昨今話題になってるディープラーニングですが、
「勉強してみたいけど、そもそも何ができるのかよくわかってない...」
そんな方に向けて、Macにおける環境構築からディープラーニング実行までの方法をご紹介します。
python環境構築
機械学習・ディープラーニングといえばpythonです。
とりあえずpythonの環境構築を整えます。まずはpythonをインストールしましょう。
ターミナルを開いて、順に実行していきましょう。
brew install pyenv
pyenv install anaconda3-4.0.0
これでインストール完了。
pyenv versions
と実行して、
* system (set by ~~~)
anaconda3-4.0.0
こんな感じにanaconda3-4.0.0が出てくれば無事インストール成功です。
次はpyenvのパスを通します。
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile
echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile
echo 'eval "$(pyenv init -)"' >> ~/.bash_profile
source ~/.bash_profile
これでOK!
次に、先ほど入れたpythonのバージョンに切り替えましょう。
pyenv grobal anaconda3-4.0.0
これで無事切り替えられているはずです。
python
とターミナルに入力して実行することで、
Python 3.5.2 |Continuum Analytics, Inc.| (default, Jul 2 2016, 17:52:12)
Python 3.x.xなどと表示されていれば、切り替えに成功です。
keras導入と設定
次にディープラーニングのフレームワークで有名なkerasをインストールしましょう。ディープラーニングを1から作ろうとすると、膨大な労力がかかりますが、kerasを用いることで、10行で実行できてしまいます。
ついでにkerasの学習結果を保存するための、h5形式を扱うライブラリも入れておきます。
pip install h5py
pip install keras
インストール完了。そのあと、若干の設定をしておきます。
mkdir ~/.keras
echo '{"epsilon": 1e-07, "floatx": "float32", "backend": "theano"}' >> ~/.keras/keras.json
【Tips】backendとは?
読み飛ばして全然OKです。
ところで、ディープラーニングのアルゴリズムの根底には、数学的計算などを行う必要があります。実はこの数学的計算を行ってるライブラリがbackendと呼ばれ、kerasとは別のライブラリが担っています。theanoかtensorflowのどちらかを選ぶことができて、kerasをインストールすると同時にtheanoもインストールされます。
ディープラーニング実行
お待たせいたしました。早速ディープラーニングをしていきましょう。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import keras
from keras.utils import np_utils
from keras.datasets import mnist
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.layers.core import Activation, Dense, Dropout, Flatten
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32')/255
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32')/255
y_train = np_utils.to_categorical(y_train, 10)
y_test = np_utils.to_categorical(y_test, 10)
model = keras.models.Sequential()
model.add(Convolution2D(nb_filter=20, nb_row=5, nb_col=5,
border_mode='valid',
input_shape=(28, 28, 1)))
model.add(Activation("relu"))
model.add(Convolution2D(nb_filter=15, nb_row=5, nb_col=5))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation("softmax"))
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=100, nb_epoch=3, verbose=1)
score = model.evaluate(x_test, y_test, show_accuracy=True, verbose=0)
print("test-accuracy: {}".format(score[1]))
model_json_str = model.to_json()
open('model.json', 'w').write(model_json_str)
model.save_weights('weights.h5')
次のような表示が出れば、無事ディープラーニングが始めることができています。
Using Theano backend.
Epoch 1/3
5100/60000 [=>............................] - ETA: 111s - loss: 1.2484 - acc: 0.5733
ディープラーニングの結果を確認する
さて、学習は完了しましたでしょうか。完了すると、以下のように表示されます。
test-accuracy: 0.989
これは、訓練とは全く別のデータ(テストデータ)に対して、98.9%の確率で数字を識別できているということを表してます。
これでは、どんな文字がどう判定されてるかよくわからないので、次のスクリプトを実行しましょう。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import pylab
import keras
from keras.utils import np_utils
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32')/255
model = keras.models.model_from_json(open('model.json').read())
model.load_weights('weights.h5')
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=['accuracy'])
tests = x_test[:20]
labels = model.predict(tests, verbose=1)
for index, (image, label) in enumerate(zip(tests, labels)):
pylab.subplot(4, 5, index + 1)
pylab.axis('off')
pylab.imshow(image.reshape(28, 28), cmap=pylab.cm.gray_r, interpolation='nearest')
pylab.title(np.argmax(label))
pylab.show()
ここで、先ほどの学習結果が、model.jsonとweights.h5で保存されてるので、それを再読み込みしています。
以下のように結果が出てるかと思います。各数字に対してどの数字か判定したかを表しています。
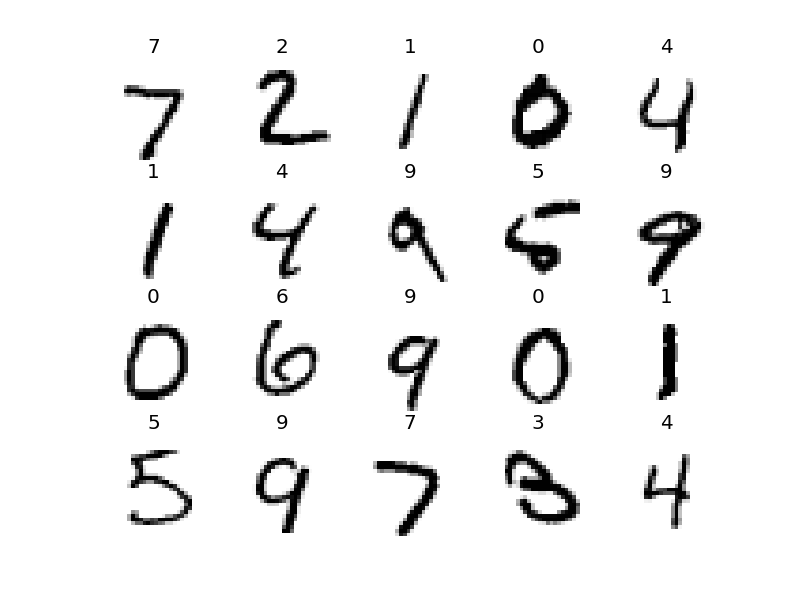
入門書
いかがでしたでしょうか。
今回とにかく実行したいという方向けにスクリプトをとにかく載せさせていただきました。
これで興味を持たれてディープラーニングの勉強を始めようと思う方が一人でも増えていただけるととても嬉しいです。
最後に入門書の紹介です。
・ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装
pythonでの実装を添えて理論を理解していく形式の入門書です。実際にプログラミングしながら理解したい方には是非オススメです。
実装はなく、理論が主な内容ですが、理論が書いてある本の中でもかなりわかりやすく解説してくれています。基礎の内容から話題の手法まで幅広くカバーしているのが特徴です。