この論文を読んだ理由
- DEIM2024のチュートリアル(大規模言語モデルに基づく検索モデル)で紹介されていたため
読んだところ
- 全体
解いている課題
- 大規模言語モデルを用いた情報検索を高速に行う.
BERTによる検索は高精度だが遅い
提案手法のアプローチ
アーキテクチャ
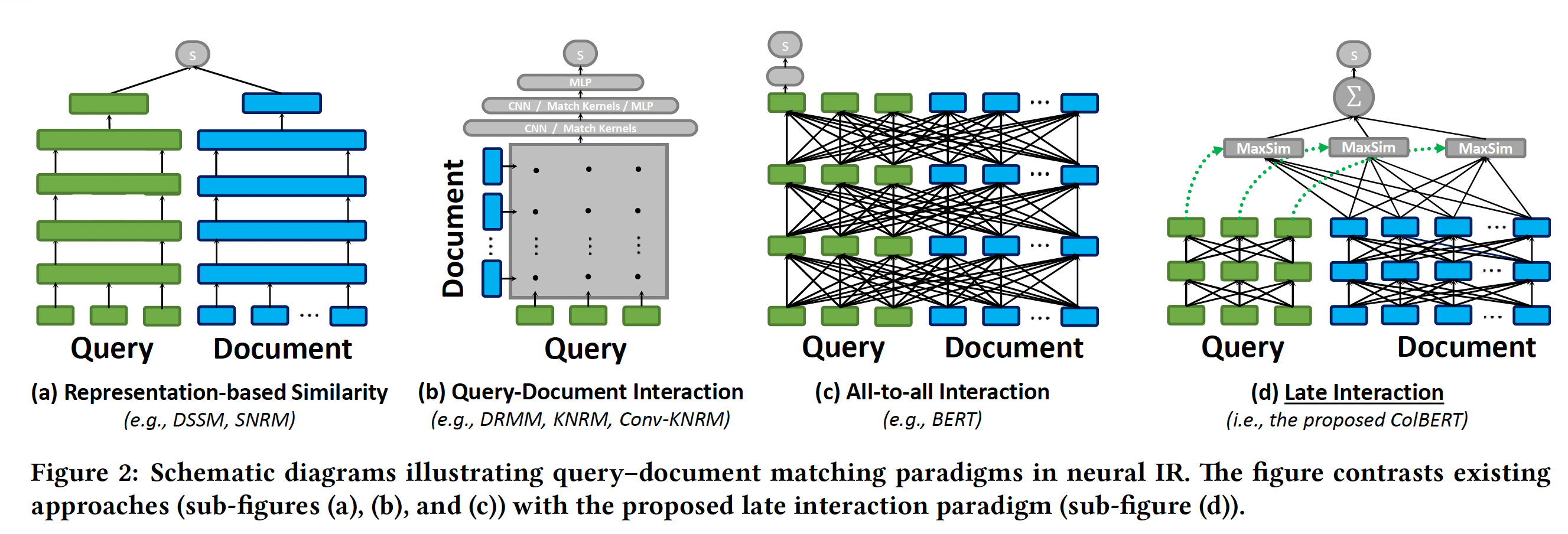
-
Representation-based Similarity...ドキュメントのembeddingを用いて類似度を計算
-
Query-Document Interaction...クエリとドキュメントにおいて,トークンごとに関連度を計算する,その後CNNやMLPを適用する
-
All-to-all Interaction...クエリとドキュメントをくっつけて,BERTに入力し類似度を得る.この方法では,クエリとドキュメントの全てのペアに対して処理を行う必要があり計算コストが非常に高い.
-
Late Interaction(ColBERTで用いる手法)...別々にBERTに入力し,トークン単位で類似度を計算する(これによって,BERTとは異なり事前にドキュメントのembeddingを計算しておける).その後,最も類似度が高いトークンとのスコアを使用する(MaxSimと名付けている)ことで,より高精度に検索ができる.
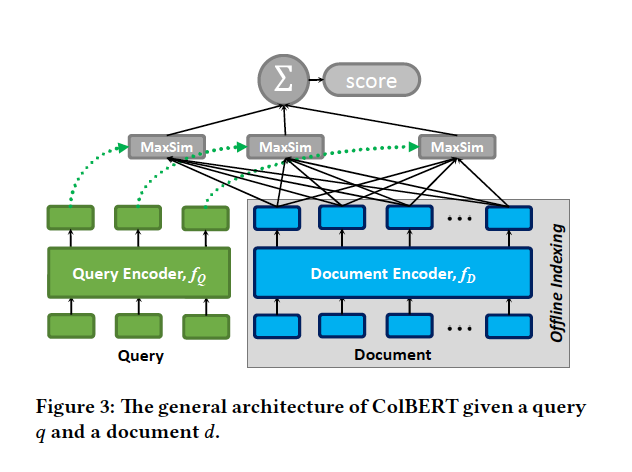
テクニック
-
クエリ拡張(query augmentation)
クエリに[mask]を付けることで,新たな用語でクエリが拡張されることを期待している.
例:"I drink a cup of coffee . [mask] [mask]"を入力して,[mask]のところにエスプレッソやカフェオレなどの単語を予測して,良い感じのembeddingを出力してくれる.→情報検索に有効 -
記憶領域の削減
- embeddingを複数のベクトルに分割してエンコード
- float32→float16
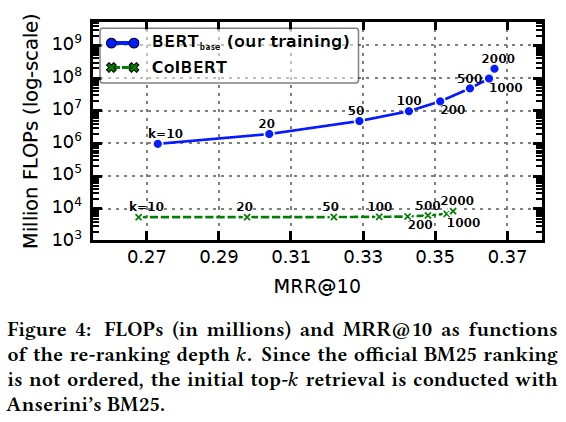
実験結果
- 精度はBERT並みで.計算量は,1000件の文書について検索する場合で13900分の1(大幅な効率化)
実装
公式実装:ColBERT