アミフィアブル株式会社AIチームのエンジニアの野村です。
はじめに
私が所属するPython/AIチームでは、PythonによるREST APIの開発を行っています。その開発には、静的型チェックツールのmypyとlintツールruffの使用が前提となっており、Pythonコードに厳密な型付けが義務付けられています。(以降のPythonコードは型付けが前提となります)。
厳密に型付けを行うことで本来であれば型無しの動的オブジェクト指向言語という関数型言語とは対照的なPythonであっても関数型のライブラリを導入しやすくなります。そこで、私のチームではPythonの関数型プログラミングライブラリreturns(公式サイト)が提供するResultモナドを導入しています。
returnsのResultは関数型言語のResultモナドないしはEitherモナドを模倣して実装されていますが、returnsのドキュメントでは、モナドという単語は使用せずコンテナ(container)という言い回しを使っています。また、関数型ドメイン設計や鉄道指向プログラミング解説でもモナドという用語は避けられてResult型と呼ばれることが多いようです。実際のところ関数に副作用を含みうるPythonでは定義上モナドとは言えません。この点に関してはPart3の記事で解説したいと思います。ただ、この記事ではモナドを恐れず「モナド」という用語で統一します。
Pythonでモナドといったガチガチの関数型スタイルを導入するメリットはなんでしょうか。結論を先に言いますと、Resultモナド導入は次の2つが大きな動機になります:
- オニオンアーキテクチャのレイヤー構造との親和性
- エラーハンドリングの厳密化と明晰化
これらの主題の前に下ごしらえとしてモナドを簡単に説明します(Part1)。また、チーム開発でのResult導入においてdo記法の役割が大きい点にも触れます(Part2)。そして、モナドを扱う上で必要不可欠となりまたオニオンアーキテクチャでのレイヤー区別に関係してくる純粋関数/不純な関数の区別を説明します(Part3)。その後、Resultを導入したオニオンアーキテクチャ(Part4)とエラーハンドリング(Part5)を解説します。
- Part1 Resultモナド
- Part2 do記法
- Part3 純粋関数
- Part4 オニオンアーキテクチャ
- Part5 アスレチックゲー厶で例えるエラー処理(←いまここ)
なお、対象読者としては、関数型プログラミング、および、関数型ドメインモデリングに関心があるPythonエンジニアを想定しています。
Resultの導入(エラーハンドリング)
Resultモナド導入は次の2つが大きな動機になります:
- エラーハンドリングの厳密化と明晰化
- オニオンアーキテクチャのレイヤー構造との親和性
これまで、Resultの概説とオニオンアーキについて書いてきましたが、この記事ではまず親しみのあるマリオやロックマンのようなジャンプアクションゲームの例を用いてエラーハンドリングにおけるResultモナドのメリットを解説していきます。
鉄道指向プログラミング
Resultモナドを導入する上でおそらく最も語られるのはエラーハンドリングです。これは最近では鉄道指向プログラミング(Railway Oriented Programming)といった呼ばれ方もします。これは命名者によるとモナドという抽象的な概念それ自体を紹介したいわけではなくこれを使ったエラーの扱いという具体例を紹介したいのでモナドという呼称をあえて避けるため導入したということです。1
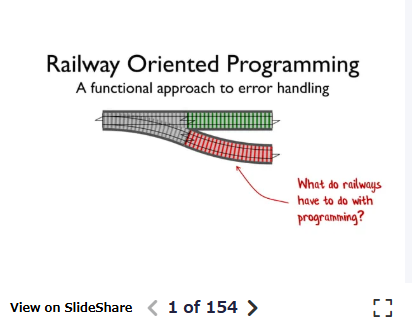
(上記リンク先のスライドより)
鉄道指向とは、「成功レール」と「失敗レール」の2本の線路をイメージして、一度失敗レールに乗ると最後まで失敗側で終わる、という例えから来ています。
ジャンプアクション指向プログラミング
鉄道指向プログラミングは多くの解説がありますので、ここではあえて別の例えとして下絵のようなマリオライクなヒツジちゃんの横スクロールアスレチックゲームを例にして解説していきます。

上の画像を見ればわかるように、飛びタルを何度か成功すれば上のゴールに操作キャラが難所をクリアします。また、タルは一度乗ったら落ちるので戻れないとします。また、ヒツジちゃんはこのステージで一箇所でもタルから足を踏み外して奈落に落ちたらステージ攻略は失敗となります。
話をガラリと変えて次にある予算が書かれたcsvファイルから数字を読み取って特定の計算をするシンプルな業務ロジックを見てみましょう。
1. プロジェクトの予算が書かれたcsvファイルを読み込む
2. csvの数字になんらかの計算を行う(例えば、一番左の数字を指定数字で割る)
3. csvファイルに書き込む
このロジックにおいても、それぞれで失敗ポイントがありますよね。例えば、1であれば指定したファイルが存在しない場合、2であれば0で割り算をした場合、3であれば指定ファイルが開けない場合、などです。
奈落落ちの失敗(raise Exception)
ヒツジちゃんのジャンプステージとプログラミングの関数には共通点があります2。つまり、それぞれに失敗と成功があるという点です。そして、奈落落ち失敗は画面暗転でステージ攻略がストップしてステージを戻されるということですが、これはプログラミングで言えばエラーに遭遇して処理がそこで止まる挙動に似ています。
上述の処理のそれぞれをpythonの関数にしてみます。またここでは単純化のためにエラーケースはそれぞれ一つだけ設定してあります。
import csv
def read_csv(file_path: str) -> list[list[str]]:
"""CSVファイルをリストとして読み込む"""
try:
with open(file_path, encoding="utf-8") as f:
return list(csv.reader(f))
except FileNotFoundError:
raise FileNotFoundError(f"'{file_path}' が見つかりませんでした。")
def process_data(data: list[list[str]], divisor: int) -> list[list[str]]:
"""左上の値を指定の数値で割る"""
try:
for row in data:
division = float(row[0]) / divisor
row[0] = str(division)
except ZeroDivisionError as e:
raise ZeroDivisionError("ゼロ除算禁止!") from e
return data
def write_csv(data: list[list[str]], file_path: str) -> None:
"""データをCSVに保存する"""
try:
with open(file_path, "w", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(data)
print(f"'{file_path}' に保存されました。")
except PermissionError:
raise PermissionError(f"'{file_path}'にアクセスできません。")
それぞれの処理をつなげたのが次になります。
if __name__ == "__main__":
file_path = "budget.csv"
divisor = 2
data = read_csv(file_path)
data_rev = process_data(data, divisor)
write_csv(data_rev, file_path)
ヒツジちゃんのジャンプアクションで例えるならば、この3つの関数でいずれのエラーにも遭遇しなかったらヒツジちゃんは難所をクリアできます。しかし、奈落に落ちたらヒツジちゃんはどこまで戻るでしょうか。ステージの最初ですか?中間地点ですか?ゲーム開始画面ですか?落ちた瞬間にはもしかしたらわからないですよね。「あー中間取ってなかった!」とか「あ!0機だった~」など思いがけないところに戻された、なんて経験は誰にでもあるでしょう。
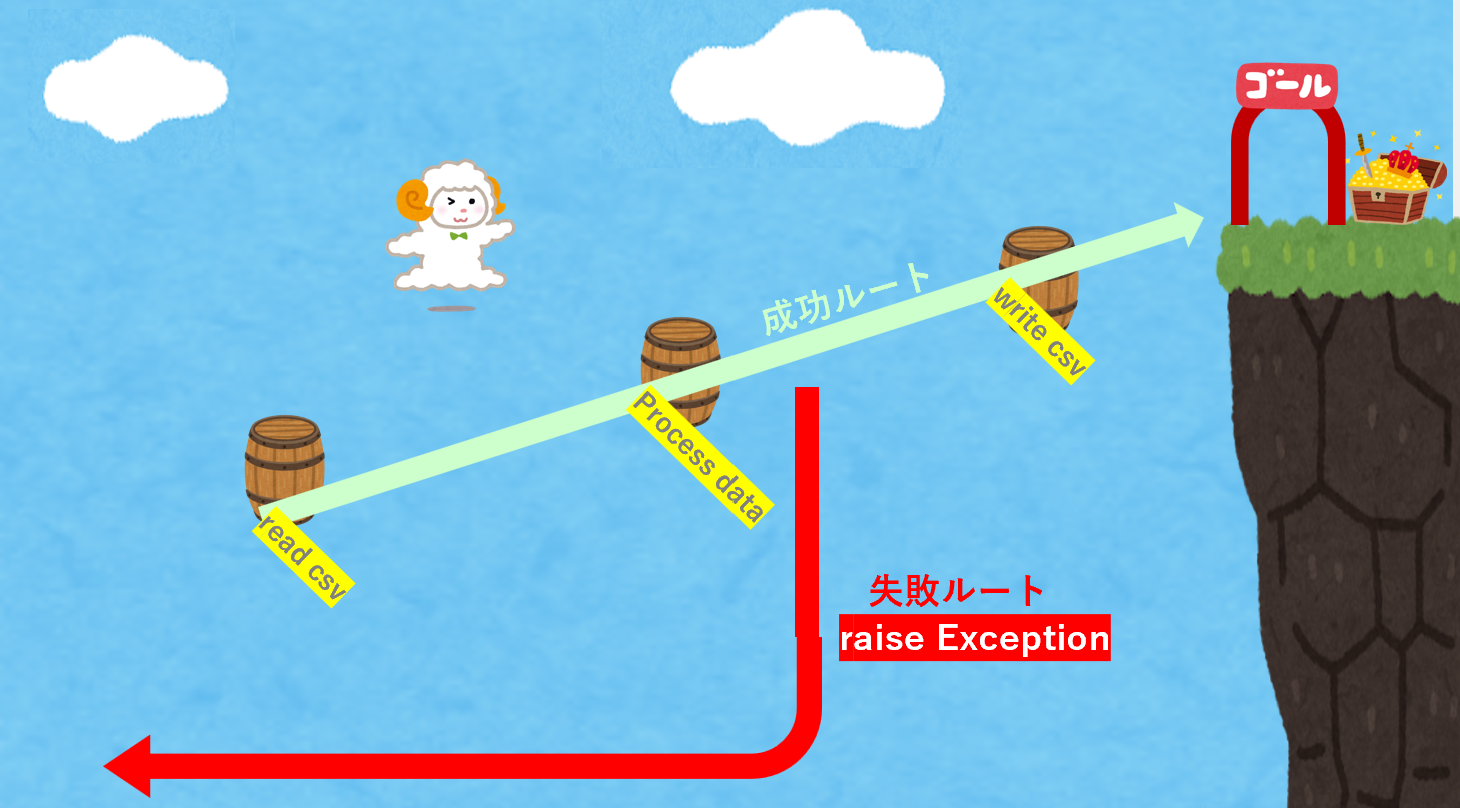
Python的には、エラーがraiseされたタイミングで、現在の処理はスタックを巻き戻しながらtry-exceptを探します。適切なtry-exceptがあれば(中間地点があれば)そちらで処理を継続しますが、なければさらに上の処理に伝播していきます。適切なエラー処理がなければプログラムは落ちるか別のフレームワークに処理が移行します(ゲーム開始画面へ、、南無)。raiseの場合はエラーが発生した場合どこで最終的に止まるのか、ないし、影響範囲の特定がコードを追わなければならず処理が複雑になればなるほどこの把握にはコストがかかります。
安全な失敗(Resultモナド)
これに対して次のジャンプステージはどうでしょうか。

連続ジャンプが成功したなら成功ゴールにいけますが、失敗したとしても奈落に落ちずヒツジちゃんは保護されて下のゴールに入れます。Resultでエラーハンドリングするということもこれと似たようことです。準備してある関数を連続で成功したら正常に(ハッピーパスとして)処理されて、一度でも失敗したら下の適切に処理された失敗ルートに入って上には上がれません。しかし、どこで失敗したのか明らかで、かつ、失敗したとしても安全なルートが用意されています。
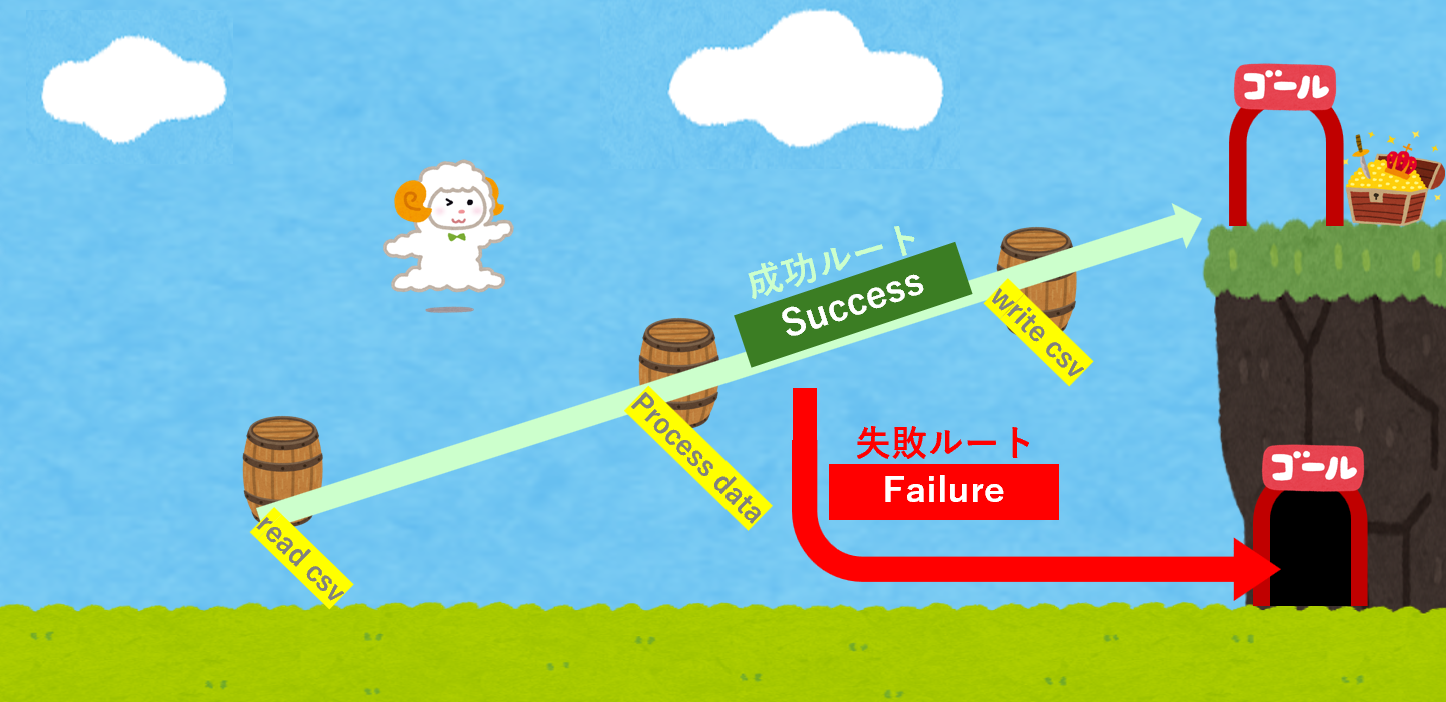
先の3つの関数の返り値をreturnsのResultモナドでラップします。Resultの左の型が成功パターンで右の型が失敗パターンということだけ念頭においておいてください。例えば、Result[int, FileNotFoundError]であればintは成功時の返り値で、FileNotFoundErrorは失敗時の返り値です。
import csv
from returns.result import Failure, Result, Success
def read_csv(file_path: str) -> Result[list[list[str]], FileNotFoundError]:
"""CSVファイルをリストとして読み込む"""
try:
with open(file_path, encoding="utf-8") as f:
return Success(list(csv.reader(f)))
except FileNotFoundError:
return Failure(FileNotFoundError(f"'{file_path}' が見つかりませんでした。"))
def process_data(data: list[list[str]], divisor: int) -> Result[list[list[str]], ZeroDivisionError]:
"""左上の値を指定の数値で割る"""
try:
for row in data:
division = float(row[0]) / divisor
row[0] = str(division)
except ZeroDivisionError:
return Failure(ZeroDivisionError("ゼロ除算禁止!"))
return Success(data)
def write_csv(data: list[list[str]], file_path: str) -> Result[None, PermissionError]:
"""データをCSVに保存する"""
try:
with open(file_path, "w", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(data)
print(f"処理が完了しました。ファイル '{file_path}' に保存されました。")
return Success(None)
except PermissionError:
return Failure(PermissionError(f"'{file_path}'にアクセスできません。"))
この関数をdo記法というResultモナドを結合する記法でつなげたものです。これはまるでヒツジちゃんが浮きタルを飛んでるように、forがある行がヒツジちゃんのブロックのように成功と不成功判定があり、成功すればつぎに進んで、失敗した場合はそのまま失敗ゴールに進みます。
if __name__ == "__main__":
file_path = "budget.csv"
divisor = 2
a = Result.do(
outcome
for data in read_csv(file_path)
for data_rev in process_data(data, divisor)
for outcome in write_csv(data_rev, file_path)
)
print(a)
raise Exceptionとなにがちがうのか
成功パターンに関しては処理に違いはなく、失敗パターンに関しても「正常な処理を途中でストップさせる」という点だけを見れば、raise Exception も Result.Failure も似たように成功ルートにこれ以上進まない動きになります。ただし、それでもResultと、Exceptionを投げる方法では次のような違いがあり、それがコードの可読性・保守性・テスト容易性に大きな違いが現れます。
1. エラーの箇所が明確になる
通常の例外処理では、関数がどこで失敗したのかを知るためにスタックトレースをたどる必要があります。一方、Resultは、関数ごとに成功パターンと失敗パターンを戻り値として明記するため、どの関数からFailureが返されたのか把握が容易です。また、エラー箇所が明確、つまり、Failureが返るタイミングで明確に失敗ルートが分岐するため、失敗時の処理を制御しやすいという利点もあります。それにより、raise Exceptionの場合は想定外の例外が上位の処理に伝播してしまうリスクがありますが、このリスクが低減されます。
2. 型シグネチャにエラーケースを明示できる
Resultモナドによるエラーハンドリングのメリットとして重要なのはエラーが型に明示できるということです。つまり、通常のPythonの返り値には、例外は関数の型シグニチャに「この関数はエラーを投げうる」という情報が現れないため、実装と呼び出し側の間に齟齬が生まれるリスクがあります。3
3. エラーハンドリング漏れが明白になる
エラーハンドリングされていないケースでエラーが出た場合、Failureに包まれておらずPythonのスタックトレースが表示されます。つまり、Resultでエラーを包むことを厳密化しているのであれば、型に書かれたエラーケースは把握され制御されたエラーといえ、逆に型に書かれていないケースはエラーハンドリング漏れということであり、コードで書き足す必要があるということになります。
4. テスト設計の容易さ
型シグネチャにエラーケースが明示されているということは、ユニットテスト設計時にそのエラーを出力させるようなケースを書いてやればいいということです。つまり、関数の型で関数の仕様が明らかになります。生成AIにユニットテストを生成させる場合も、このケースを作ってと明確な指示を与えられテストケース生成を想定しているケースに制御できます。
注意点
その場で処理を止めるべき、致命的なエラー(メモリ不足やネットワーク断線)には、Resultでラップしない方が良い場合もあります。どれが致命的なケースに該当するのか、つまりリカバーするべきでないエラーなのかはチーム内での認識合わせする必要があります。
-
プログラミングの関数と書いているのは、これが数学的な純粋な関数とは区別されるべきものだからです。数学的な関数であれば失敗という概念はありません。仮にそれがあったとしたら関数の定義に失敗しています。Resultモナドを導入するとコーダーは常に関数の純粋性、不純性を意識する必要があります。純粋関数と不純な関数については別の記事(Part3 純粋関数)で解説しています。 ↩
-
エラーケースをどのように明記するかは悩ましい問題です。
#1(エラーを列挙): def hoge()->Result[int, ValueError | ZeroDivisionError | NetworkError]:
この方法は、鉄道指向プログラミングの解説スライドの24ページでは、"maybe too specific"と書かれていますが、関数の仕様を明確にするという意味では有用な方法と考えています。ただし、エラーコードやstatus_codeは書くことがでません。
#2(エラーを統一) def hoge()->Result[int, HTTPExceptoin]:
私のチームではwebフレームワークのfastapiでAPI構築しているため、基本的にエラーは最終的にHTTPExceptionクラスに変換する必要があります。なので、最初からすべてのエラーはHTTPExceptionにしてしまうという考えです。status_codeとdeltailプロパティにエラーコードも記入できるためエラーハンドリングを書くその場で詳細もかけます。チーム内の導入として最初はこれが受け入れられやすいと思います。ただ#1のようにエラーの区別を型に書くことはできません。またオニオンアーキテクチャの場合domain層でHTTPExceptionを使っていいのかというアーキテクチャの設計思想との衝突も起こり得ます。
#3(dictでエラーメッセージ追加) def hoge()->Result[int, dict[str, ValueError | ZeroDivisionError]]:
#1の欠点、つまり、エラーコードや詳細を書けないという点をdictやtupleにして補ったものです。ただ型が見苦しくなり、可読性と保守性が低下します。
#4(独自エラー) def hoge()->Result[int, MyValueError | MyZeroDivisionError | MyNetworkError]:
#1の欠点、つまり、エラーコードや詳細を書けないという点を独自エラーを定義して補ったものです。例えば、Exceptionクラスを継承してdetailやstatus_codeを付け加えてあげればいいでしょう。これでエラークラスとスタックトレースと独自エラーコードを記録できます。ただし、独自クラスを実装する手間が発生しますのでその点がトレードオフになります。
まとめ他にも、いろいろ考えられますが型シグネチャにエラークラスを書き、付加情報を与え、オニオンアーキテクチャのアンチパターンを回避するのであれば#4のエラー記述が理想的です。しかし、実運用を考えると記述が容易な#2が導入としては向いています。したがって、#2のように統一的なエラー表記から段階的に#4に移行するといった方策が妥当と思われます。 ↩