる入力と対応する出力について成り立つ特性(property)を設定し、その特性を満たすようなテストケースを自動生成してテストするもの。QA4AIの主要な技術である、メタモルフィックテスティングの概念とも似ています。
MTにおけるメタモルフィック関係の発見と同様にテスト対象の関数で成り立つ「属性」の発見が肝になりそうです。
特性の例
- 文字列のチェックを行う関数において、文字列を逆さにして再度逆さにすると、処理前と同じ文字列が得られる。同様に、文字列を逆さにしても、文字列長は同じである。
- (動画の例)RunLength法のエンコーダ・デコーダにおいて、文字列をエンコードしてデコードすると、処理前の文字列が得られる。
- などなど
Hypothesis(はいぽじしす)
Pythonで利用できるプロパティベーステストのフレームワークです。テストランナーはpytestなど既存のフレームワークを利用します
生成するデータの「型」が、hypothesis.strategies. 以下に定義されています。わかりやすいものとして、emails, integers, ip_addresses,text, timesなど。詳細は下記を参照。
What you can generate and how — Hypothesis 6.91.0 documentation https://hypothesis.readthedocs.io/en/latest/data.html
それぞれのデータ型において、エッジケース(問題を起こしやすいデータ)が意図的に組み込まれています。また、One of と | で結合することで、複数のテストデータ型を組み合わせることも可能です。
Run-length encoding (RLE)の例
「Run-length encoding (RLE) に対して、ある文字列をエンコードし、それをデコードしたものは、最初に与えられた文字列と同じになる」という特性をテストします。Hypothesis のGetting Startedに載っている例に少し手を加えています。Hypothesis が生成しているデータを列挙するようにしています。
from hypothesis import given
from hypothesis.strategies import text
def encode(input_string):
if not input_string:
return []
count = 1
prev = ""
lst = []
for character in input_string:
if character != prev:
if prev:
entry = (prev, count)
lst.append(entry)
count = 1
prev = character
else:
count += 1
entry = (character, count)
lst.append(entry)
return lst
def decode(lst):
q = ""
for character, count in lst:
q += character * count
return q
@given(text())
def test_decode_inverts_encode(s):
print(f"Testing with input: {s}")
assert decode(encode(s)) == s
python -m pytest <filename> -s として実行します。
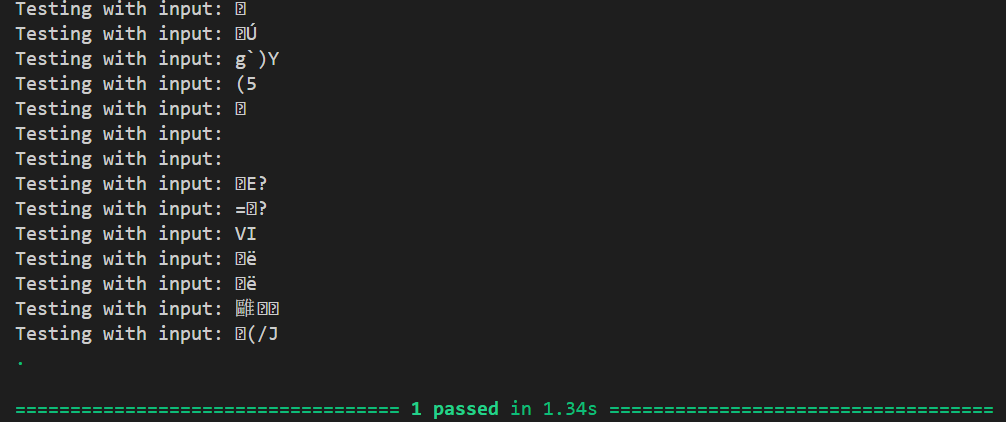
上記のようなデータが Hypothesis によって生成され、データ駆動のような形でテストが実行されます。
Property-Based Testing と Metamorphic Testing の違い
Property-Based Testing は、「関数の入出力が持つ特性」に着目するのに対し、Metamorphic Testing はAIモデルによって判定される「データの変化の関連性」(正当に関連していることが期待される)に着目します。どちらも、テストオラクルをほぼ自動生成する点は共通していますが、注目する主体が異なります。
Property-Based Testing と Fuzzing の違い
データを自動生成して、共通のインターフェースに対してひたすら投入し続ける種類のテスト手法として、Fuzzing があります。現在は、未知の脆弱性の検出技法としての地位を確立しています。Fuzzing も(1)単にランダムなデータを投入するもの、(2)正常系のデータから1~数ビット反転することで異常なデータを生成するもの、(3)データの型から想定されうるデータを網羅的に生成するもの、など多くのアプローチがあり、Property-Based Testingは、Fuzzingにおける(3)のアプローチと非常に似ています。
Fuzzing も、Metamorphic Testingと同様に、あくまで「データ」に着目するため、Property-Based Testing が着目する側面とは少しだけ異なります。ただ、ある種のファジングはかなり似たアプローチになることがある、とは言えるでしょう。
参考情報
- プロパティベースのテストデータの 自動生成とその応用 https://jasst.jp/archives/jasst09k/pdf/p5.pdf
- 「Python のユニットテスト用ライブラリ Hypothesis の紹介」「あなたの街でもPython広めませんか?」 2022-1-29 B-4 - https://www.youtube.com/watch?v=cIe-U4upUsI&t=1938s
- Hypothesis 6.91.0 documentation - https://hypothesis.readthedocs.io/en/latest/