こちらは鈴鹿高専Advent Calendar 2023 6日目の記事です。
目次
はじめに
この記事は5日に投稿したクライアント編の続編的な扱いです。鈴鹿高専のカリキュラムの創造工学で開発をした仮想空間の、リアルタイム通信を支えるサーバーサイドとインフラの話をしていきます。
なお創造工学はチーム開発でしたが、サーバーとインフラは私が全てを1人で実装しました。
Tech Stack
- .NET7 (C#)
- UniTask
- MastarMemory (CySharp .inc)
- MySQL
- Docker Compose ( デバッグ用 )
- Google Kubernetes Engine ( 本番環境 )
本当はRedisも使用予定でしたが諸事情(後述)により使えませんでした。
1. 仕様策定
企画に関してはクライアント編で書いているので省きまして、まずは仕様策定からです。
まずサーバーが持たないといけない機能として
- マッチメイキング ( ルーム入室処理 )
- ルームを考慮したデータ転送
- ユーザーデータ管理
があります。
そして具体的な目標として
- 4000人弱が秒間30回送っても耐えられる
- 遅延は無ければ無いだけ良い
が挙げられます。
一つ目に関して、12000[req/sec]に耐えれば良いので安全マージンを考えて16000程度を目標としました。
二つ目に関しては具体的な数字がないので難しいですが、とりあえずプレイしていて気にならない程度の遅延にすることとしました。
これらの機能と目標からasync awaitを用いた非同期処理で大部分を書き、データ管理に関してはMySQLで元のデータを管理しつつMasterMemoryを使いサーバープログラムでキャッシュするように決めました。
また、非同期処理で複数プロセスで実行したとしても処理の重さによっては捌ききれない可能性があります。そのためサーバープログラムを複数実行してロードバランサーを挟んだインフラ構成にすることを検討し、実際にそのようにしました。
2. 設計-実装
サーバーとインフラの仕様がある程度決まったので設計・実装していきます。本来であれば仕様が完全に確定してから始めるのが良いのですが、今回は私一人で開発することになっていて自由度が高かったので大まかな仕様策定で済ませています。
サーバー側
サーバーでは持たなければならない機能毎にモジュール(クラス)を作り、サーバーのメインプロセスから実行するようにしています。
またキャッシングも含めたDBに関してはControllerクラスやMasterMemoryDBを管理するクラスを作り、各モジュールからクエリを直接叩くことの無いようにしています。そしてこれらのDB関連の処理はMasterMemoryはゼロアロケーションのため同期処理、それ以外のDBに関しては非同期処理で実装しました。
async awaitの非同期処理を実装するときC#標準のTaskを用いる場合が多いですが、今回はクライアントで先に採用していたUniTaskをサーバーでも採用しています。UniTaskについては主要な機能はTaskとほぼ同じなので説明は省きます。
マッチメイキング処理
マッチメイキング処理では共有資源を同時に触ったときにバグが発生する可能性があります。その理由と解決した方法について書いていきます。
まずマッチメイキングでは
- 入室リクエストを受信
- 参加人数が最少のルームを検索
- 空いているユーザーIDの中で最小のものを探す
→参加人数上限などで空きが無い場合は(論理的に)ルームを作りユーザーID:1とする - リクエストしたユーザーへIDを割り当て & DBへユーザーデータを保存
以上の処理をしています。ここでもし同時に同時にリクエストを受信した場合を考えてみましょう。
まず仕様からデータはMySQLに保存するようにしていますので2~4の過程で何らかのクエリを叩くことになります。MySQLの処理時間はレコード数が少ない場合は短いですし、C#の非同期処理でも同時に非同期処理オブジェクトを作ろうとしてもメモリ確保やその他の影響で時間差が出ますので、検索や保存を同時にする可能性が低くトラブルになることは低確率だと考えられます。
しかしレコード数が増えた場合、MySQLのクエリを処理する時間が遅くなるので検索と保存を別プロセスで並行して行う可能性があります。これにより複数ユーザーに同じユーザーIDが割り振られてしまうトラブルが起こる可能性があり、実際にpythonで0.1秒に120回ほどリクエストを送ってみると見事にバグりました。
これらよりまずやらないといけないことは、2~4のいわゆるクリティカルセクションと呼ばれるところを排他制御することです。色々な方法が考えられますが今回は処理中フラグを作り、フラグが立っていないときだけ処理を進められるようにしました。
データ転送処理
ここでのデータ転送処理を簡単に説明すると、受信したデータのヘッダからユーザーIDとルームIDを確認して同じルームのユーザーへ転送することです。
つまり同じルームのユーザーを取得しないといけないためDBを参照するわけですが、こちらはマッチメイキング処理とは違いDBに対して登録・更新する処理がないため同時に触ってもDBのデータに不整合が無い限りはバグは発生しません。しかしデータを取得する際にレコード数が多ければ時間がかかってしまいリアルタイム性が損なわれる可能性があります。
そこで500ms毎にMySQLをMasterMemoryのインメモリDBにキャッシュするようにし、データ転送ではインメモリDBで検索をするようにしています。またMasterMemoryを使うためにはデータ構造をクラスとして定義しないといけませんが、MySQLのORMでもそのクラスを使うようにすることでメンテナンスを楽にしています。
ユーザーデータ管理
ユーザーデータ管理が必要な理由ですが、例えばユーザーがルームへ参加した際に毎回各ユーザーが自分自身のデータを送信していては極めて非効率だからです。一回送信したデータをサーバーで保持することにより入室処理でのトータルの処理時間を減らすことができます。またこれ以外にもユーザーとの通信が生きているかも把握できるため、コネクション切断時にどういう処理をするか、を定義できるようにもなります。
これまでにも軽く触れましたが、データは全てMySQLに保存してMasterMemoryでキャッシングをしてパフォーマンスの向上を図っています。
インフラ側
インフラではサーバーアプリケーションを複数起動して負荷分散させたり良い感じのDB設計をしたり...など、全体のパフォーマンスが落ちることの無いように気をつけながら、かつ簡単に再現できるように構築をしていきました。
データベース設計
まずはデータベースに関してです。これはサーバー側の節で書くべきか悩みましたが、そうするとインフラの節がスカスカになってしまうのでこっちに書きます。
まず管理しなければならないデータとして
- ユーザーのエンドポイント ( IPAddresss, Port )
- ユーザー情報
- ユーザーID
- ルームID
- VRoidモデルID
- ディスプレイネーム
- ルーム情報
- (存在している)ルームID
- ルームタイプ
- ロビー
- ミニゲーム
が考えられました。これらを管理するためのテーブルは以下のSQLファイルのようになりました。
CREATE DATABASE IF NOT EXISTS `serverApp`;
USE `serverApp`;
CREATE TABLE IF NOT EXISTS `RoomType` (
`TypeID` TINYINT NOT NULL,
`TypeDetail` VARCHAR(255) NOT NULL,
PRIMARY KEY (`TypeID`)
);
CREATE TABLE IF NOT EXISTS `Room` (
`RoomID` TINYINT NOT NULL AUTO_INCREMENT,
`RoomType` TINYINT NOT NULL,
FOREIGN KEY (`RoomType`) REFERENCES `RoomType`(`TypeID`),
PRIMARY KEY (`RoomID`)
);
CREATE TABLE IF NOT EXISTS `User` (
`UserID` TINYINT NOT NULL,
`RoomID` TINYINT NOT NULL,
FOREIGN KEY (`RoomID`) REFERENCES `Room`(`RoomID`),
`ModelID` TEXT NOT NULL,
`DisplayName` TEXT NOT NULL,
`IPAddress` TEXT NOT NULL,
`Port` SMALLINT UNSIGNED NOT NULL,
PRIMARY KEY (`UserID`, `RoomID`)
);
INSERT IGNORE INTO `RoomType` (`TypeID`, `TypeDetail`) VALUES (0, 'Lobby');
INSERT IGNORE INTO `RoomType` (`TypeID`, `TypeDetail`) VALUES (1, 'Race');
NOT NULL制約や外部キー制約などサーバーアプリケーションで処理中に例外が発生したりデータの不整合が発生しないように気をつけてみました。今改めて見ると主キー制約を付けた属性にはNOT NULL制約は必要ないですね。
今回はこのテーブルで問題なくできましたが、例えばルーム数が多くなってしまった場合などより大規模なシステムを考える際は、ルーム周りの構造を見直す必要があるかなと思います。しかし今回はルームの最大数を126にしているのでこれで問題ないです。
開発環境構築
開発中にクライアントとサーバーを結合してテストしたい場合がたくさんあります。そのためサーバーサイドのインフラ構築からアプリケーション起動までを簡単にできるよう、dockerファイルやdocker composeのファイルを作成して配布しました。なお、今回サーバーサイドは.NET7アプリケーションのため.NET coreが動く環境であればCPUアーキテクチャは問わないようになっています。
ビルド用Dockerファイル
FROM mcr.microsoft.com/dotnet/sdk:7.0 AS build-env
WORKDIR /server_app
COPY . .
RUN dotnet restore ./server_app
RUN dotnet publish -c Release -o out ./server_app
FROM mcr.microsoft.com/dotnet/runtime:7.0
WORKDIR /server_app
COPY --from=build-env /server_app/out .
ENTRYPOINT ["dotnet", "server_app.dll"]
docker composeファイル
version: '3'
services:
redis:
image: redis:alpine
restart: always
ports:
- "6379:6379"
volumes:
- "./data/redis:/data"
networks:
server-network:
ipv4_address:
10.254.0.100
mysql:
image: mysql:latest
restart: always
ports:
- "3306:3306"
volumes:
- "./data/mysql:/var/lib/mysql"
- "./MySQL:/docker-entrypoint-initdb.d"
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: serverApp
MYSQL_USER: hogehoge
MYSQL_PASSWORD: fugafuga
networks:
server-network:
ipv4_address:
10.254.0.200
server:
build:
context: .
dockerfile: Dockerfile
restart: always
ports:
- "5000:5000/udp"
depends_on:
- redis
- mysql
environment:
REDIS_HOST: 10.254.0.100
MYSQL_HOST: 10.254.0.200
networks:
server-network:
ipv4_address:
10.254.0.11
networks:
server-network:
ipam:
driver: default
config:
- subnet: 10.254.0.0/16
このdocker composeにあるRedisのコンテナは使おうとしたために書いていますが、本番では使えなかったので使用用途についてはおまけの節で書きます。
init.sqlをMySQLコンテナの/docker-entrypoint-initdb.dに入るようにアタッチすることで、起動時に自動的にsqlファイルが実行されるようにしています。これによりインフラやサーバーの知識がない人でもdocker compose upを叩くだけで動くサーバーを立てることができるようになっています。
デプロイ環境構築
本番環境はGoogle Cloud Platformを使い、サーバーアプリケーションの実行と負荷分散にGKE(Google Kubernetes Engine), MySQLにCloud SQLを使いました。Redisに関してはMemorystoreを使おうとしましたがGKEでデプロイしたアプリケーションからそのままでは触れず、解決する時間が無かったため諦めました。また、VPCネットワークを適切に使いGKEの5000ポートのみが外から見えるようにしてMySQLはVPC内のみから触れるようにしています。
GCPでの環境構築に関しては実際にコンソールを触ってもらわないと分からないところが多く、私もその場その場で調べながら構築したので気になる方は無料枠を使って実験してみると楽しいと思います。ここでは構築方法については省きます。
3. おまけ
以上でサーバー/インフラ編の真面目な部分が終わりで、ここからはおまけを書いていきます。
Redisの使用用途
本番で使えなかったRedisですが、これは各ユーザーの最終受信時刻を保存しておき、死んだユーザーを削除するために使おうとしていました。具体的には各ユーザーはroomIDとuserIDの組み合わせで一意に定まるので、これをkeyとして時刻を保存していくことです。MySQLでやっても問題は無さそうですが、最大12000回/秒で書き込みをして高頻度で読み取りをするのはHDDやSSDなどのストレージが可哀想と思ったのでRedisを使おうとしました。実際この処理は上手く動作して、docker composeで起動した際には指定した時間だけ更新がなかった場合に自動的にルームから退出されるようにしています。
本番環境のMySQLが壊れた!
Cloud SQLは開発環境用の構成でも99.95%の可用性を謳っています。そのため創造工学程度の運用が短いプロジェクトなら本番環境用の構成じゃなくても良いだろう、と考えました。しかし本番にデプロイをして半日経ったくらいに、なんと早速0.05%を引いてしまうのです!そしてこれに気付いたのが深夜3時でした。始めはまさかMySQLが壊れるなんて思いもせず、サーバーのバグなのではと考えて原因を探っていきました。しかし見つからないためログをじっくりと呼んでいくと「DBが見つからない」のメッセージが...急いでinit.sqlを流し込んで初期化して動作チェックをしました。直りました。これを教訓に動いたのを確認した後で本番環境用の構成に変更しました。そして対応が終わった後、寝る暇なく登校して授業を受けました。大変気持ちの良い睡眠時間となりました。
また、構成を変更したことにより料金が2倍ほどになりました。大体1000円/日くらいです。
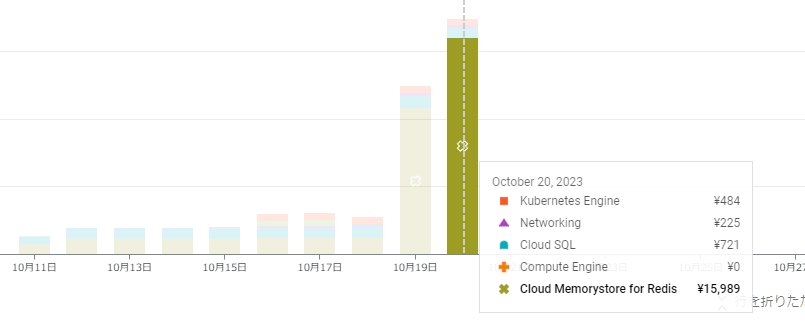
GCPのRedisで無料クレジット全消滅
Memorystore for Redisですが、始めはMySQLのように開発環境の構成で接続の実験をしていました。しかし先のトラブルにより実際に稼働させる前に冗長化しないとマズイのでは、ということでサーバーアプリケーションをRedis対応した後に構成を変更しました。しかし、この変更時にとんでもないミスを犯し、なんと一日で1.5万円ほどを消費していました。300$無料クレジットがありましたが簡単に食いつぶし、無事に全てのシステムが停止しました。最終的にはRedisの接続が上手くできないことなどもあり、インスタンスを立てないという選択肢を取りましたが流石に焦りました。
感想など
今回のサーバー/インフラ開発で初めて本格的なものを1人で2ヶ月ほどで作り上げましたが、技術的に成長できたり1人だからこそ好きなように技術選定をしてチャレンジできたので楽しかったです。ネットワークやDB周りに関しては、趣味で家にサーバーを2台置いたりルーターを置いてネットワークで遊んでいたりしたのもあって困ることはほぼほぼ無かったです。やはり普段から技術で遊んでおくのはいざという時に役立ちますね。